minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Endereço do papel:https://arxiv.org/pdf/2403.10506
Os robôs humanóides têm aparência humana e devem apoiar os humanos em uma variedade de ambientes e tarefas. No entanto, hardware caro e frágil é um desafio para esta pesquisa. Portanto, este estudo desenvolveu o HumanoidBench usando tecnologia de simulação avançada. Este benchmark avalia o desempenho de diferentes algoritmos usando robôs humanóides, incluindo uma variedade de tarefas, como manipulação bimanual hábil e manipulação complexa de corpo inteiro.Os resultados da pesquisa mostram que os mais avançadosalgoritmo de aprendizagem por reforço Ele apresenta dificuldades em muitas tarefas, enquanto os algoritmos de aprendizagem hierárquica apresentam melhor desempenho em ações básicas, como caminhar e tocar objetos. O HumanoidBench é uma ferramenta importante para a comunidade robótica enfrentar os desafios enfrentados pelos robôs humanóides, fornecendo uma plataforma para verificação rápida de algoritmos e ideias.
Espera-se que os robôs humanóides se integrem perfeitamente em nossas vidas diárias. No entanto, seus controles são projetados manualmente para tarefas específicas e novas tarefas exigem extenso trabalho de engenharia. Para resolver este problema, desenvolvemos um benchmark chamado HumanoidBench para facilitar o aprendizado de robôs humanóides. Isto envolve uma série de desafios, incluindo controlos complexos, coordenação física e tarefas de longo prazo.Esta plataforma é um robô de testealgoritmo de aprendizagem Fornece um ambiente seguro e barato e contém uma variedade de tarefas relacionadas às tarefas humanas diárias. O HumanoidBench pode incorporar facilmente uma variedade de robôs humanóides e efetores finais, 15 tarefas de manipulação de corpo inteiro e 12 tarefas de locomoção. Isso permite que algoritmos RL de última geração controlem a dinâmica complexa de robôs humanóides e fornece uma direção para pesquisas futuras.
O aprendizado por reforço profundo (RL) está avançando rapidamente com o surgimento de benchmarks de simulação padronizados. No entanto, os ambientes existentes de simulação de operação de robôs concentram-se principalmente em habilidades estáticas e de curto prazo e não envolvem operações complexas. Em contrapartida, os parâmetros de referência propostos centram-se em diversas operações de longo prazo. Contudo, a maioria dos benchmarks são projetados para tarefas específicas e muitos usam modelos simplificados. Isto requer benchmarks sintéticos baseados em hardware real.
O principal agente robótico é um robô humanóide Unitree H1 com duas mãos de sombra hábeis2. O robô é simulado através do MuJoCo. O ambiente simulado suporta uma série de observações, incluindo status do robô, status do objeto, observações visuais e detecção tátil de corpo inteiro. Os robôs humanóides também podem ser controlados através do controle de posição.
Para realizar tarefas semelhantes às dos humanos, um robô deve ser capaz de compreender o seu ambiente e tomar as ações apropriadas. No entanto, testar robôs no mundo real é difícil devido a questões de custo e segurança. Portanto, ambientes de simulação são ferramentas importantes para aprendizado e controle de robôs.
HumanoidBench inclui 27 tarefas com espaço de movimento de alta dimensão (até 61 atuadores). As tarefas motoras incluem movimentos básicos, como caminhar e correr. As tarefas de manipulação incluem tarefas avançadas, como empurrar, puxar, levantar e agarrar objetos.

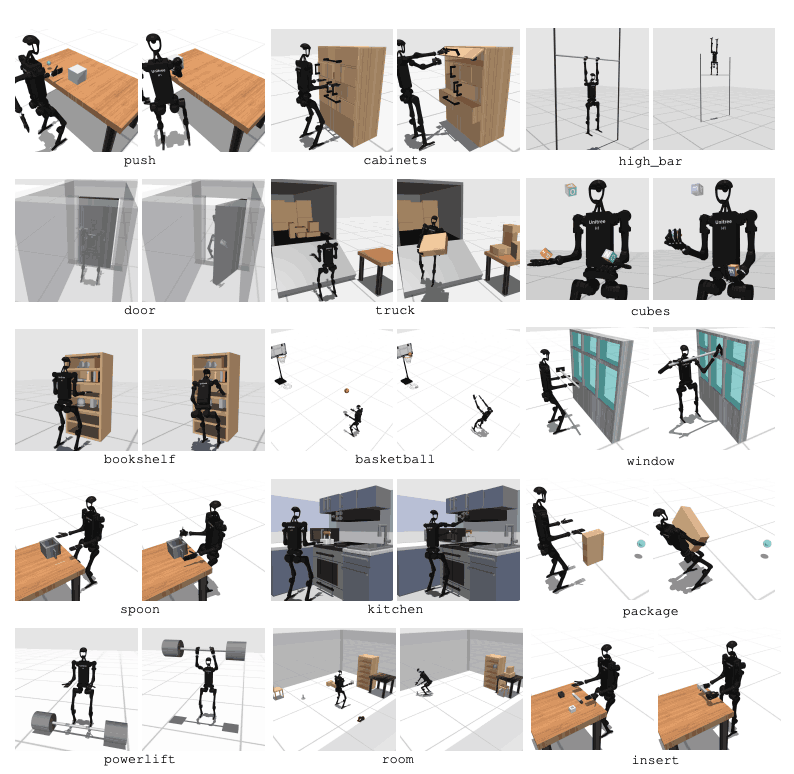
O objetivo do benchmark é avaliar quão bem os algoritmos modernos podem realizar essas tarefas. O robô precisa observar o estado do ambiente e escolher as ações apropriadas de acordo. Através da função de recompensa, o robô pode aprender a melhor estratégia para realizar a tarefa.
Por exemplo, numa tarefa de caminhada, o robô precisa manter a velocidade de avanço sem cair. Otimizar o equilíbrio e a marcha é muito importante neste tipo de tarefa. Por outro lado, em tarefas de manipulação, o robô precisa manipular objetos com precisão. Isto requer conhecimento da posição e orientação do objeto e controle de força apropriado.
O objetivo do HumanoidBench é avançar no campo do aprendizado e controle robótico por meio dessas tarefas. Usando ambientes simulados, os pesquisadores podem conduzir experimentos com segurança e avaliar o desempenho do robô em diversos cenários. Isto ajudará a desenvolver melhores algoritmos de controle e métodos de aprendizagem, promovendo assim a futura aplicação de robôs humanóides no mundo real.
O desempenho de algoritmos de aprendizagem por reforço (RL) é avaliado para identificar desafios enfrentados por robôs humanóides em tarefas de aprendizagem. Quatro métodos principais de aprendizagem por reforço são usados para esse fim, incluindo DreamerV3, TD-MPC2, SAC e PPO. Os resultados mostram que o algoritmo de linha de base tem desempenho abaixo do limite de sucesso em muitas tarefas.
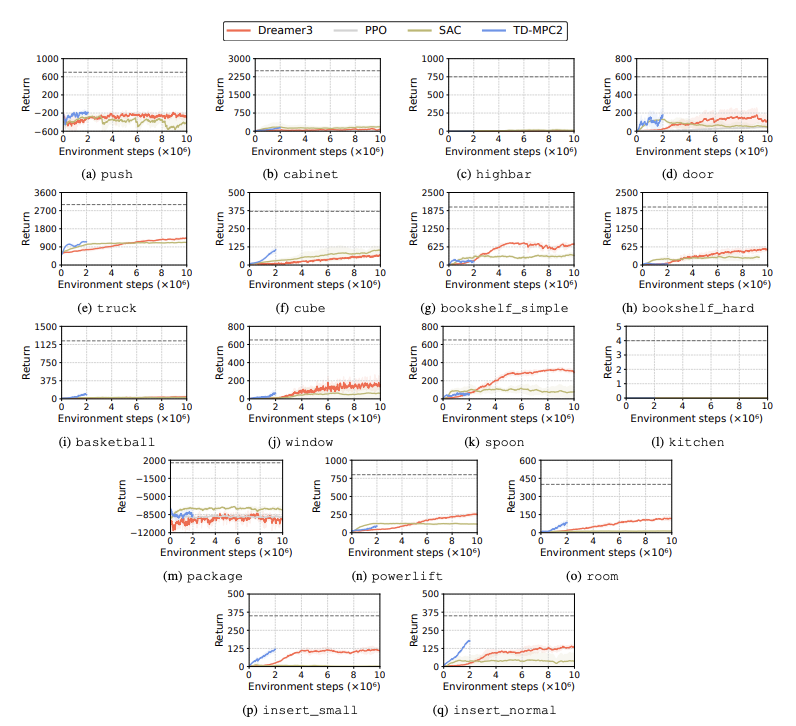
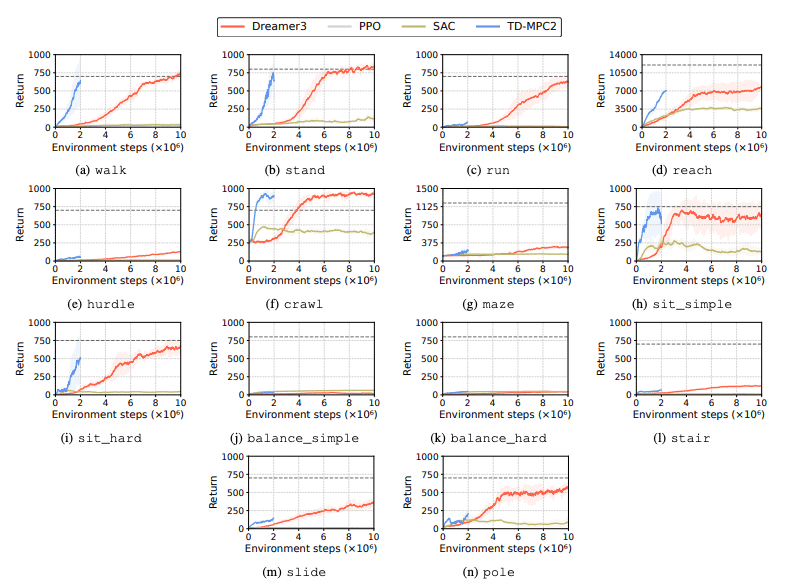
Em particular, os algoritmos RL atuais lutam para lidar com espaços de ação de alta dimensão e tarefas complexas. Especialmente os robôs humanóides têm dificuldade em executar tarefas que exigem mãos hábeis e coordenação corporal complexa. Além disso, as tarefas de manipulação também são particularmente desafiadoras e muitas vezes têm recompensas mais baixas.
Uma falha comum é que os benchmarks humanóides lutam para aprender o comportamento esperado dos robôs em tarefas como obstáculos altos, portões e obstáculos. Isso ocorre porque é difícil encontrar estratégias que se ajustem a comportamentos complexos.
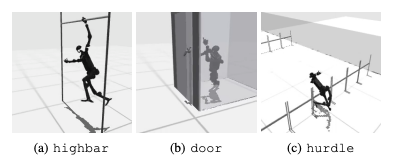
Para enfrentar estes desafios, está a ser considerada uma abordagem hierárquica de RL. Treinar competências de baixo nível e combiná-las com estratégias de planeamento de alto nível pode facilitar a solução de tarefas. No entanto, ainda há espaço para melhorias no algoritmo atual.
Esta pesquisa apresenta um humanóide de alta dimensão chamado HumanoidBenchControle do robô referência. Este benchmark fornece um ambiente humanóide abrangente, incluindo uma variedade de tarefas de locomoção e manipulação, desde brinquedos até aplicações do mundo real. Os autores do artigo esperam que ele possa desafiar tarefas tão complexas e promover o desenvolvimento de algoritmos de corpo inteiro para robôs humanóides.
Em estudos futuros, será importante estudar as interações entre diferentes modalidades de detecção. Além disso, será considerada a combinação de objetos e ambientes mais realistas com variedade do mundo real e renderização de alta qualidade. Além disso, será dada ênfase a outros meios de induzir a aprendizagem em ambientes onde é difícil recolher demonstrações físicas.

Ele se dedica à pesquisa de tecnologia há mais de trinta anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc., e fez muitas contribuições no campo de código aberto. uma estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]