моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Бумажный адрес:https://arxiv.org/pdf/2403.10506
Роботы-гуманоиды имеют человекоподобный внешний вид и, как ожидается, будут поддерживать людей в различных средах и задачах. Однако дорогое и хрупкое оборудование является проблемой для этого исследования. Поэтому в этом исследовании HumanoidBench был разработан с использованием передовой технологии моделирования. В этом тесте оценивается производительность различных алгоритмов, использующих роботов-гуманоидов, включая различные задачи, такие как ловкие бимануальные действия и сложные манипуляции всем телом.Результаты исследований показывают, что самые передовыеалгоритм обучения с подкреплением Он плохо справляется со многими задачами, в то время как иерархические алгоритмы обучения лучше справляются с базовыми действиями, такими как ходьба и прикосновение к объектам. HumanoidBench — важный инструмент сообщества робототехники для решения проблем, с которыми сталкиваются роботы-гуманоиды, предоставляющий платформу для быстрой проверки алгоритмов и идей.
Ожидается, что роботы-гуманоиды легко интегрируются в нашу повседневную жизнь. Однако их элементы управления проектируются вручную для конкретных задач, а новые задачи требуют обширной инженерной работы. Чтобы решить эту проблему, мы разработали тест под названием HumanoidBench, который облегчает изучение роботов-гуманоидов. Это включает в себя ряд проблем, включая сложные средства управления, физическую координацию и долгосрочные задачи.Эта платформа представляет собой тестовый роботалгоритм обучения Обеспечивает безопасную и недорогую среду и содержит множество задач, связанных с повседневными задачами человека. HumanoidBench может легко включать в себя различных роботов-гуманоидов и исполнительные органы, 15 задач по манипулированию всем телом и 12 задач по передвижению. Это позволяет современным алгоритмам RL управлять сложной динамикой роботов-гуманоидов и определяет направление для будущих исследований.
Глубокое обучение с подкреплением (RL) быстро развивается с появлением стандартизированных тестов моделирования. Однако существующие среды моделирования работы роботов в основном ориентированы на статические, краткосрочные навыки и не включают в себя сложные операции. Напротив, предложенные контрольные показатели ориентированы на различные долгосрочные операции. Однако большинство тестов предназначены для конкретных задач, и во многих используются упрощенные модели. Для этого необходимы синтетические тесты, основанные на реальном оборудовании.
Главный робот-агент — робот-гуманоид Unitree H1 с двумя ловкими теневыми руками2. Робот моделируется через MuJoCo. Моделируемая среда поддерживает ряд наблюдений, включая состояние робота, состояние объекта, визуальные наблюдения и тактильное зондирование всего тела. Роботами-гуманоидами также можно управлять с помощью позиционного контроля.
Чтобы выполнять задачи, аналогичные человеческим, робот должен понимать окружающую среду и предпринимать соответствующие действия. Однако тестирование роботов в реальном мире затруднено из-за проблем с ценой и безопасностью. Таким образом, среды моделирования являются важными инструментами для обучения и управления роботами.
HumanoidBench включает в себя 27 задач с многомерным пространством движения (до 61 исполнительного механизма). Двигательные задачи включают в себя базовые движения, такие как ходьба и бег. Задачи манипулирования включают в себя сложные задачи, такие как толкание, вытягивание, подъем и захват объектов.

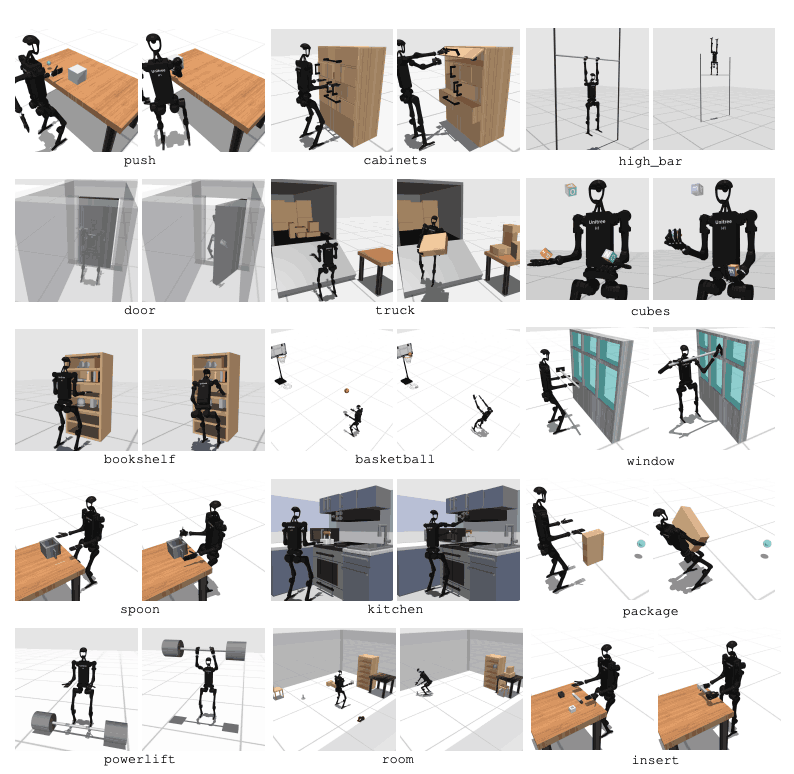
Цель теста — оценить, насколько хорошо современные алгоритмы справляются с этими задачами. Роботу необходимо наблюдать за состоянием окружающей среды и соответственно выбирать соответствующие действия. С помощью функции вознаграждения робот может изучить лучшую стратегию для выполнения задачи.
Например, при ходьбе роботу необходимо поддерживать скорость движения вперед, не падая. Оптимизация баланса и походки очень важна в задачах такого типа. С другой стороны, в задачах манипулирования роботу необходимо точно манипулировать объектами. Это требует знания положения и ориентации объекта, а также соответствующего управления силой.
Цель HumanoidBench — продвигать область роботизированного обучения и управления с помощью этих задач. Используя моделируемую среду, исследователи могут безопасно проводить эксперименты и оценивать производительность роботов в самых разных сценариях. Это поможет разработать более совершенные алгоритмы управления и методы обучения, тем самым способствуя будущему применению человекоподобных роботов в реальном мире.
Производительность алгоритмов обучения с подкреплением (RL) оценивается для выявления проблем, с которыми сталкиваются роботы-гуманоиды при выполнении задач обучения. Для этой цели используются четыре основных метода обучения с подкреплением, включая DreamerV3, TD-MPC2, SAC и PPO. Результаты показывают, что базовый алгоритм выполняет многие задачи ниже порога успеха.
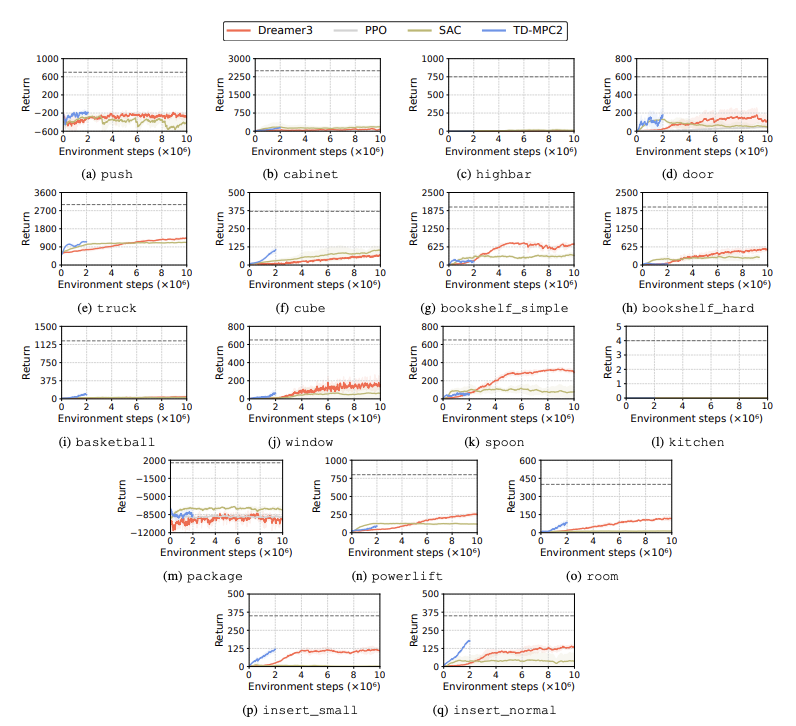
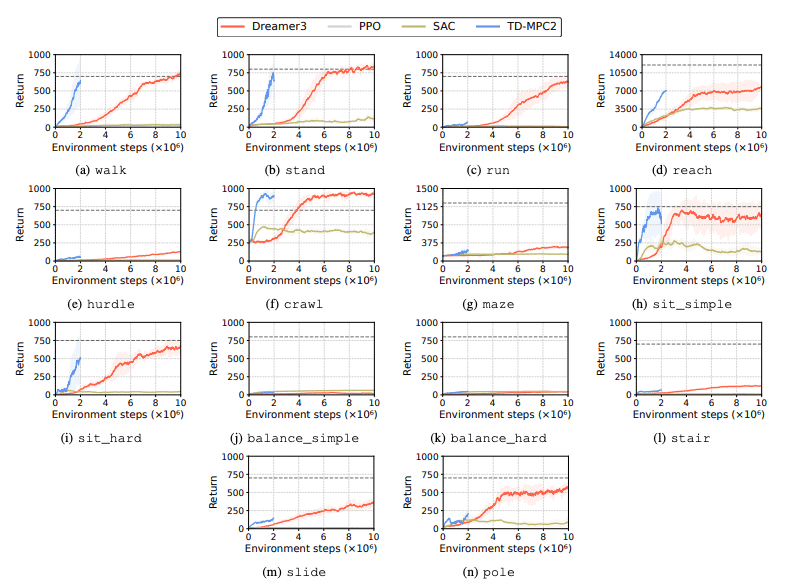
В частности, нынешние алгоритмы RL с трудом справляются с многомерными пространствами действий и сложными задачами. Гуманоидным роботам особенно трудно выполнять задачи, требующие ловких рук и сложной координации тела. В дополнение к этому, задачи манипулирования также особенно сложны и часто требуют меньшего вознаграждения.
Распространенной ошибкой является то, что тесты гуманоидов с трудом изучают ожидаемое поведение роботов в таких задачах, как преодоление высоких препятствий, ворот и препятствий. Это потому, что трудно найти стратегии, которые соответствуют сложному поведению.
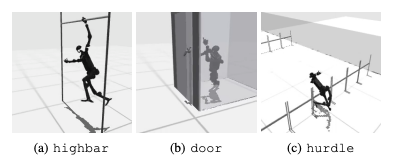
Для решения этих проблем рассматривается иерархический подход RL. Обучение навыкам низкого уровня и объединение их со стратегиями планирования высокого уровня может облегчить решение задач. Однако в текущем алгоритме еще есть возможности для улучшения.
В этом исследовании представлен гуманоид высокого измерения под названием HumanoidBench.Управление роботом эталон. Этот тест обеспечивает комплексную гуманоидную среду, включающую множество задач по передвижению и манипулированию, от игрушек до реальных приложений. Авторы статьи надеются, что она сможет решить столь сложные задачи и способствовать разработке алгоритмов всего тела для роботов-гуманоидов.
В будущих исследованиях будет важно изучить взаимодействие между различными модальностями восприятия. Кроме того, будет рассмотрено сочетание более реалистичных объектов и окружения с разнообразием реального мира и высококачественным рендерингом. Кроме того, упор будет сделан на другие средства стимулирования обучения в условиях, когда сложно собрать физические демонстрации.

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com