2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Papieradresse:https://arxiv.org/pdf/2403.10506
Humanoide Roboter haben ein menschenähnliches Aussehen und sollen Menschen in einer Vielzahl von Umgebungen und Aufgaben unterstützen. Allerdings stellt die teure und fragile Hardware eine Herausforderung für diese Forschung dar. Daher wurde in dieser Studie HumanoidBench unter Verwendung fortschrittlicher Simulationstechnologie entwickelt. Dieser Benchmark bewertet die Leistung verschiedener Algorithmen mithilfe humanoider Roboter, einschließlich einer Vielzahl von Aufgaben wie geschickter bimanueller und komplexer Ganzkörpermanipulation.Forschungsergebnisse zeigen, dass die fortschrittlichstenVerstärkungslernalgorithmus Bei vielen Aufgaben hat es Schwierigkeiten, während hierarchische Lernalgorithmen bei grundlegenden Aktionen wie Gehen und Berühren von Objekten eine bessere Leistung erbringen. HumanoidBench ist ein wichtiges Tool für die Robotik-Community zur Bewältigung der Herausforderungen, mit denen humanoide Roboter konfrontiert sind, und bietet eine Plattform für die schnelle Verifizierung von Algorithmen und Ideen.
Von humanoiden Robotern wird erwartet, dass sie sich nahtlos in unser tägliches Leben integrieren. Ihre Steuerungen werden jedoch manuell für bestimmte Aufgaben entwickelt und neue Aufgaben erfordern umfangreiche Engineering-Arbeiten. Um dieses Problem anzugehen, haben wir einen Benchmark namens HumanoidBench entwickelt, um das Lernen humanoider Roboter zu erleichtern. Dies bringt eine Reihe von Herausforderungen mit sich, darunter komplexe Steuerungen, körperliche Koordination und langfristige Aufgaben.Bei dieser Plattform handelt es sich um einen TestroboterLernalgorithmus Bietet eine sichere, kostengünstige Umgebung und enthält eine Vielzahl von Aufgaben im Zusammenhang mit alltäglichen menschlichen Aufgaben. HumanoidBench kann problemlos eine Vielzahl humanoider Roboter und Endeffektoren, 15 Ganzkörpermanipulationsaufgaben und 12 Fortbewegungsaufgaben integrieren. Dies ermöglicht es hochmodernen RL-Algorithmen, die komplexe Dynamik humanoider Roboter zu steuern, und gibt eine Richtung für zukünftige Forschung vor.
Deep Reinforcement Learning (RL) schreitet mit dem Aufkommen standardisierter Simulationsbenchmarks rasch voran. Bestehende Simulationsumgebungen für Roboteroperationen konzentrieren sich jedoch hauptsächlich auf statische, kurzfristige Fähigkeiten und beinhalten keine komplexen Operationen. Im Gegensatz dazu konzentrieren sich die vorgeschlagenen Benchmarks auf verschiedene langfristige Operationen. Die meisten Benchmarks sind jedoch für bestimmte Aufgaben konzipiert und viele verwenden vereinfachte Modelle. Hierzu sind synthetische Benchmarks auf Basis realer Hardware erforderlich.
Der wichtigste Roboteragent ist ein humanoider Unitree H1-Roboter mit zwei geschickten Schattenhänden2. Der Roboter wird durch MuJoCo simuliert. Die simulierte Umgebung unterstützt eine Reihe von Beobachtungen, darunter Roboterstatus, Objektstatus, visuelle Beobachtungen und Ganzkörper-Tasterfassung. Auch humanoide Roboter können über eine Lageregelung gesteuert werden.
Um menschenähnliche Aufgaben ausführen zu können, muss ein Roboter in der Lage sein, seine Umgebung zu verstehen und entsprechende Maßnahmen zu ergreifen. Allerdings ist es aus Kosten- und Sicherheitsgründen schwierig, Roboter in der realen Welt zu testen. Daher sind Simulationsumgebungen wichtige Werkzeuge zum Lernen und Steuern von Robotern.
HumanoidBench umfasst 27 Aufgaben mit einem hochdimensionalen Bewegungsraum (bis zu 61 Aktoren). Zu den motorischen Aufgaben zählen Grundbewegungen wie Gehen und Laufen. Zu den Manipulationsaufgaben zählen fortgeschrittene Aufgaben wie das Schieben, Ziehen, Heben und Greifen von Gegenständen.

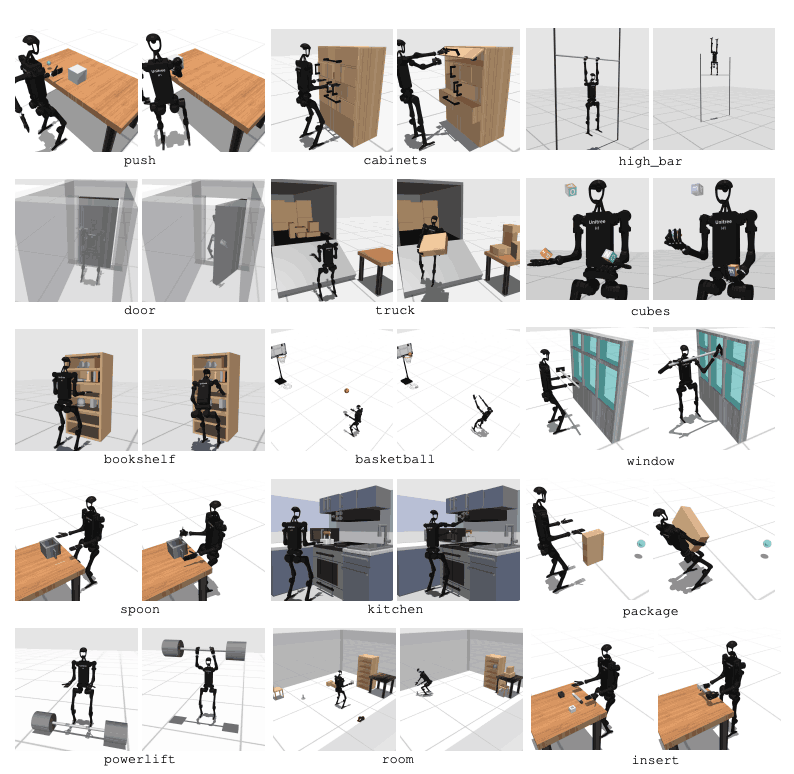
Der Zweck des Benchmarks besteht darin, zu bewerten, wie gut moderne Algorithmen diese Aufgaben erfüllen können. Der Roboter muss den Zustand der Umgebung beobachten und entsprechend geeignete Maßnahmen auswählen. Durch die Belohnungsfunktion kann der Roboter die beste Strategie zur Ausführung der Aufgabe erlernen.
Beispielsweise muss der Roboter bei einer Gehaufgabe seine Vorwärtsgeschwindigkeit beibehalten, ohne umzufallen. Die Optimierung von Gleichgewicht und Gang ist bei dieser Art von Aufgabe sehr wichtig. Bei Manipulationsaufgaben hingegen muss der Roboter Objekte präzise manipulieren. Dies erfordert Kenntnisse über die Position und Ausrichtung des Objekts sowie eine entsprechende Kraftsteuerung.
Das Ziel von HumanoidBench ist es, das Gebiet des Roboterlernens und der Robotersteuerung durch diese Aufgaben voranzutreiben. Mithilfe simulierter Umgebungen können Forscher Experimente sicher durchführen und die Roboterleistung in vielen verschiedenen Szenarien bewerten. Dies wird dazu beitragen, bessere Steuerungsalgorithmen und Lernmethoden zu entwickeln und so den zukünftigen Einsatz humanoider Roboter in der realen Welt zu fördern.
Die Leistung von Reinforcement Learning (RL)-Algorithmen wird bewertet, um Herausforderungen zu identifizieren, mit denen humanoide Roboter bei Lernaufgaben konfrontiert sind. Zu diesem Zweck werden vier Hauptmethoden des verstärkenden Lernens verwendet, darunter DreamerV3, TD-MPC2, SAC und PPO. Die Ergebnisse zeigen, dass die Leistung des Basisalgorithmus bei vielen Aufgaben unterhalb der Erfolgsschwelle liegt.
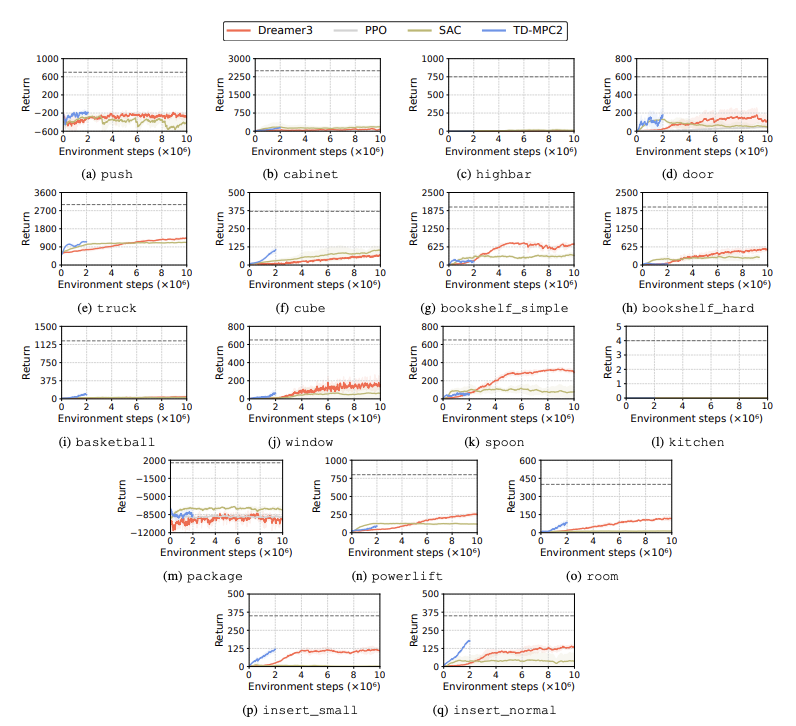
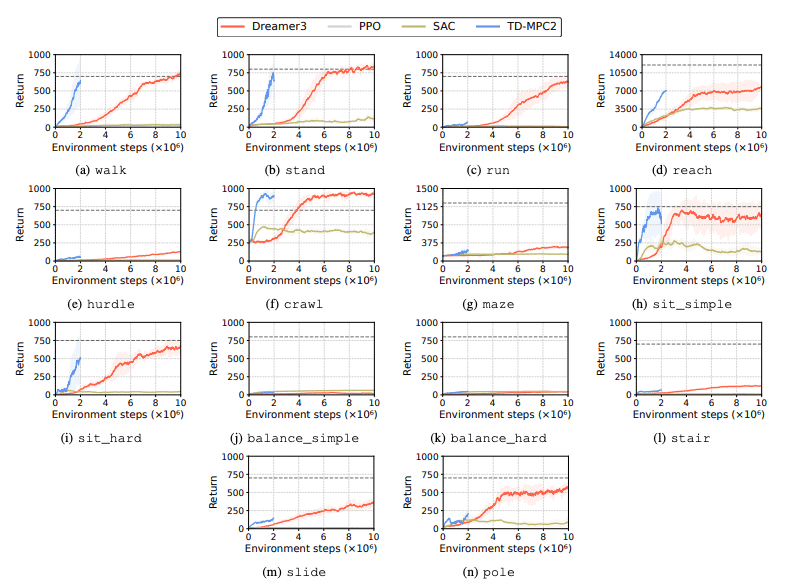
Insbesondere haben aktuelle RL-Algorithmen Schwierigkeiten, hochdimensionale Aktionsräume und komplexe Aufgaben zu bewältigen. Vor allem humanoide Roboter haben Schwierigkeiten, Aufgaben auszuführen, die geschickte Hände und eine komplexe Körperkoordination erfordern. Darüber hinaus sind Manipulationsaufgaben auch besonders anspruchsvoll und oft mit geringeren Belohnungen verbunden.
Ein häufiger Fehler besteht darin, dass humanoide Benchmarks Schwierigkeiten haben, das erwartete Verhalten von Robotern bei Aufgaben wie hohen Hürden, Toren und Hindernissen zu lernen. Dies liegt daran, dass es schwierig ist, Strategien zu finden, die zu komplexen Verhaltensweisen passen.
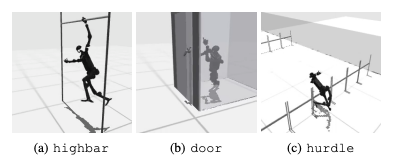
Um diesen Herausforderungen zu begegnen, wird ein hierarchischer RL-Ansatz in Betracht gezogen. Das Training von Fähigkeiten auf niedrigem Niveau und deren Kombination mit Planungsstrategien auf hohem Niveau kann die Lösung von Aufgaben erleichtern. Allerdings gibt es beim aktuellen Algorithmus noch Raum für Verbesserungen.
Diese Forschung stellt einen hochdimensionalen Humanoiden namens HumanoidBench vorRobotersteuerung Benchmark. Dieser Benchmark bietet eine umfassende humanoide Umgebung, die eine Vielzahl von Fortbewegungs- und Manipulationsaufgaben von Spielzeug bis hin zu realen Anwendungen umfasst. Die Autoren des Papiers hoffen, dass es solch komplexe Aufgaben bewältigen und die Entwicklung von Ganzkörperalgorithmen für humanoide Roboter fördern kann.
In zukünftigen Studien wird es wichtig sein, die Wechselwirkungen zwischen verschiedenen Wahrnehmungsmodalitäten zu untersuchen. Darüber hinaus wird darüber nachgedacht, realistischere Objekte und Umgebungen mit realer Vielfalt und hochwertiger Darstellung zu kombinieren. Darüber hinaus wird ein Schwerpunkt auf anderen Mitteln zur Förderung des Lernens in Umgebungen liegen, in denen es schwierig ist, physische Demonstrationen zu sammeln.

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen
