내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
논문 주소:한국어: https://arxiv.org/pdf/2403.10506
휴머노이드 로봇은 인간과 유사한 외형을 갖고 있어 다양한 환경과 작업에서 인간을 지원할 것으로 기대된다. 그러나 비싸고 깨지기 쉬운 하드웨어는 이 연구에 있어서 어려운 과제입니다. 이에 본 연구에서는 첨단 시뮬레이션 기술을 활용하여 HumanoidBench를 개발하였다. 이 벤치마크는 능숙한 양손 조작 및 복잡한 전신 조작과 같은 다양한 작업을 포함하여 휴머노이드 로봇을 사용하는 다양한 알고리즘의 성능을 평가합니다.연구 결과에 따르면 가장 진보된강화 학습 알고리즘 많은 작업에서 어려움을 겪는 반면, 계층적 학습 알고리즘은 걷거나 물체를 만지는 것과 같은 기본 동작에서 더 나은 성능을 발휘합니다. HumanoidBench는 휴머노이드 로봇이 직면한 문제를 해결하기 위해 로봇 커뮤니티에서 알고리즘과 아이디어를 신속하게 검증할 수 있는 플랫폼을 제공하는 중요한 도구입니다.
휴머노이드 로봇은 우리 일상생활에 원활하게 통합될 것으로 예상됩니다. 그러나 해당 컨트롤은 특정 작업을 위해 수동으로 설계되었으며 새로운 작업에는 광범위한 엔지니어링 작업이 필요합니다. 이 문제를 해결하기 위해 우리는 휴머노이드 로봇 학습을 용이하게 하는 HumanoidBench라는 벤치마크를 개발했습니다. 여기에는 복잡한 제어, 물리적 조정 및 장기 작업을 포함한 다양한 과제가 포함됩니다.이 플랫폼은 테스트 로봇입니다.학습 알고리즘 안전하고 저렴한 환경을 제공하며 일상적인 인간 업무와 관련된 다양한 작업을 포함합니다. HumanoidBench는 다양한 휴머노이드 로봇과 엔드 이펙터, 15가지 전신 조작 작업, 12가지 이동 작업을 쉽게 통합할 수 있습니다. 이를 통해 최첨단 RL 알고리즘을 통해 휴머노이드 로봇의 복잡한 역학을 제어하고 향후 연구 방향을 제시할 수 있습니다.
심층 강화 학습(RL)은 표준화된 시뮬레이션 벤치마크의 출현으로 빠르게 발전하고 있습니다. 그러나 기존 로봇 작동 시뮬레이션 환경은 주로 정적, 단기 기술에 중점을 두며 복잡한 작업을 포함하지 않습니다. 이와 대조적으로 제안된 벤치마크는 다양한 장기 운영에 중점을 둡니다. 그러나 대부분의 벤치마크는 특정 작업을 위해 설계되었으며 많은 벤치마크는 단순화된 모델을 사용합니다. 이를 위해서는 실제 하드웨어를 기반으로 한 합성 벤치마크가 필요합니다.
주요 로봇 에이전트는 두 개의 능숙한 그림자 손을 가진 Unitree H1 휴머노이드 로봇입니다2. MuJoCo를 통해 로봇을 시뮬레이션합니다. 시뮬레이션 환경은 로봇 상태, 물체 상태, 시각적 관찰, 전신 촉각 감지를 포함한 다양한 관찰을 지원합니다. 휴머노이드 로봇은 위치 제어를 통해 제어할 수도 있습니다.
인간과 유사한 작업을 수행하려면 로봇이 주변 환경을 이해하고 적절한 조치를 취할 수 있어야 합니다. 그러나 현실 세계에서 로봇을 테스트하는 것은 비용과 안전 문제로 인해 어렵습니다. 따라서 시뮬레이션 환경은 로봇을 학습하고 제어하는 데 중요한 도구입니다.
HumanoidBench에는 고차원 모션 공간(최대 61개의 액추에이터)이 있는 27개의 작업이 포함되어 있습니다. 운동 작업에는 걷기, 달리기와 같은 기본적인 움직임이 포함됩니다. 조작 작업에는 물체 밀기, 당기기, 들어 올리기, 잡기와 같은 고급 작업이 포함됩니다.

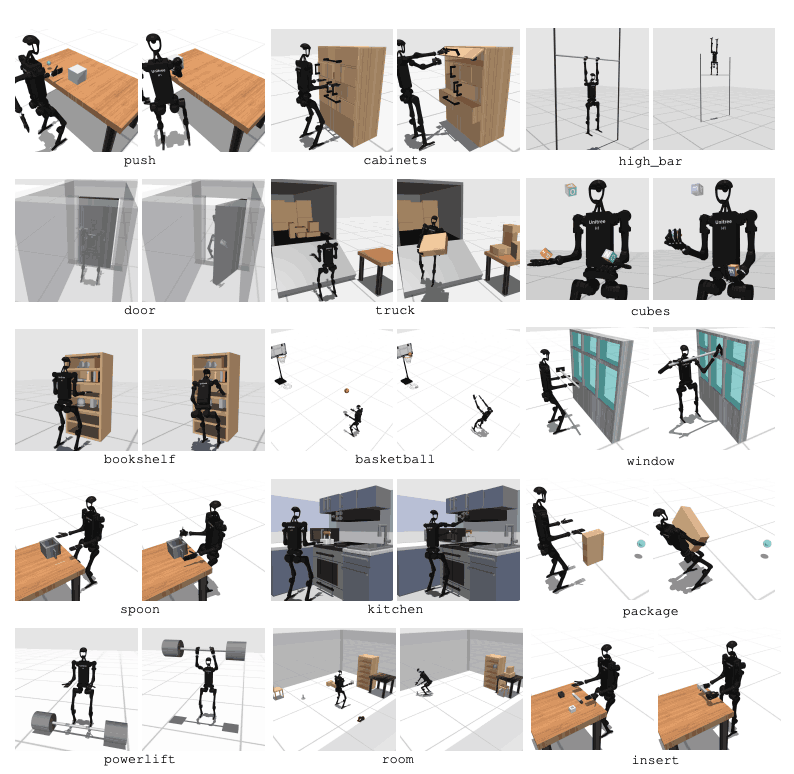
벤치마크의 목적은 최신 알고리즘이 이러한 작업을 얼마나 잘 수행할 수 있는지 평가하는 것입니다. 로봇은 환경 상태를 관찰하고 그에 따라 적절한 조치를 선택해야 합니다. 보상 기능을 통해 로봇은 작업을 수행하는 데 가장 적합한 전략을 학습할 수 있습니다.
예를 들어, 걷는 작업에서 로봇은 넘어지지 않고 전진 속도를 유지해야 합니다. 이러한 유형의 작업에서는 균형과 보행을 최적화하는 것이 매우 중요합니다. 반면에 조작 작업에서는 로봇이 물체를 정확하게 조작해야 합니다. 이를 위해서는 물체의 위치와 방향에 대한 지식과 적절한 힘 제어가 필요합니다.
HumanoidBench의 목표는 이러한 작업을 통해 로봇 학습 및 제어 분야를 발전시키는 것입니다. 시뮬레이션된 환경을 사용하여 연구원은 다양한 시나리오에서 안전하게 실험을 수행하고 로봇 성능을 평가할 수 있습니다. 이는 더 나은 제어 알고리즘과 학습 방법을 개발하는 데 도움이 될 것이며, 이를 통해 실제 세계에서 휴머노이드 로봇의 향후 적용을 촉진할 것입니다.
강화 학습(RL) 알고리즘의 성능은 학습 작업에서 휴머노이드 로봇이 직면한 과제를 식별하기 위해 평가됩니다. 이를 위해 DreamerV3, TD-MPC2, SAC 및 PPO를 포함한 네 가지 주요 강화 학습 방법이 사용됩니다. 결과는 기준 알고리즘이 많은 작업에서 성공 임계값 미만으로 수행된다는 것을 보여줍니다.
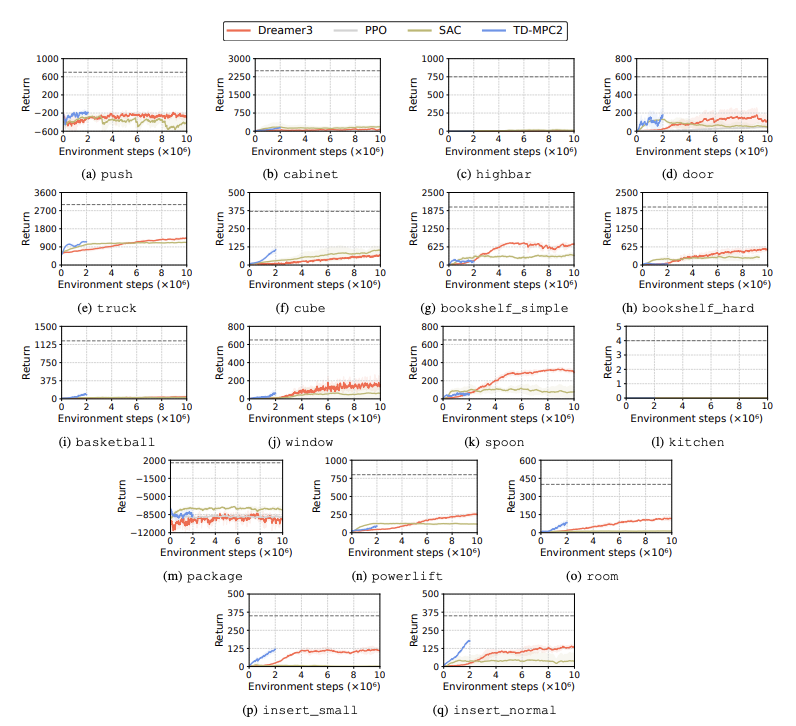
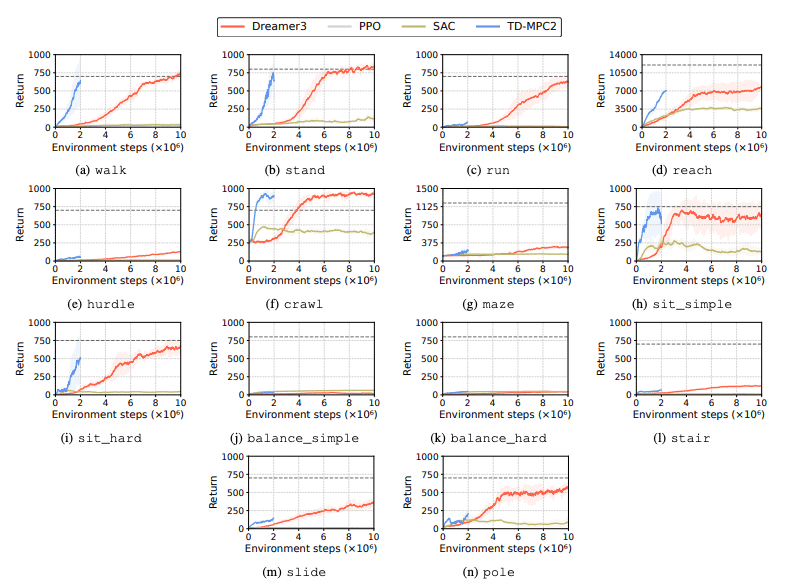
특히, 현재 RL 알고리즘은 고차원 행동 공간과 복잡한 작업을 처리하는 데 어려움을 겪고 있습니다. 특히 휴머노이드 로봇은 능숙한 손과 복잡한 신체 조정이 필요한 작업을 수행하는 데 어려움을 겪습니다. 이 외에도 조작 작업도 특히 어렵고 보상이 낮은 경우가 많습니다.
일반적인 실패는 휴머노이드 벤치마크가 높은 장애물, 게이트 및 장애물과 같은 작업에서 로봇의 예상 동작을 학습하는 데 어려움을 겪는다는 것입니다. 복잡한 행동에 맞는 전략을 찾기 어렵기 때문이다.
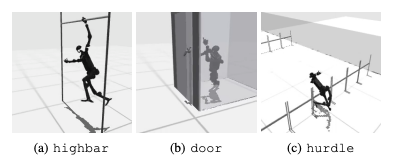
이러한 문제를 해결하기 위해 계층적 RL 접근 방식이 고려되고 있습니다. 낮은 수준의 기술을 훈련하고 이를 높은 수준의 계획 전략과 결합하면 작업 해결을 촉진할 수 있습니다. 그러나 현재 알고리즘에는 여전히 개선의 여지가 있습니다.
이번 연구에서는 HumanoidBench라는 고차원 휴머노이드를 소개합니다.로봇 제어 기준. 이 벤치마크는 장난감부터 실제 애플리케이션까지 다양한 이동 및 조작 작업을 포함하는 포괄적인 휴머노이드 환경을 제공합니다. 논문의 저자는 이러한 복잡한 작업에 도전하고 휴머노이드 로봇을 위한 전신 알고리즘 개발을 촉진할 수 있기를 희망합니다.
향후 연구에서는 다양한 감지 양식 간의 상호 작용을 연구하는 것이 중요할 것입니다. 또한 보다 사실적인 객체와 환경을 실제의 다양성과 고품질 렌더링과 결합하는 것도 고려됩니다. 또한 물리적 시연을 수집하기 어려운 환경에서는 학습을 유도하기 위한 다른 수단에 중점을 둘 것입니다.

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com