τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Διεύθυνση χαρτιού:https://arxiv.org/pdf/2403.10506
Τα ανθρωποειδή ρομπότ έχουν ανθρώπινη εμφάνιση και αναμένεται να υποστηρίζουν τους ανθρώπους σε ποικίλα περιβάλλοντα και εργασίες. Ωστόσο, το ακριβό και εύθραυστο υλικό είναι μια πρόκληση για αυτήν την έρευνα. Επομένως, αυτή η μελέτη ανέπτυξε το HumanoidBench χρησιμοποιώντας προηγμένη τεχνολογία προσομοίωσης. Αυτό το σημείο αναφοράς αξιολογεί την απόδοση διαφορετικών αλγορίθμων που χρησιμοποιούν ανθρωποειδή ρομπότ, συμπεριλαμβανομένων ποικίλων εργασιών, όπως επιδέξιος χειρισμός με δύο χειροκίνητα και πολύπλοκους χειρισμούς ολόκληρου του σώματος.Τα αποτελέσματα της έρευνας δείχνουν ότι οι πιο προηγμένεςαλγόριθμος ενίσχυσης μάθησης Δυσκολεύεται σε πολλές εργασίες, ενώ οι αλγόριθμοι ιεραρχικής μάθησης αποδίδουν καλύτερα σε βασικές ενέργειες όπως το περπάτημα και το άγγιγμα αντικειμένων. Το HumanoidBench είναι ένα σημαντικό εργαλείο για την κοινότητα της ρομποτικής για την αντιμετώπιση των προκλήσεων που αντιμετωπίζουν τα ανθρωποειδή ρομπότ, παρέχοντας μια πλατφόρμα για γρήγορη επαλήθευση αλγορίθμων και ιδεών.
Τα ανθρωποειδή ρομπότ αναμένεται να ενσωματωθούν απρόσκοπτα στην καθημερινότητά μας. Ωστόσο, τα χειριστήρια τους σχεδιάζονται χειροκίνητα για συγκεκριμένες εργασίες και οι νέες εργασίες απαιτούν εκτεταμένη μηχανική εργασία. Για να αντιμετωπίσουμε αυτό το πρόβλημα, αναπτύξαμε ένα σημείο αναφοράς που ονομάζεται HumanoidBench για να διευκολύνουμε την εκμάθηση ανθρωποειδών ρομπότ. Αυτό περιλαμβάνει μια σειρά από προκλήσεις, συμπεριλαμβανομένων πολύπλοκων ελέγχων, σωματικού συντονισμού και μακροπρόθεσμων εργασιών.Αυτή η πλατφόρμα είναι ένα δοκιμαστικό ρομπόταλγόριθμος εκμάθησης Παρέχει ένα ασφαλές, φθηνό περιβάλλον και περιέχει μια ποικιλία εργασιών που σχετίζονται με τις καθημερινές ανθρώπινες εργασίες. Το HumanoidBench μπορεί εύκολα να ενσωματώσει μια ποικιλία ανθρωποειδών ρομπότ και τελικών τελεστών, 15 εργασίες χειρισμού ολόκληρου του σώματος και 12 εργασίες μετακίνησης. Αυτό επιτρέπει σε αλγόριθμους RL τελευταίας τεχνολογίας να ελέγχουν τη σύνθετη δυναμική των ανθρωποειδών ρομπότ και παρέχει μια κατεύθυνση για μελλοντική έρευνα.
Η βαθιά ενισχυτική μάθηση (RL) προχωρά με ταχείς ρυθμούς με την εμφάνιση τυποποιημένων σημείων αναφοράς προσομοίωσης. Ωστόσο, τα υπάρχοντα περιβάλλοντα προσομοίωσης λειτουργίας ρομπότ επικεντρώνονται κυρίως σε στατικές, βραχυπρόθεσμες δεξιότητες και δεν περιλαμβάνουν πολύπλοκες λειτουργίες. Αντίθετα, τα κριτήρια αναφοράς που έχουν προταθεί εστιάζονται σε διάφορες μακροπρόθεσμες λειτουργίες. Ωστόσο, τα περισσότερα σημεία αναφοράς έχουν σχεδιαστεί για συγκεκριμένες εργασίες και πολλά χρησιμοποιούν απλοποιημένα μοντέλα. Αυτό απαιτεί συνθετικά σημεία αναφοράς που βασίζονται σε πραγματικό υλικό.
Ο κύριος ρομποτικός πράκτορας είναι ένα ανθρωποειδές ρομπότ Unitree H1 με δύο επιδέξια χέρια σκιάς2. Το ρομπότ προσομοιώνεται μέσω του MuJoCo. Το προσομοιωμένο περιβάλλον υποστηρίζει μια σειρά από παρατηρήσεις, συμπεριλαμβανομένης της κατάστασης του ρομπότ, της κατάστασης αντικειμένου, των οπτικών παρατηρήσεων και της αίσθησης αφής ολόκληρου του σώματος. Τα ανθρωποειδή ρομπότ μπορούν επίσης να ελεγχθούν μέσω ελέγχου θέσης.
Για να εκτελέσει εργασίες παρόμοιες με τους ανθρώπους, ένα ρομπότ πρέπει να είναι σε θέση να κατανοήσει το περιβάλλον του και να λάβει τις κατάλληλες ενέργειες. Ωστόσο, η δοκιμή ρομπότ στον πραγματικό κόσμο είναι δύσκολη λόγω ανησυχιών κόστους και ασφάλειας. Επομένως, τα περιβάλλοντα προσομοίωσης είναι σημαντικά εργαλεία για την εκμάθηση και τον έλεγχο των ρομπότ.
Το HumanoidBench περιλαμβάνει 27 εργασίες με χώρο κίνησης υψηλών διαστάσεων (έως 61 ενεργοποιητές). Οι κινητικές εργασίες περιλαμβάνουν βασικές κινήσεις όπως το περπάτημα και το τρέξιμο. Οι εργασίες χειρισμού περιλαμβάνουν προηγμένες εργασίες όπως ώθηση, τράβηγμα, ανύψωση και σύλληψη αντικειμένων.

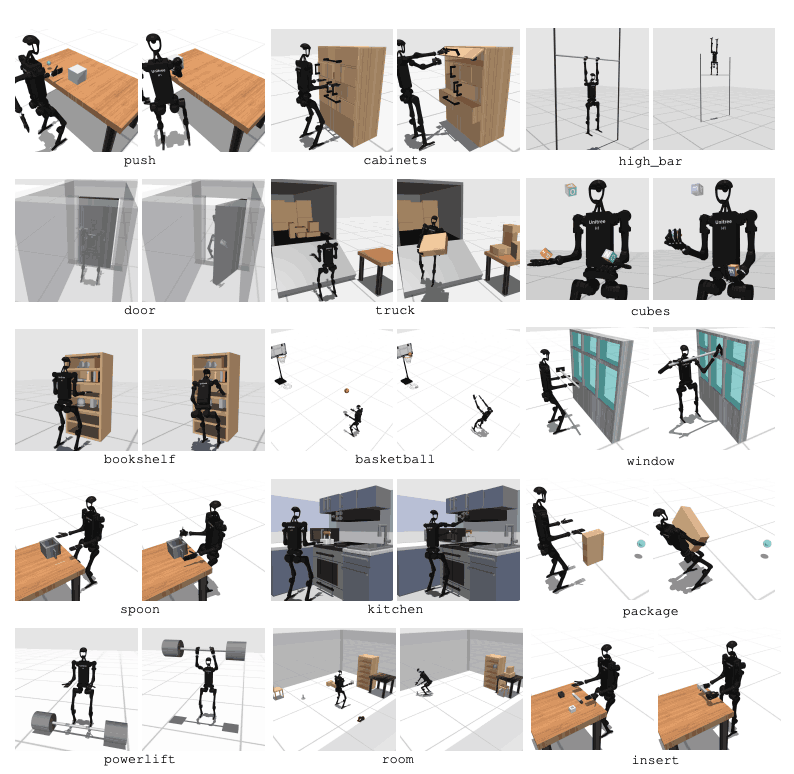
Ο σκοπός του σημείου αναφοράς είναι να αξιολογήσει πόσο καλά οι σύγχρονοι αλγόριθμοι μπορούν να ολοκληρώσουν αυτές τις εργασίες. Το ρομπότ πρέπει να παρατηρεί την κατάσταση του περιβάλλοντος και να επιλέγει τις κατάλληλες ενέργειες ανάλογα. Μέσω της λειτουργίας ανταμοιβής, το ρομπότ μπορεί να μάθει την καλύτερη στρατηγική για να εκτελέσει την εργασία.
Για παράδειγμα, σε μια εργασία με τα πόδια, το ρομπότ πρέπει να διατηρεί ταχύτητα προς τα εμπρός χωρίς να πέφτει. Η βελτιστοποίηση της ισορροπίας και του βαδίσματος είναι πολύ σημαντική σε αυτό το είδος εργασίας. Από την άλλη πλευρά, στις εργασίες χειρισμού, το ρομπότ χρειάζεται να χειρίζεται αντικείμενα με ακρίβεια. Αυτό απαιτεί γνώση της θέσης και του προσανατολισμού του αντικειμένου και τον κατάλληλο έλεγχο της δύναμης.
Ο στόχος του HumanoidBench είναι να προωθήσει τον τομέα της ρομποτικής μάθησης και ελέγχου μέσω αυτών των εργασιών. Χρησιμοποιώντας προσομοιωμένα περιβάλλοντα, οι ερευνητές μπορούν να διεξάγουν με ασφάλεια πειράματα και να αξιολογούν την απόδοση του ρομπότ σε πολλά διαφορετικά σενάρια. Αυτό θα βοηθήσει στην ανάπτυξη καλύτερων αλγορίθμων ελέγχου και μεθόδων εκμάθησης, προωθώντας έτσι τη μελλοντική εφαρμογή των ανθρωποειδών ρομπότ στον πραγματικό κόσμο.
Η απόδοση των αλγορίθμων ενισχυτικής μάθησης (RL) αξιολογείται για τον εντοπισμό των προκλήσεων που αντιμετωπίζουν τα ανθρωποειδή ρομπότ στις μαθησιακές εργασίες. Για το σκοπό αυτό χρησιμοποιούνται τέσσερις κύριες μέθοδοι ενισχυτικής εκμάθησης, συμπεριλαμβανομένων των DreamerV3, TD-MPC2, SAC και PPO. Τα αποτελέσματα δείχνουν ότι ο βασικός αλγόριθμος αποδίδει κάτω από το όριο επιτυχίας σε πολλές εργασίες.
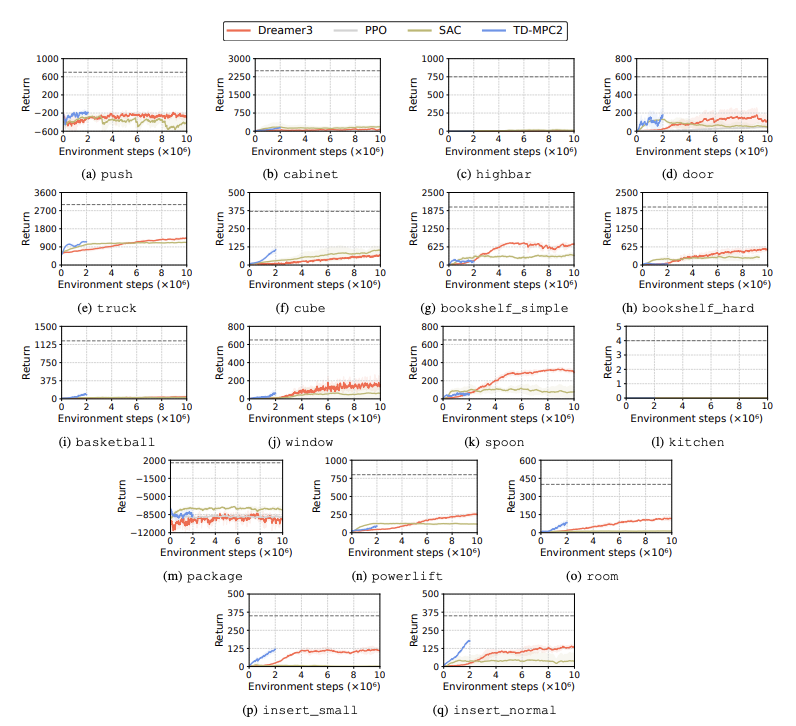
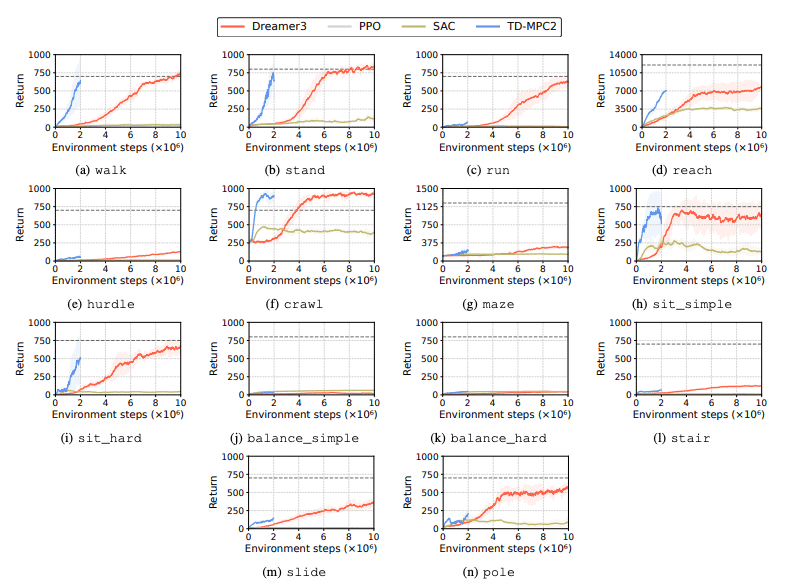
Συγκεκριμένα, οι τρέχοντες αλγόριθμοι RL δυσκολεύονται να χειριστούν χώρους δράσης υψηλών διαστάσεων και πολύπλοκες εργασίες. Τα ανθρωποειδή ρομπότ δυσκολεύονται ιδιαίτερα να εκτελούν εργασίες που απαιτούν επιδέξια χέρια και πολύπλοκο συντονισμό του σώματος. Επιπλέον, οι εργασίες χειραγώγησης είναι επίσης ιδιαίτερα προκλητικές και συχνά έχουν χαμηλότερες ανταμοιβές.
Μια κοινή αποτυχία είναι ότι τα ανθρωποειδή σημεία αναφοράς αγωνίζονται να μάθουν την αναμενόμενη συμπεριφορά των ρομπότ σε εργασίες όπως υψηλά εμπόδια, πύλες και εμπόδια. Αυτό συμβαίνει γιατί είναι δύσκολο να βρεθούν στρατηγικές που να ταιριάζουν σε σύνθετες συμπεριφορές.
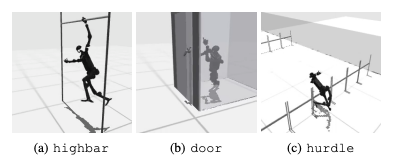
Για την αντιμετώπιση αυτών των προκλήσεων, εξετάζεται μια ιεραρχική προσέγγιση RL. Η εκπαίδευση δεξιοτήτων χαμηλού επιπέδου και ο συνδυασμός τους με στρατηγικές σχεδιασμού υψηλού επιπέδου μπορεί να διευκολύνει τη λύση της εργασίας. Ωστόσο, υπάρχει ακόμη περιθώριο βελτίωσης στον τρέχοντα αλγόριθμο.
Αυτή η έρευνα εισάγει ένα ανθρωποειδές υψηλών διαστάσεων που ονομάζεται HumanoidBenchΈλεγχος ρομπότ σημείο αναφοράς. Αυτό το σημείο αναφοράς παρέχει ένα ολοκληρωμένο ανθρωποειδές περιβάλλον που περιλαμβάνει μια ποικιλία εργασιών μετακίνησης και χειρισμού, από παιχνίδια έως εφαρμογές πραγματικού κόσμου. Οι συντάκτες της εργασίας ελπίζουν ότι μπορεί να αμφισβητήσει τόσο πολύπλοκα καθήκοντα και να προωθήσει την ανάπτυξη αλγορίθμων για ολόσωμα ανθρωποειδή ρομπότ.
Σε μελλοντικές μελέτες, θα είναι σημαντικό να μελετηθούν οι αλληλεπιδράσεις μεταξύ διαφορετικών τρόπων αίσθησης. Επιπλέον, θα δοθεί προσοχή στον συνδυασμό πιο ρεαλιστικών αντικειμένων και περιβαλλόντων με πραγματική ποικιλία και απόδοση υψηλής ποιότητας. Επιπλέον, θα δοθεί έμφαση σε άλλα μέσα πρόκλησης μάθησης σε περιβάλλοντα όπου είναι δύσκολο να συλλεχθούν φυσικές επιδείξεις.

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα σταθμός τεκμηρίωσης προγραμματιστή για να μοιραστείτε ορισμένα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]