informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Alamat kertas:https://arxiv.org/pdf/2403.10506
Robot humanoid memiliki penampilan mirip manusia dan diharapkan dapat mendukung manusia dalam berbagai lingkungan dan tugas. Namun, perangkat keras yang mahal dan rapuh merupakan tantangan dalam penelitian ini. Oleh karena itu, penelitian ini mengembangkan HumanoidBench dengan menggunakan teknologi simulasi canggih. Tolok ukur ini mengevaluasi kinerja berbagai algoritma yang menggunakan robot humanoid, termasuk berbagai tugas seperti bimanual yang tangkas dan manipulasi seluruh tubuh yang kompleks.Hasil penelitian menunjukkan yang paling majualgoritma pembelajaran penguatan Ia kesulitan dalam banyak tugas, sementara algoritme pembelajaran hierarki bekerja lebih baik pada tindakan dasar seperti berjalan dan menyentuh objek. HumanoidBench adalah alat penting bagi komunitas robotika untuk mengatasi tantangan yang dihadapi robot humanoid, menyediakan platform untuk verifikasi algoritma dan ide secara cepat.
Robot humanoid diharapkan dapat berintegrasi dengan mulus ke dalam kehidupan kita sehari-hari. Namun, kontrolnya dirancang secara manual untuk tugas tertentu, dan tugas baru memerlukan pekerjaan teknis yang ekstensif. Untuk mengatasi masalah ini, kami mengembangkan benchmark yang disebut HumanoidBench untuk memfasilitasi pembelajaran robot humanoid. Hal ini melibatkan berbagai tantangan, termasuk kontrol yang kompleks, koordinasi fisik, dan tugas jangka panjang.Platform ini adalah robot ujialgoritma pembelajaran Menyediakan lingkungan yang aman, murah dan berisi berbagai tugas yang berkaitan dengan tugas manusia sehari-hari. HumanoidBench dapat dengan mudah menggabungkan berbagai robot humanoid dan efektor akhir, 15 tugas manipulasi seluruh tubuh, dan 12 tugas penggerak. Hal ini memungkinkan algoritme RL yang canggih untuk mengontrol dinamika kompleks robot humanoid dan memberikan arahan untuk penelitian di masa depan.
Pembelajaran penguatan mendalam (RL) berkembang pesat dengan munculnya tolok ukur simulasi standar. Namun, lingkungan simulasi operasi robot yang ada terutama berfokus pada keterampilan statis dan jangka pendek dan tidak melibatkan operasi yang rumit. Sebaliknya, tolok ukur yang diusulkan berfokus pada berbagai operasi jangka panjang. Namun, sebagian besar tolok ukur dirancang untuk tugas tertentu, dan banyak yang menggunakan model yang disederhanakan. Hal ini memerlukan tolok ukur sintetis berdasarkan perangkat keras nyata.
Agen robot utama adalah robot humanoid Unitree H1 dengan dua tangan bayangan yang cekatan2. Robot disimulasikan melalui MuJoCo. Lingkungan simulasi mendukung berbagai observasi, termasuk status robot, status objek, observasi visual, dan penginderaan sentuhan seluruh tubuh. Robot humanoid juga dapat dikontrol melalui kontrol posisi.
Untuk melakukan tugas serupa dengan manusia, robot harus mampu memahami lingkungannya dan mengambil tindakan yang tepat. Namun, pengujian robot di dunia nyata sulit dilakukan karena masalah biaya dan keamanan. Oleh karena itu, lingkungan simulasi merupakan alat penting untuk mempelajari dan mengendalikan robot.
HumanoidBench mencakup 27 tugas dengan ruang gerak berdimensi tinggi (hingga 61 aktuator). Tugas motorik meliputi gerakan dasar seperti berjalan dan berlari. Tugas manipulasi mencakup tugas-tugas tingkat lanjut seperti mendorong, menarik, mengangkat, dan menggenggam benda.

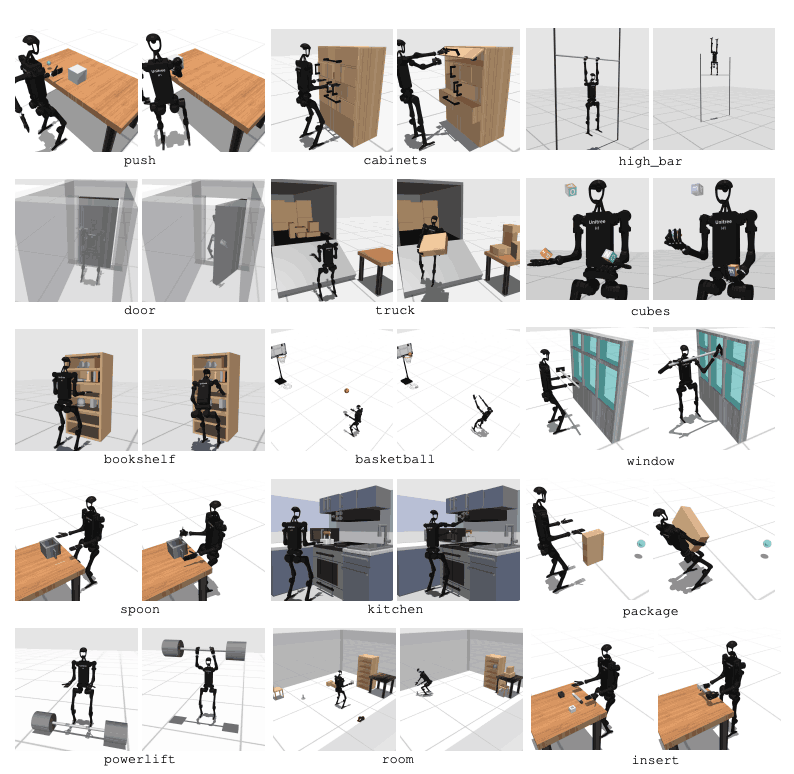
Tujuan dari benchmark ini adalah untuk mengevaluasi seberapa baik algoritma modern dapat menyelesaikan tugas-tugas ini. Robot perlu mengamati keadaan lingkungan dan memilih tindakan yang tepat. Melalui fungsi reward, robot dapat mempelajari strategi terbaik untuk melakukan tugasnya.
Misalnya, dalam tugas berjalan, robot harus mempertahankan kecepatan maju tanpa terjatuh. Mengoptimalkan keseimbangan dan gaya berjalan sangat penting dalam tugas semacam ini. Sebaliknya, dalam tugas manipulasi, robot perlu memanipulasi objek dengan tepat. Hal ini memerlukan pengetahuan tentang posisi dan orientasi objek serta pengendalian gaya yang tepat.
Tujuan dari HumanoidBench adalah untuk memajukan bidang pembelajaran dan kontrol robotik melalui tugas-tugas ini. Dengan menggunakan lingkungan simulasi, peneliti dapat dengan aman melakukan eksperimen dan mengevaluasi kinerja robot dalam berbagai skenario berbeda. Hal ini akan membantu mengembangkan algoritma kontrol dan metode pembelajaran yang lebih baik, sehingga mendorong penerapan robot humanoid di dunia nyata di masa depan.
Kinerja algoritma pembelajaran penguatan (RL) dievaluasi untuk mengidentifikasi tantangan yang dihadapi robot humanoid dalam tugas pembelajaran. Empat metode pembelajaran penguatan utama digunakan untuk tujuan ini, termasuk DreamerV3, TD-MPC2, SAC dan PPO. Hasilnya menunjukkan bahwa algoritma dasar bekerja di bawah ambang batas keberhasilan pada banyak tugas.
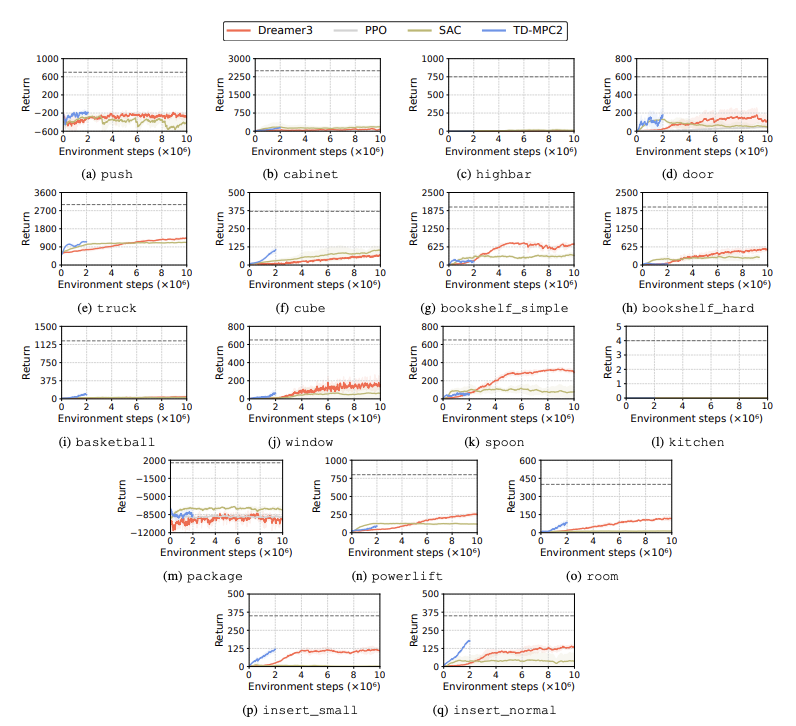
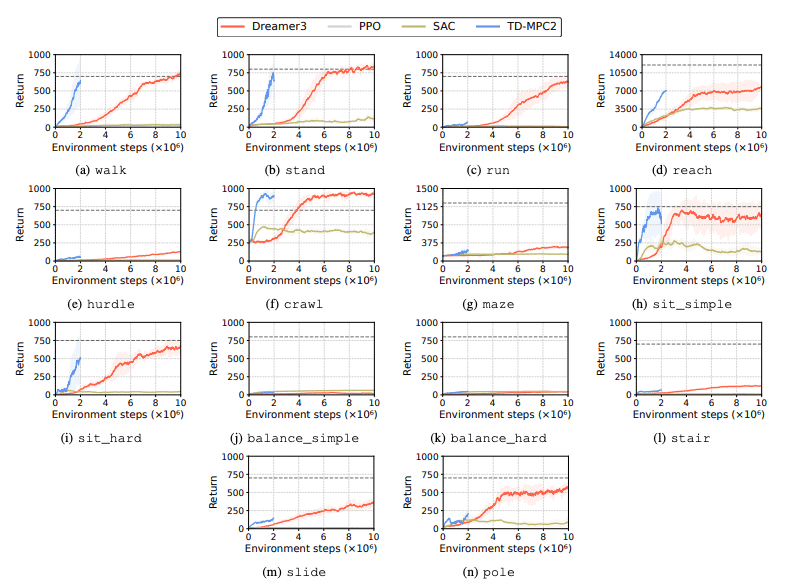
Secara khusus, algoritme RL saat ini kesulitan menangani ruang tindakan berdimensi tinggi dan tugas kompleks. Robot humanoid khususnya mengalami kesulitan dalam melakukan tugas yang membutuhkan tangan cekatan dan koordinasi tubuh yang rumit. Selain itu, tugas manipulasi juga sangat menantang dan sering kali memberikan imbalan yang lebih rendah.
Kegagalan yang umum terjadi adalah tolok ukur humanoid kesulitan mempelajari perilaku robot yang diharapkan dalam tugas-tugas seperti rintangan tinggi, gerbang, dan rintangan. Hal ini karena sulitnya menemukan strategi yang sesuai dengan perilaku kompleks.
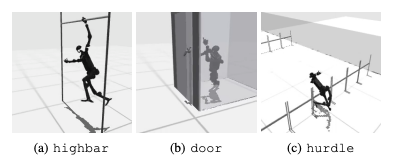
Untuk mengatasi tantangan ini, pendekatan RL hierarki sedang dipertimbangkan. Melatih keterampilan tingkat rendah dan menggabungkannya dengan strategi perencanaan tingkat tinggi dapat memfasilitasi penyelesaian tugas. Namun, masih ada ruang untuk perbaikan pada algoritma saat ini.
Penelitian ini memperkenalkan humanoid berdimensi tinggi yang disebut HumanoidBenchKontrol robot tolok ukur. Tolok ukur ini menyediakan lingkungan humanoid yang komprehensif termasuk berbagai tugas penggerak dan manipulasi mulai dari mainan hingga aplikasi dunia nyata. Penulis makalah ini berharap makalah ini dapat menantang tugas-tugas rumit tersebut dan mendorong pengembangan algoritma seluruh tubuh untuk robot humanoid.
Dalam penelitian selanjutnya, penting untuk mempelajari interaksi antara modalitas penginderaan yang berbeda. Selain itu, pertimbangan akan diberikan untuk menggabungkan objek dan lingkungan yang lebih realistis dengan variasi dunia nyata dan rendering berkualitas tinggi. Selain itu, akan ada penekanan pada cara lain untuk mendorong pembelajaran di lingkungan yang sulit untuk mengumpulkan demonstrasi fisik.

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]