Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Dirección del papel:https://arxiv.org/pdf/2403.10506
Los robots humanoides tienen una apariencia humana y se espera que apoyen a los humanos en una variedad de entornos y tareas. Sin embargo, el hardware costoso y frágil es un desafío para esta investigación. Por lo tanto, este estudio desarrolló HumanoidBench utilizando tecnología de simulación avanzada. Este punto de referencia evalúa el rendimiento de diferentes algoritmos que utilizan robots humanoides, incluida una variedad de tareas como la manipulación bimanual diestra y la manipulación compleja de todo el cuerpo.Los resultados de la investigación muestran que los más avanzadosalgoritmo de aprendizaje por refuerzo Tiene dificultades en muchas tareas, mientras que los algoritmos de aprendizaje jerárquico funcionan mejor en acciones básicas como caminar y tocar objetos. HumanoidBench es una herramienta importante para que la comunidad de robótica aborde los desafíos que enfrentan los robots humanoides, proporcionando una plataforma para la verificación rápida de algoritmos e ideas.
Se espera que los robots humanoides se integren perfectamente en nuestra vida diaria. Sin embargo, sus controles están diseñados manualmente para tareas específicas y las nuevas tareas requieren un extenso trabajo de ingeniería. Para abordar este problema, desarrollamos un punto de referencia llamado HumanoidBench para facilitar el aprendizaje de robots humanoides. Esto implica una serie de desafíos, incluidos controles complejos, coordinación física y tareas a largo plazo.Esta plataforma es un robot de prueba.algoritmo de aprendizaje Proporciona un entorno seguro y económico y contiene una variedad de tareas relacionadas con las tareas humanas diarias. HumanoidBench puede incorporar fácilmente una variedad de robots humanoides y efectores finales, 15 tareas de manipulación de todo el cuerpo y 12 tareas de locomoción. Esto permite que los algoritmos RL de última generación controlen la compleja dinámica de los robots humanoides y proporciona una dirección para futuras investigaciones.
El aprendizaje por refuerzo profundo (RL) está avanzando rápidamente con la aparición de puntos de referencia de simulación estandarizados. Sin embargo, los entornos de simulación de operaciones de robots existentes se centran principalmente en habilidades estáticas y de corto plazo y no implican operaciones complejas. Por el contrario, los puntos de referencia que se han propuesto se centran en diversas operaciones a largo plazo. Sin embargo, la mayoría de los puntos de referencia están diseñados para tareas específicas y muchos utilizan modelos simplificados. Esto requiere pruebas comparativas sintéticas basadas en hardware real.
El principal agente robótico es un robot humanoide Unitree H1 con dos diestras manos en la sombra2. El robot se simula a través de MuJoCo. El entorno simulado admite una variedad de observaciones, incluido el estado del robot, el estado del objeto, observaciones visuales y detección táctil de todo el cuerpo. Los robots humanoides también se pueden controlar mediante control de posición.
Para realizar tareas similares a las de los humanos, un robot debe poder comprender su entorno y tomar las acciones adecuadas. Sin embargo, probar robots en el mundo real es difícil debido a preocupaciones de costo y seguridad. Por tanto, los entornos de simulación son herramientas importantes para aprender y controlar robots.
HumanoidBench incluye 27 tareas con un espacio de movimiento de alta dimensión (hasta 61 actuadores). Las tareas motoras incluyen movimientos básicos como caminar y correr. Las tareas de manipulación incluyen tareas avanzadas como empujar, tirar, levantar y agarrar objetos.

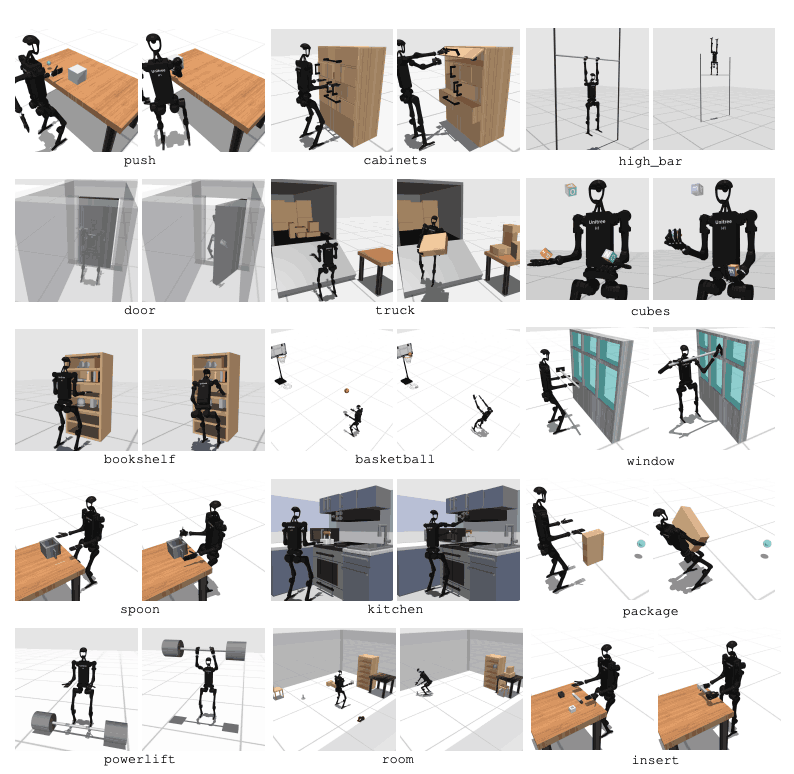
El propósito del punto de referencia es evaluar qué tan bien los algoritmos modernos pueden realizar estas tareas. El robot necesita observar el estado del entorno y elegir las acciones apropiadas en consecuencia. A través de la función de recompensa, el robot puede aprender la mejor estrategia para realizar la tarea.
Por ejemplo, en una tarea de caminar, el robot necesita mantener la velocidad de avance sin caerse. Optimizar el equilibrio y la marcha es muy importante en este tipo de tareas. Por otro lado, en las tareas de manipulación, el robot necesita manipular los objetos con precisión. Esto requiere conocimiento de la posición y orientación del objeto y un control de fuerza adecuado.
El objetivo de HumanoidBench es avanzar en el campo del aprendizaje y control robótico a través de estas tareas. Utilizando entornos simulados, los investigadores pueden realizar experimentos de forma segura y evaluar el rendimiento del robot en muchos escenarios diferentes. Esto ayudará a desarrollar mejores algoritmos de control y métodos de aprendizaje, promoviendo así la futura aplicación de robots humanoides en el mundo real.
Se evalúa el rendimiento de los algoritmos de aprendizaje por refuerzo (RL) para identificar los desafíos que enfrentan los robots humanoides en las tareas de aprendizaje. Para este propósito se utilizan cuatro métodos principales de aprendizaje por refuerzo, incluidos DreamerV3, TD-MPC2, SAC y PPO. Los resultados muestran que el algoritmo de referencia funciona por debajo del umbral de éxito en muchas tareas.
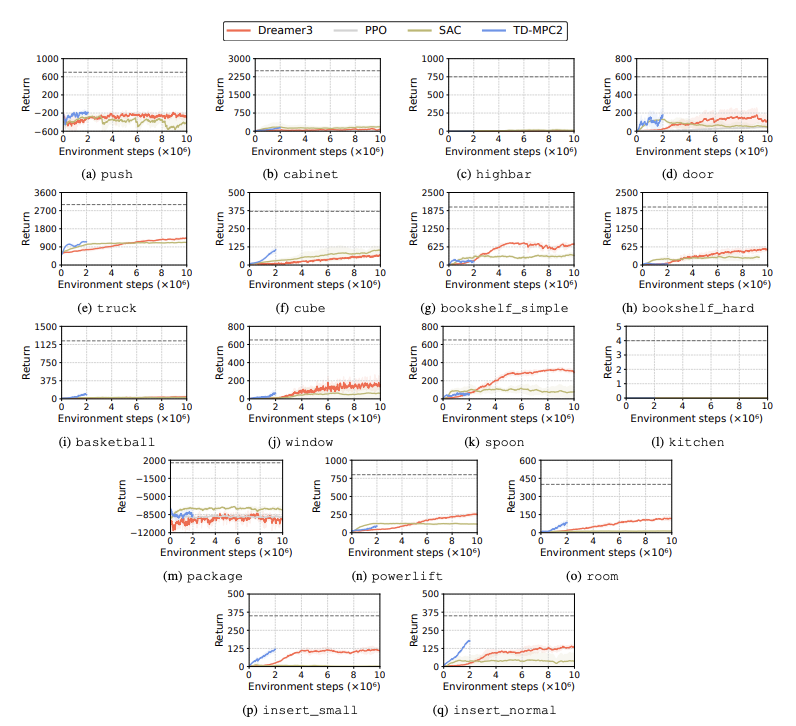
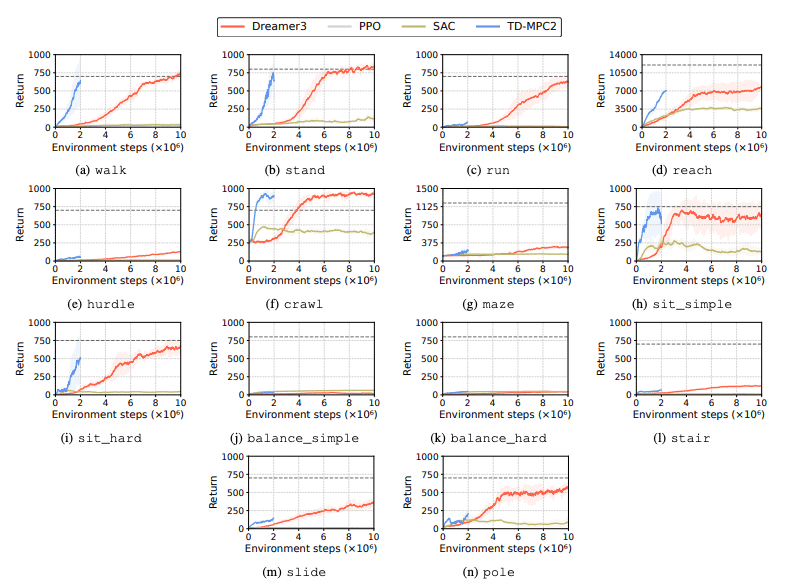
En particular, los algoritmos RL actuales tienen dificultades para manejar espacios de acción de alta dimensión y tareas complejas. Los robots humanoides tienen especialmente problemas para realizar tareas que requieren manos diestras y una coordinación corporal compleja. Además de esto, las tareas de manipulación también son particularmente desafiantes y, a menudo, tienen menores recompensas.
Una falla común es que los puntos de referencia humanoides luchan por aprender el comportamiento esperado de los robots en tareas como vallas altas, puertas y obstáculos. Esto se debe a que es difícil encontrar estrategias que se ajusten a comportamientos complejos.
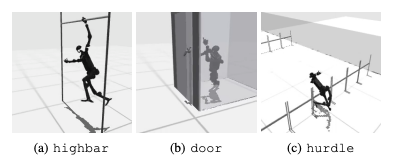
Para abordar estos desafíos, se está considerando un enfoque jerárquico de RL. Entrenar habilidades de bajo nivel y combinarlas con estrategias de planificación de alto nivel puede facilitar la solución de tareas. Sin embargo, todavía hay margen de mejora en el algoritmo actual.
Esta investigación presenta un humanoide de alta dimensión llamado HumanoidBenchcontrol de robots punto de referencia. Este punto de referencia proporciona un entorno humanoide integral que incluye una variedad de tareas de locomoción y manipulación, desde juguetes hasta aplicaciones del mundo real. Los autores del artículo esperan que pueda desafiar tareas tan complejas y promover el desarrollo de algoritmos de cuerpo completo para robots humanoides.
En estudios futuros, será importante estudiar las interacciones entre diferentes modalidades de detección. Además, se considerará la posibilidad de combinar objetos y entornos más realistas con una variedad del mundo real y una representación de alta calidad. Además, se hará hincapié en otros medios para inducir el aprendizaje en entornos donde es difícil recopilar demostraciones físicas.

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]