le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Indirizzo cartaceo:Italiano: https://arxiv.org/pdf/2403.10506
I robot umanoidi hanno un aspetto simile a quello umano e dovrebbero supportare gli esseri umani in una varietà di ambienti e compiti. Tuttavia, l’hardware costoso e fragile rappresenta una sfida per questa ricerca. Pertanto, questo studio ha sviluppato HumanoidBench utilizzando una tecnologia di simulazione avanzata. Questo benchmark valuta le prestazioni di diversi algoritmi utilizzando robot umanoidi, tra cui una varietà di compiti come l'abile manipolazione bimanuale e la complessa manipolazione di tutto il corpo.I risultati della ricerca mostrano che il più avanzatoalgoritmo di apprendimento per rinforzo Fa fatica in molti compiti, mentre gli algoritmi di apprendimento gerarchico funzionano meglio su azioni di base come camminare e toccare oggetti. HumanoidBench è uno strumento importante per la comunità della robotica per affrontare le sfide affrontate dai robot umanoidi, fornendo una piattaforma per la verifica rapida di algoritmi e idee.
Si prevede che i robot umanoidi si integreranno perfettamente nella nostra vita quotidiana. Tuttavia, i loro controlli sono progettati manualmente per attività specifiche e le nuove attività richiedono un ampio lavoro di ingegneria. Per risolvere questo problema, abbiamo sviluppato un benchmark chiamato HumanoidBench per facilitare l'apprendimento dei robot umanoidi. Ciò comporta una serie di sfide, tra cui controlli complessi, coordinamento fisico e compiti a lungo termine.Questa piattaforma è un robot di provaalgoritmo di apprendimento Fornisce un ambiente sicuro ed economico e contiene una varietà di attività relative alle attività umane quotidiane. HumanoidBench può facilmente incorporare una varietà di robot umanoidi ed effettori finali, 15 attività di manipolazione del corpo intero e 12 attività di locomozione. Ciò consente agli algoritmi RL all’avanguardia di controllare le complesse dinamiche dei robot umanoidi e fornisce una direzione per la ricerca futura.
L’apprendimento per rinforzo profondo (RL) sta avanzando rapidamente con l’emergere di benchmark di simulazione standardizzati. Tuttavia, gli ambienti di simulazione del funzionamento dei robot esistenti si concentrano principalmente su competenze statiche e a breve termine e non comportano operazioni complesse. Al contrario, i parametri di riferimento proposti si concentrano su varie operazioni a lungo termine. Tuttavia, la maggior parte dei benchmark sono progettati per compiti specifici e molti utilizzano modelli semplificati. Ciò richiede benchmark sintetici basati su hardware reale.
L'agente robotico principale è un robot umanoide Unitree H1 con due abili mani ombra2. Il robot viene simulato tramite MuJoCo. L'ambiente simulato supporta una serie di osservazioni, tra cui lo stato del robot, lo stato degli oggetti, osservazioni visive e rilevamento tattile di tutto il corpo. I robot umanoidi possono essere controllati anche tramite il controllo della posizione.
Per eseguire compiti simili a quelli umani, un robot deve essere in grado di comprendere il suo ambiente e intraprendere azioni appropriate. Tuttavia, testare i robot nel mondo reale è difficile a causa di problemi di costi e sicurezza. Pertanto, gli ambienti di simulazione sono strumenti importanti per l’apprendimento e il controllo dei robot.
HumanoidBench comprende 27 attività con uno spazio di movimento altamente dimensionale (fino a 61 attuatori). Le attività motorie includono movimenti di base come camminare e correre. Le attività di manipolazione includono attività avanzate come spingere, tirare, sollevare e afferrare oggetti.

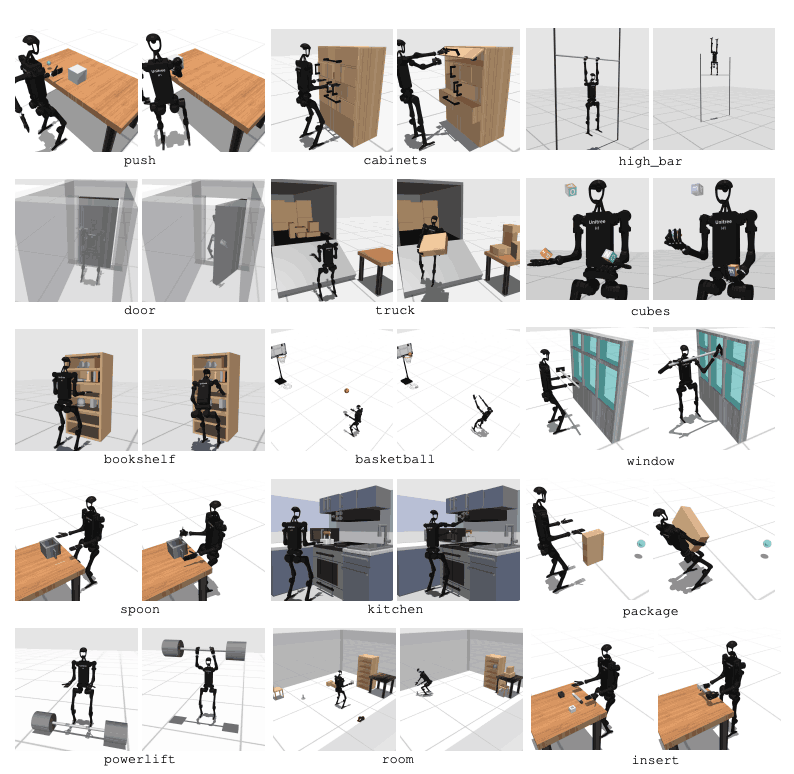
Lo scopo del benchmark è valutare quanto bene gli algoritmi moderni possano svolgere questi compiti. Il robot deve osservare lo stato dell'ambiente e scegliere di conseguenza le azioni appropriate. Attraverso la funzione di ricompensa, il robot può apprendere la migliore strategia per eseguire l'attività.
Ad esempio, in un'attività di camminata, il robot deve mantenere la velocità di avanzamento senza cadere. Ottimizzare l’equilibrio e l’andatura è molto importante in questo tipo di attività. Nei compiti di manipolazione, invece, il robot deve manipolare gli oggetti con precisione. Ciò richiede la conoscenza della posizione e dell'orientamento dell'oggetto e un adeguato controllo della forza.
L’obiettivo di HumanoidBench è quello di far avanzare il campo dell’apprendimento e del controllo robotico attraverso questi compiti. Utilizzando ambienti simulati, i ricercatori possono condurre esperimenti in sicurezza e valutare le prestazioni dei robot in molti scenari diversi. Ciò contribuirà a sviluppare algoritmi di controllo e metodi di apprendimento migliori, promuovendo così la futura applicazione dei robot umanoidi nel mondo reale.
Le prestazioni degli algoritmi di apprendimento per rinforzo (RL) vengono valutate per identificare le sfide affrontate dai robot umanoidi nelle attività di apprendimento. A questo scopo vengono utilizzati quattro principali metodi di apprendimento per rinforzo, tra cui DreamerV3, TD-MPC2, SAC e PPO. I risultati mostrano che l'algoritmo di base funziona al di sotto della soglia di successo in molte attività.
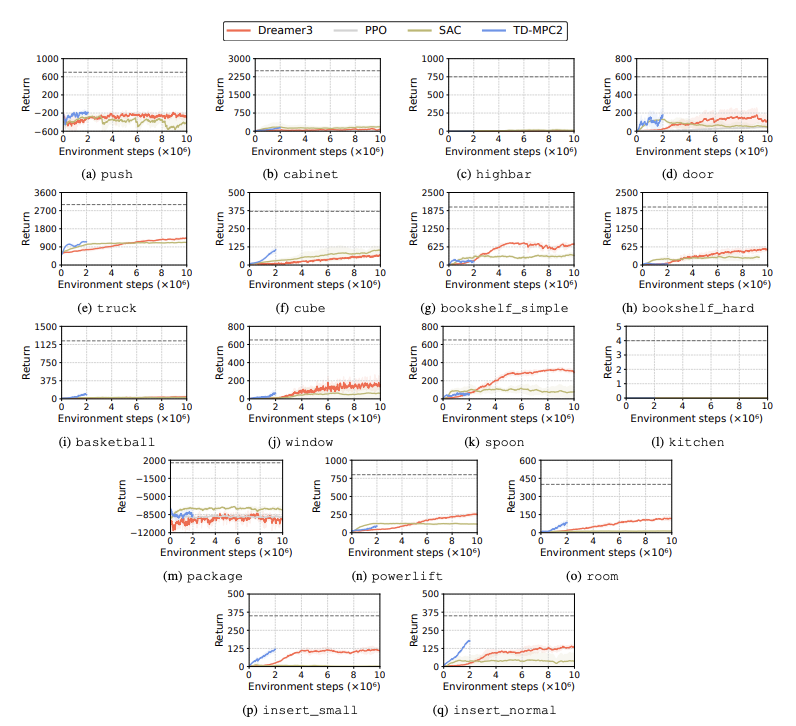
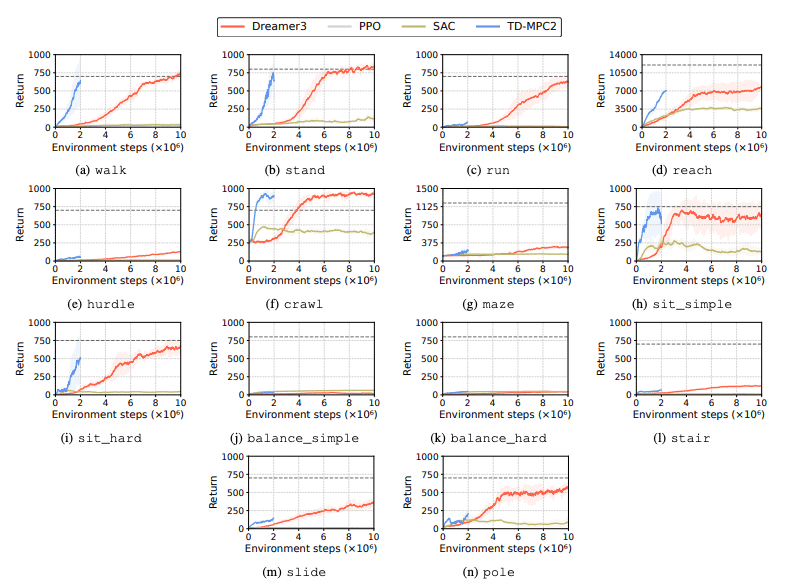
In particolare, gli attuali algoritmi RL hanno difficoltà a gestire spazi di azione ad alta dimensione e compiti complessi. In particolare, i robot umanoidi hanno difficoltà a svolgere compiti che richiedono mani abili e una complessa coordinazione corporea. Oltre a ciò, anche i compiti di manipolazione sono particolarmente impegnativi e spesso comportano ricompense inferiori.
Un fallimento comune è che i benchmark umanoidi faticano ad apprendere il comportamento previsto dei robot in compiti come ostacoli alti, cancelli e ostacoli. Questo perché è difficile trovare strategie che si adattino a comportamenti complessi.
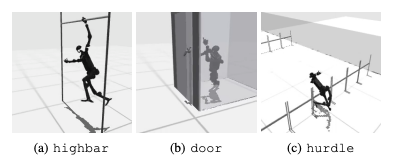
Per affrontare queste sfide, si sta prendendo in considerazione un approccio gerarchico RL. Formare competenze di basso livello e combinarle con strategie di pianificazione di alto livello può facilitare la soluzione dei compiti. Tuttavia, c’è ancora spazio per miglioramenti nell’attuale algoritmo.
Questa ricerca introduce un umanoide ad alta dimensione chiamato HumanoidBenchControllo robotico segno di riferimento. Questo benchmark fornisce un ambiente umanoide completo che include una varietà di attività di locomozione e manipolazione, dai giocattoli alle applicazioni del mondo reale. Gli autori dell’articolo sperano che possa sfidare compiti così complessi e promuovere lo sviluppo di algoritmi per l’intero corpo dei robot umanoidi.
Negli studi futuri, sarà importante studiare le interazioni tra le diverse modalità di rilevamento. Inoltre, verrà presa in considerazione la combinazione di oggetti e ambienti più realistici con la varietà del mondo reale e un rendering di alta qualità. Inoltre, verrà posto l'accento su altri mezzi per indurre l'apprendimento in ambienti in cui è difficile raccogliere dimostrazioni fisiche.

Si dedica alla ricerca tecnologica da più di trent'anni, è esperto in vari linguaggi come java, linux, javascript, php, css, ecc., e ha apportato numerosi contributi nel campo dell'open source una stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro. Tutti la controllano

Posta[email protected]