2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Adresse papier :https://arxiv.org/pdf/2403.10506
Les robots humanoïdes ont une apparence humaine et sont censés soutenir les humains dans divers environnements et tâches. Cependant, le matériel coûteux et fragile constitue un défi pour cette recherche. Par conséquent, cette étude a développé HumanoidBench en utilisant une technologie de simulation avancée. Ce benchmark évalue les performances de différents algorithmes utilisant des robots humanoïdes, y compris une variété de tâches telles que la manipulation bimanuelle adroite et complexe du corps entier.Les résultats de la recherche montrent que les plus avancésalgorithme d'apprentissage par renforcement Il rencontre des difficultés sur de nombreuses tâches, tandis que les algorithmes d’apprentissage hiérarchique fonctionnent mieux sur des actions de base comme marcher et toucher des objets. HumanoidBench est un outil important permettant à la communauté robotique de relever les défis rencontrés par les robots humanoïdes, en fournissant une plate-forme de vérification rapide des algorithmes et des idées.
Les robots humanoïdes devraient s’intégrer parfaitement dans notre vie quotidienne. Cependant, leurs commandes sont conçues manuellement pour des tâches spécifiques, et les nouvelles tâches nécessitent un travail d'ingénierie approfondi. Pour résoudre ce problème, nous avons développé un benchmark appelé HumanoidBench pour faciliter l'apprentissage des robots humanoïdes. Cela implique toute une série de défis, notamment des contrôles complexes, une coordination physique et des tâches à long terme.Cette plateforme est un robot de testalgorithme d'apprentissage Fournit un environnement sûr et peu coûteux et contient une variété de tâches liées aux tâches humaines quotidiennes. HumanoidBench peut facilement intégrer une variété de robots humanoïdes et d'effecteurs finaux, 15 tâches de manipulation du corps entier et 12 tâches de locomotion. Cela permet aux algorithmes RL de pointe de contrôler la dynamique complexe des robots humanoïdes et fournit une orientation pour les recherches futures.
L’apprentissage par renforcement profond (RL) progresse rapidement avec l’émergence de références de simulation standardisées. Cependant, les environnements existants de simulation du fonctionnement des robots se concentrent principalement sur des compétences statiques à court terme et n’impliquent pas d’opérations complexes. En revanche, les critères de référence proposés se concentrent sur diverses opérations à long terme. Cependant, la plupart des benchmarks sont conçus pour des tâches spécifiques et beaucoup utilisent des modèles simplifiés. Cela nécessite des benchmarks synthétiques basés sur du matériel réel.
L’agent robotique principal est un robot humanoïde Unitree H1 doté de deux mains fantômes adroites2. Le robot est simulé via MuJoCo. L'environnement simulé prend en charge une gamme d'observations, notamment l'état du robot, l'état des objets, les observations visuelles et la détection tactile de l'ensemble du corps. Les robots humanoïdes peuvent également être contrôlés via le contrôle de position.
Pour effectuer des tâches similaires à celles des humains, un robot doit être capable de comprendre son environnement et de prendre les mesures appropriées. Cependant, tester des robots dans le monde réel est difficile en raison de problèmes de coût et de sécurité. Les environnements de simulation sont donc des outils importants pour apprendre et contrôler les robots.
HumanoidBench comprend 27 tâches avec un espace de mouvement de grande dimension (jusqu'à 61 actionneurs). Les tâches motrices comprennent des mouvements de base tels que la marche et la course. Les tâches de manipulation comprennent des tâches avancées telles que pousser, tirer, soulever et saisir des objets.

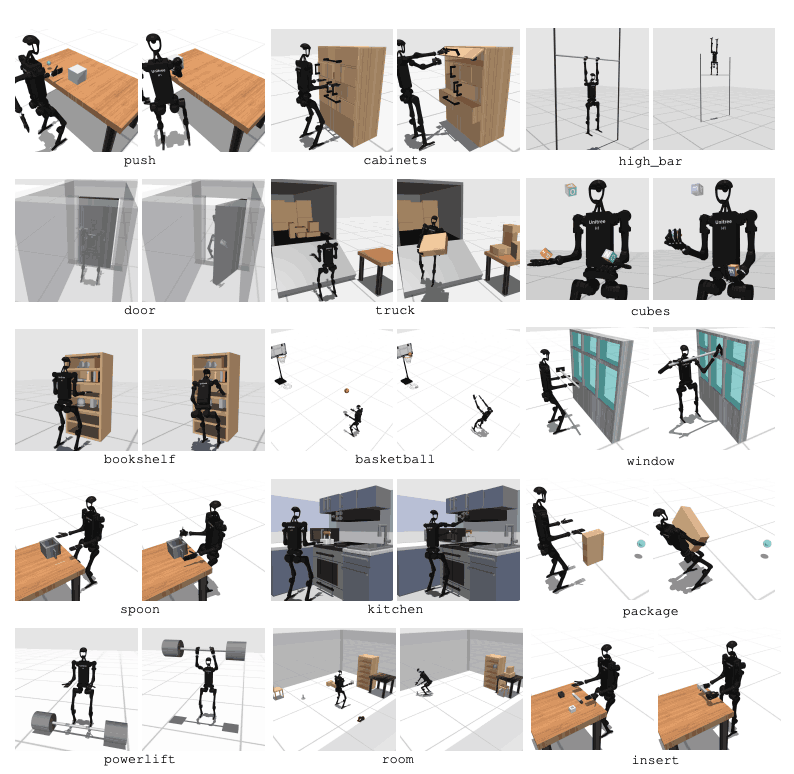
Le but du benchmark est d’évaluer dans quelle mesure les algorithmes modernes peuvent accomplir ces tâches. Le robot doit observer l’état de l’environnement et choisir les actions appropriées en conséquence. Grâce à la fonction de récompense, le robot peut apprendre la meilleure stratégie pour accomplir la tâche.
Par exemple, lors d’une tâche de marche, le robot doit maintenir sa vitesse d’avancement sans tomber. Optimiser l’équilibre et la démarche est très important dans ce type de tâche. En revanche, dans les tâches de manipulation, le robot doit manipuler des objets avec précision. Cela nécessite une connaissance de la position et de l'orientation de l'objet ainsi qu'un contrôle approprié de la force.
L’objectif de HumanoidBench est de faire progresser le domaine de l’apprentissage et du contrôle robotique grâce à ces tâches. Grâce à des environnements simulés, les chercheurs peuvent mener des expériences en toute sécurité et évaluer les performances des robots dans de nombreux scénarios différents. Cela contribuera à développer de meilleurs algorithmes de contrôle et méthodes d’apprentissage, favorisant ainsi l’application future des robots humanoïdes dans le monde réel.
Les performances des algorithmes d'apprentissage par renforcement (RL) sont évaluées pour identifier les défis rencontrés par les robots humanoïdes dans les tâches d'apprentissage. Quatre méthodes principales d'apprentissage par renforcement sont utilisées à cet effet, notamment DreamerV3, TD-MPC2, SAC et PPO. Les résultats montrent que l'algorithme de base fonctionne en dessous du seuil de réussite sur de nombreuses tâches.
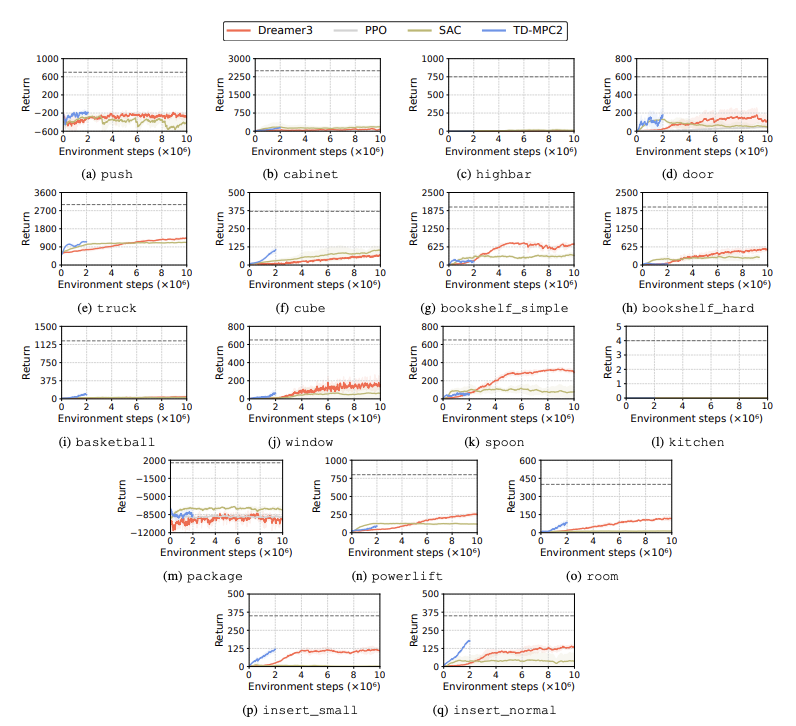
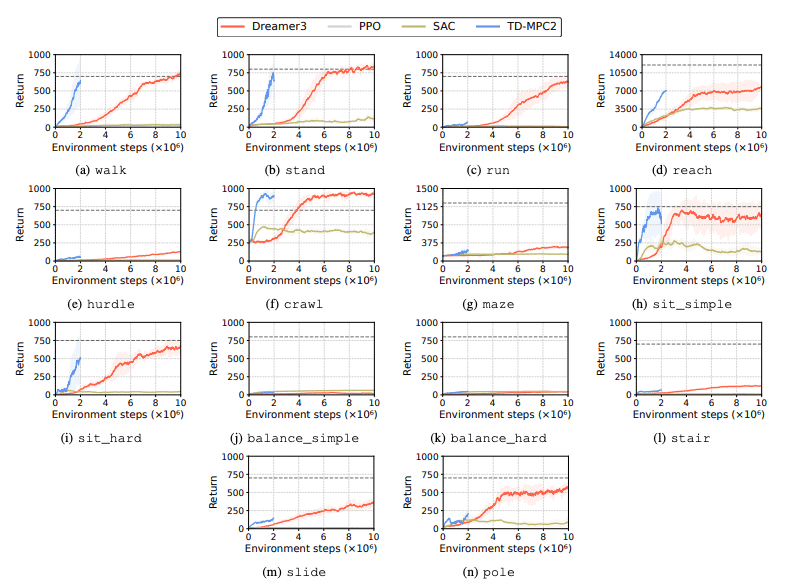
En particulier, les algorithmes RL actuels ont du mal à gérer des espaces d’action de grande dimension et des tâches complexes. Les robots humanoïdes ont particulièrement du mal à effectuer des tâches qui nécessitent des mains adroites et une coordination corporelle complexe. En plus de cela, les tâches de manipulation sont également particulièrement difficiles et souvent moins rémunératrices.
Un échec courant est que les références humanoïdes ont du mal à apprendre le comportement attendu des robots dans des tâches telles que des haies, des portes et des obstacles élevés. En effet, il est difficile de trouver des stratégies adaptées à des comportements complexes.
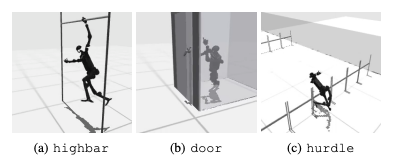
Pour relever ces défis, une approche hiérarchique RL est envisagée. Former des compétences de bas niveau et les combiner avec des stratégies de planification de haut niveau peut faciliter la résolution des tâches. Cependant, l’algorithme actuel peut encore être amélioré.
Cette recherche présente un humanoïde de grande dimension appelé HumanoidBenchContrôle des robots référence. Ce benchmark fournit un environnement humanoïde complet comprenant une variété de tâches de locomotion et de manipulation, depuis les jouets jusqu'aux applications du monde réel. Les auteurs de l’article espèrent qu’il pourra remettre en question des tâches aussi complexes et promouvoir le développement d’algorithmes corporels complets pour les robots humanoïdes.
Dans les études futures, il sera important d’étudier les interactions entre différentes modalités de détection. De plus, on envisagera de combiner des objets et des environnements plus réalistes avec une variété du monde réel et un rendu de haute qualité. De plus, l'accent sera mis sur d'autres moyens d'induire l'apprentissage dans des environnements où il est difficile de rassembler des démonstrations physiques.

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.
