私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
用紙のアドレス:https://arxiv.org/pdf/2403.10506
ヒューマノイドロボットは人間に似た外観を持ち、さまざまな環境や作業において人間をサポートすることが期待されています。ただし、高価で壊れやすいハードウェアがこの研究の課題です。そこで、本研究では高度なシミュレーション技術を用いてHumanoidBenchを開発しました。このベンチマークは、器用な両手操作や複雑な全身操作などのさまざまなタスクを含む、人型ロボットを使用したさまざまなアルゴリズムのパフォーマンスを評価します。研究結果によると、最先端の強化学習アルゴリズム多くのタスクでは困難を伴いますが、階層学習アルゴリズムは、歩くことや物体に触れるなどの基本的な動作ではより優れたパフォーマンスを発揮します。 HumanoidBench は、ロボット工学コミュニティがヒューマノイド ロボットが直面する課題に対処するための重要なツールであり、アルゴリズムとアイデアを迅速に検証するためのプラットフォームを提供します。
人型ロボットは私たちの日常生活にシームレスに溶け込むことが期待されています。ただし、その制御は特定のタスク用に手動で設計されており、新しいタスクには大規模なエンジニアリング作業が必要です。この問題に対処するために、私たちはヒューマノイド ロボットの学習を容易にする HumanoidBench と呼ばれるベンチマークを開発しました。これには、複雑な制御、物理的な調整、長期にわたる作業など、さまざまな課題が伴います。このプラットフォームはテストロボットです学習アルゴリズム安全で安価な環境を提供し、人間の日常業務に関連するさまざまなタスクが含まれます。 HumanoidBench は、さまざまなヒューマノイド ロボットやエンド エフェクター、15 の全身操作タスク、12 の移動タスクを簡単に組み込むことができます。これにより、最先端の RL アルゴリズムで人型ロボットの複雑なダイナミクスを制御できるようになり、将来の研究に方向性が与えられます。
深層強化学習 (RL) は、標準化されたシミュレーション ベンチマークの出現により急速に進歩しています。しかし、既存のロボット操作シミュレーション環境は、静的かつ短期的なスキルが中心であり、複雑な操作は含まれていません。対照的に、提案されているベンチマークは、さまざまな長期運用に焦点を当てています。ただし、ほとんどのベンチマークは特定のタスク向けに設計されており、その多くは簡略化されたモデルを使用しています。これには、実際のハードウェアに基づいた合成ベンチマークが必要です。
主要なロボット エージェントは、2 つの器用なシャドウ ハンドを備えた Unitree H1 人型ロボットです2。ロボットは MuJoCo を通じてシミュレートされます。シミュレートされた環境は、ロボットの状態、物体の状態、視覚的観察、全身の触覚センシングなどのさまざまな観察をサポートします。人型ロボットも位置制御によって制御できます。
人間と同様のタスクを実行するには、ロボットが周囲の環境を理解し、適切な行動をとれなければなりません。ただし、現実世界でロボットをテストすることは、コストと安全性の問題により困難です。したがって、シミュレーション環境はロボットを学習および制御するための重要なツールです。
HumanoidBench には、高次元の動作空間 (最大 61 個のアクチュエーター) を備えた 27 のタスクが含まれています。運動課題には、歩く、走るなどの基本的な動作が含まれます。操作タスクには、物体を押す、引く、持ち上げる、つかむなどの高度なタスクが含まれます。

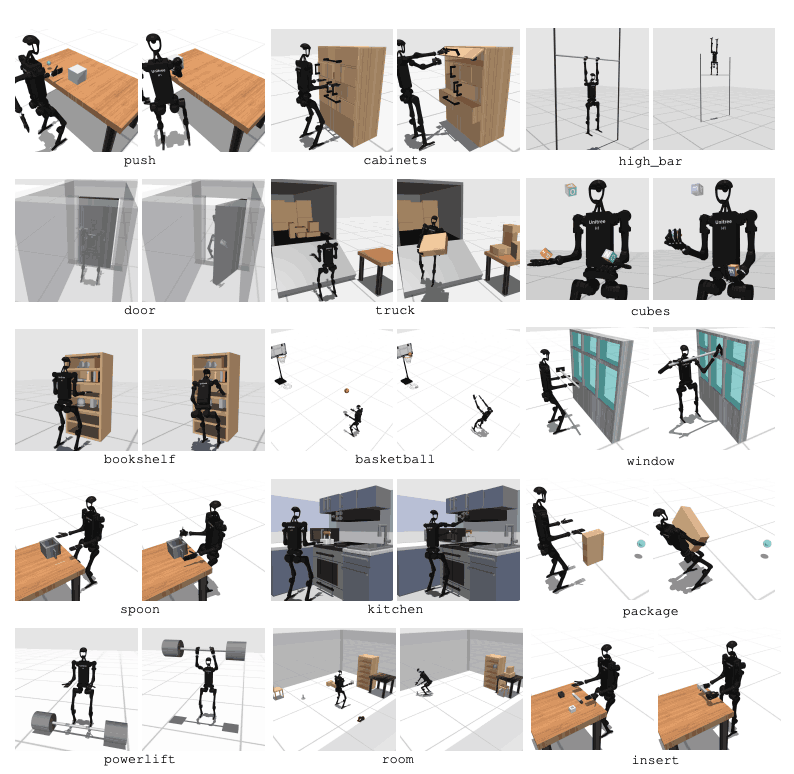
ベンチマークの目的は、最新のアルゴリズムがこれらのタスクをどの程度うまく達成できるかを評価することです。ロボットは環境の状態を観察し、それに応じて適切なアクションを選択する必要があります。報酬関数を通じて、ロボットはタスクを実行するための最適な戦略を学習できます。
たとえば、歩行タスクでは、ロボットは転倒することなく前進速度を維持する必要があります。この種の作業では、バランスと歩行を最適化することが非常に重要です。一方、操作タスクでは、ロボットは物体を正確に操作する必要があります。これには、オブジェクトの位置と方向の知識と、適切な力の制御が必要です。
HumanoidBench の目標は、これらのタスクを通じてロボットの学習と制御の分野を進歩させることです。シミュレートされた環境を使用すると、研究者は安全に実験を実施し、さまざまなシナリオでロボットのパフォーマンスを評価できます。これは、より優れた制御アルゴリズムと学習方法の開発に役立ち、それによって将来の人型ロボットの実世界への応用を促進します。
強化学習 (RL) アルゴリズムのパフォーマンスを評価して、学習タスクにおいてヒューマノイド ロボットが直面する課題を特定します。この目的には、DreamerV3、TD-MPC2、SAC、PPO など 4 つの主要な強化学習手法が使用されます。結果は、ベースライン アルゴリズムのパフォーマンスが多くのタスクで成功しきい値を下回っていることを示しています。
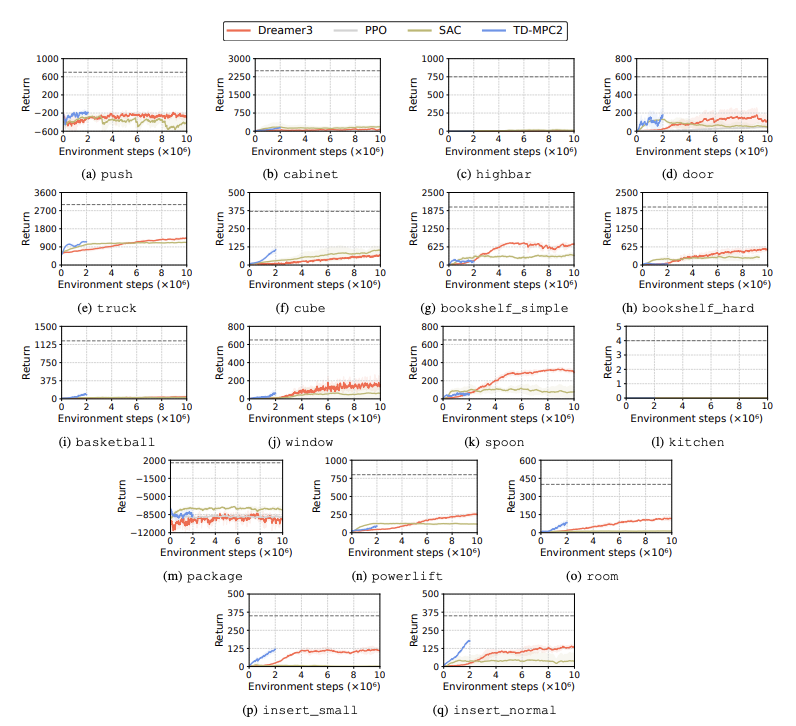
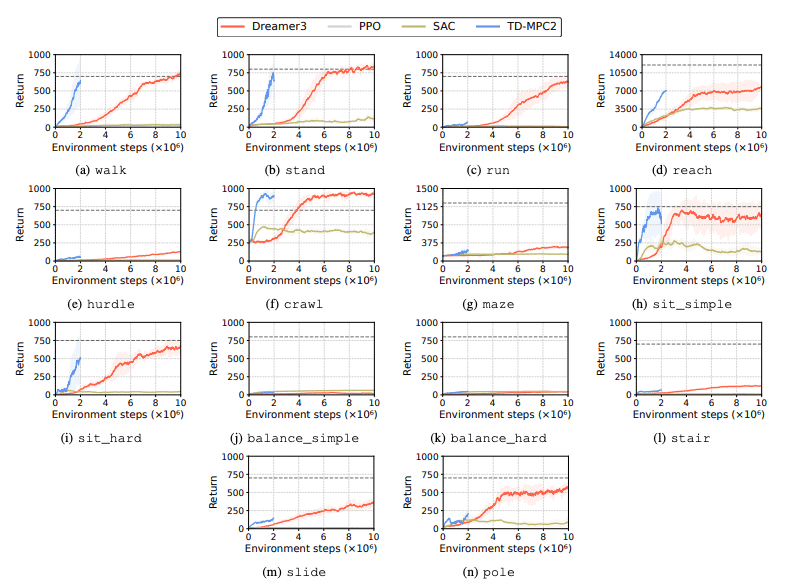
特に、現在の RL アルゴリズムは、高次元のアクション空間と複雑なタスクを処理するのに苦労しています。人型ロボットは、器用な手と複雑な体の調整を必要とするタスクを実行するのが特に困難です。これに加えて、操作タスクも特に困難であり、多くの場合報酬が低くなります。
よくある失敗は、ヒューマノイド ベンチマークが高いハードル、ゲート、障害物などのタスクにおいてロボットの予想される動作を学習するのに苦労することです。複雑な行動に適合する戦略を見つけるのが難しいためです。
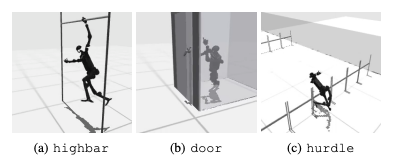
これらの課題に対処するために、階層型 RL アプローチが検討されています。低レベルのスキルをトレーニングし、それらを高レベルの計画戦略と組み合わせることで、タスクの解決が容易になります。ただし、現在のアルゴリズムにはまだ改善の余地があります。
この研究ではHumanoidBenchと呼ばれる高次元ヒューマノイドを導入します。ロボット制御基準。このベンチマークは、玩具から現実世界のアプリケーションに至るまで、さまざまな移動および操作タスクを含む包括的なヒューマノイド環境を提供します。論文の著者らは、この論文がそのような複雑なタスクに挑戦し、人型ロボットの全身アルゴリズムの開発を促進できることを期待している。
将来の研究では、異なるセンシングモダリティ間の相互作用を研究することが重要になるでしょう。さらに、より現実的なオブジェクトや環境を現実世界の多様性と高品質のレンダリングと組み合わせることが考慮されます。さらに、物理的なデモンストレーションを収集することが難しい環境で学習を誘導する他の手段にも重点が置かれます。

彼は 30 年以上テクノロジーの研究に専念しており、java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: