2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Paperiosoite:https://arxiv.org/pdf/2403.10506
Humanoidirobotit näyttävät ihmiseltä, ja niiden odotetaan tukevan ihmisiä erilaisissa ympäristöissä ja tehtävissä. Kuitenkin kallis ja hauras laitteisto on haaste tälle tutkimukselle. Siksi tässä tutkimuksessa kehitettiin HumanoidBench käyttämällä edistynyttä simulointitekniikkaa. Tämä vertailuarvo arvioi eri algoritmien suorituskykyä humanoidirobottien avulla, mukaan lukien erilaisia tehtäviä, kuten taitava bimanuaalinen ja monimutkainen koko kehon manipulointi.Tutkimustulokset osoittavat, että pisimmällävahvistusoppimisalgoritmi Se kamppailee monissa tehtävissä, kun taas hierarkkiset oppimisalgoritmit suoriutuvat paremmin perustoiminnoista, kuten kävelystä ja esineiden kosketuksesta. HumanoidBench on robotiikkayhteisön tärkeä työkalu humanoidirobottien kohtaamien haasteiden ratkaisemiseksi, ja se tarjoaa alustan algoritmien ja ideoiden nopealle todentamiselle.
Humanoidirobottien odotetaan integroituvan saumattomasti jokapäiväiseen elämäämme. Niiden ohjaimet on kuitenkin suunniteltu manuaalisesti tiettyjä tehtäviä varten, ja uudet tehtävät vaativat laajaa suunnittelutyötä. Tämän ongelman ratkaisemiseksi kehitimme HumanoidBench-nimisen vertailuarvon helpottamaan humanoidirobottien oppimista. Tämä sisältää useita haasteita, mukaan lukien monimutkaiset kontrollit, fyysinen koordinaatio ja pitkän aikavälin tehtävät.Tämä alusta on testirobottioppimisalgoritmi Tarjoaa turvallisen, edullisen ympäristön ja sisältää erilaisia päivittäisiin ihmisen tehtäviin liittyviä tehtäviä. HumanoidBench voi helposti yhdistää erilaisia humanoidirobotteja ja päätetehosteita, 15 koko kehon manipulointitehtävää ja 12 liikkumistehtävää. Tämä mahdollistaa huippuluokan RL-algoritmien ohjaamisen humanoidirobottien monimutkaisen dynamiikan ohjaamiseen ja antaa suunnan tulevalle tutkimukselle.
Syvävahvistusoppiminen (RL) edistyy nopeasti standardisoitujen simulointibenchmarkien myötä. Nykyiset robotin toiminnan simulointiympäristöt keskittyvät kuitenkin pääasiassa staattisiin, lyhytaikaisiin taitoihin, eivätkä ne sisällä monimutkaisia toimintoja. Sitä vastoin ehdotetut vertailuarvot keskittyvät erilaisiin pitkän aikavälin toimintoihin. Useimmat vertailuarvot on kuitenkin suunniteltu tiettyjä tehtäviä varten, ja monet käyttävät yksinkertaistettuja malleja. Tämä vaatii synteettisiä vertailuarvoja, jotka perustuvat todelliseen laitteistoon.
Päärobottiagentti on Unitree H1 humanoidirobotti, jossa on kaksi taitavaa varjokättä2. Robottia simuloidaan MuJoCo:n kautta. Simuloitu ympäristö tukee useita havaintoja, mukaan lukien robotin tila, objektin tila, visuaaliset havainnot ja koko kehon tuntotunnistus. Humanoidirobotteja voidaan ohjata myös asennonohjauksella.
Ihmisen kaltaisten tehtävien suorittamiseksi robotin on kyettävä ymmärtämään ympäristönsä ja toimimaan asianmukaisesti. Robottien testaus todellisessa maailmassa on kuitenkin vaikeaa kustannus- ja turvallisuussyistä. Siksi simulaatioympäristöt ovat tärkeitä työkaluja robottien oppimiseen ja ohjaamiseen.
HumanoidBench sisältää 27 tehtävää, joissa on korkeatasoinen liiketila (jopa 61 toimilaitetta). Moottoritehtäviin kuuluvat perusliikkeet, kuten kävely ja juoksu. Manipulointitehtävät sisältävät edistyneitä tehtäviä, kuten työntäminen, vetäminen, nosto ja tarttuminen esineisiin.

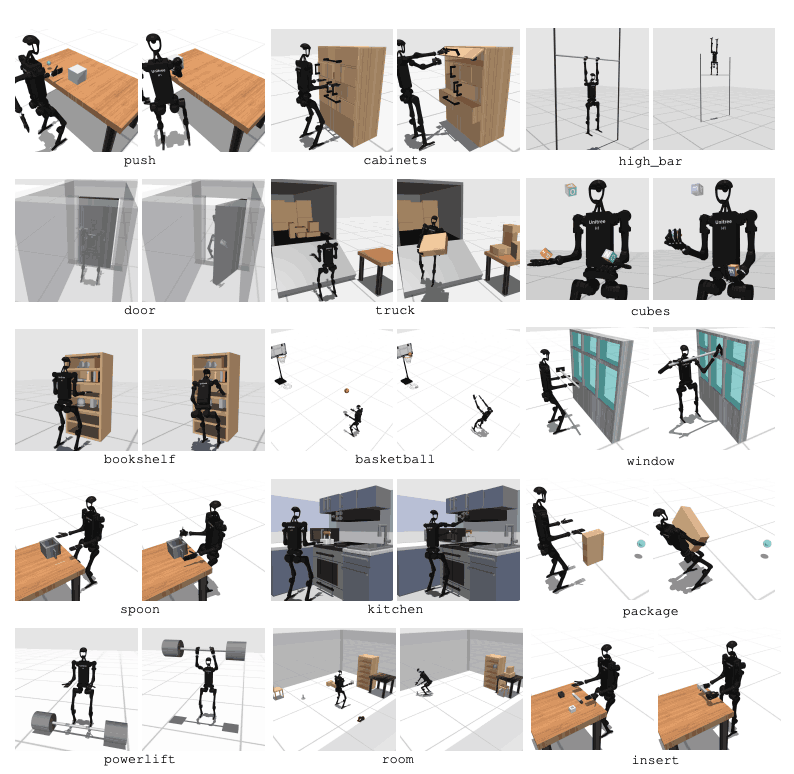
Vertailuarvon tarkoituksena on arvioida, kuinka hyvin nykyaikaiset algoritmit voivat suorittaa nämä tehtävät. Robotin tulee tarkkailla ympäristön tilaa ja valita sopivat toimenpiteet sen mukaan. Palkitsemistoiminnon kautta robotti voi oppia parhaan strategian tehtävän suorittamiseen.
Esimerkiksi kävelytehtävässä robotin on säilytettävä eteenpäinnopeus ilman kaatumista. Tasapainon ja kävelyn optimointi on erittäin tärkeää tämän tyyppisissä tehtävissä. Toisaalta manipulointitehtävissä robotin täytyy käsitellä esineitä tarkasti. Tämä vaatii tietoa kohteen sijainnista ja suunnasta sekä asianmukaista voimanhallintaa.
HumanoidBenchin tavoitteena on edistää robotin oppimisen ja ohjauksen alaa näiden tehtävien kautta. Simuloitujen ympäristöjen avulla tutkijat voivat turvallisesti tehdä kokeita ja arvioida robotin suorituskykyä monissa eri skenaarioissa. Tämä auttaa kehittämään parempia ohjausalgoritmeja ja oppimismenetelmiä, mikä edistää humanoidirobottien tulevaa soveltamista todellisessa maailmassa.
Vahvistusoppimisalgoritmien (RL) suorituskykyä arvioidaan humanoidirobottien kohtaamien haasteiden tunnistamiseksi oppimistehtävissä. Tähän tarkoitukseen käytetään neljää pääasiallista vahvistusoppimismenetelmää, mukaan lukien DreamerV3, TD-MPC2, SAC ja PPO. Tulokset osoittavat, että perusalgoritmi toimii onnistumisrajan alapuolella monissa tehtävissä.
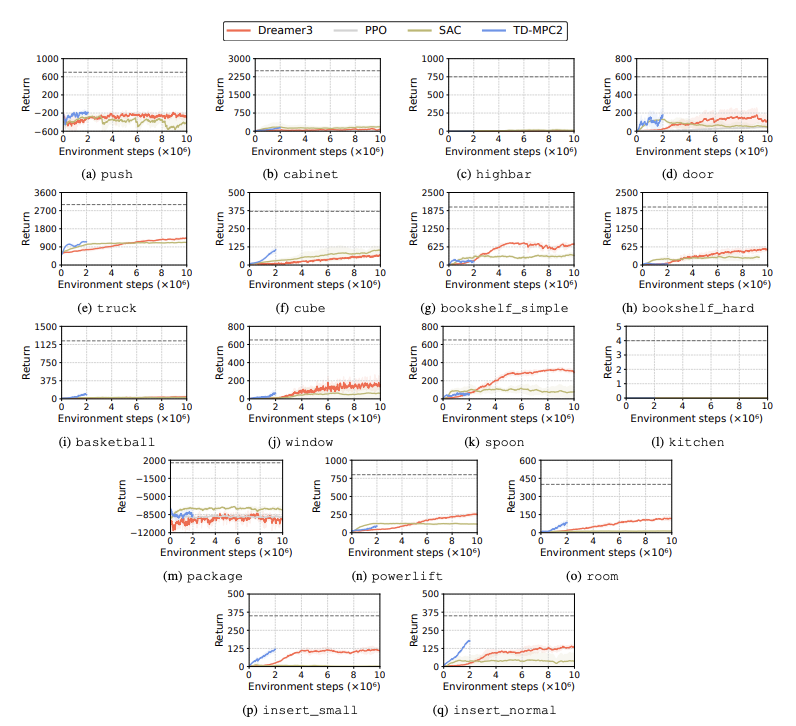
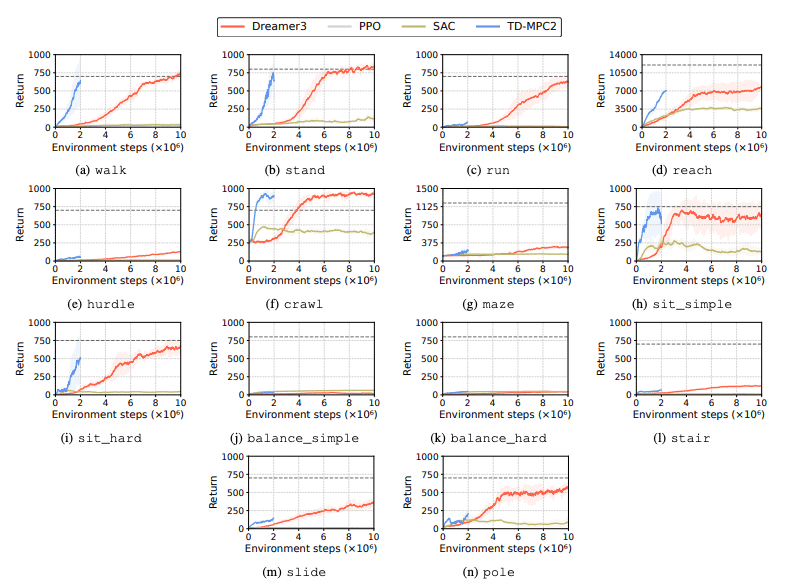
Erityisesti nykyiset RL-algoritmit kamppailevat käsitelläkseen suuriulotteisia toimintatiloja ja monimutkaisia tehtäviä. Humanoidirobottien on erityisesti vaikea suorittaa tehtäviä, jotka vaativat taitavia käsiä ja monimutkaista kehon koordinaatiota. Tämän lisäksi manipulointitehtävät ovat myös erityisen haastavia ja niistä saa usein vähemmän palkkioita.
Yleinen epäonnistuminen on se, että humanoidivertailutesteillä on vaikeuksia oppia robottien odotettua käyttäytymistä tehtävissä, kuten korkeissa esteissä, porteissa ja esteissä. Tämä johtuu siitä, että on vaikea löytää strategioita, jotka sopivat monimutkaiseen käyttäytymiseen.
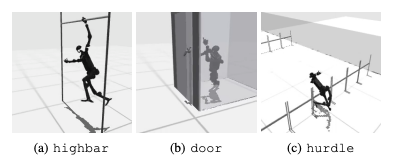
Näiden haasteiden ratkaisemiseksi harkitaan hierarkkista RL-lähestymistapaa. Matalan tason taitojen kouluttaminen ja niiden yhdistäminen korkean tason suunnittelustrategioihin voi helpottaa tehtävien ratkaisua. Nykyisessä algoritmissa on kuitenkin vielä parantamisen varaa.
Tämä tutkimus esittelee korkean ulottuvuuden humanoidin nimeltä HumanoidBenchRobotin ohjaus benchmark. Tämä vertailukohta tarjoaa kattavan humanoidiympäristön, joka sisältää erilaisia liikkumis- ja manipulointitehtäviä leluista tosielämän sovelluksiin. Paperin kirjoittajat toivovat, että se voi haastaa tällaiset monimutkaiset tehtävät ja edistää koko kehon algoritmien kehittämistä humanoidiroboteille.
Tulevissa tutkimuksissa on tärkeää tutkia eri tunnistusmodaliteettien välisiä vuorovaikutuksia. Lisäksi harkitaan realistisempien kohteiden ja ympäristöjen yhdistämistä todelliseen monipuolisuuteen ja laadukkaaseen renderöintiin. Lisäksi painotetaan muita tapoja kannustaa oppimista ympäristöissä, joissa fyysisten demonstraatioiden kerääminen on vaikeaa.

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema, jossa voit jakaa joitakin teknologian kehittämisen ongelmia myöhempää käyttöä varten
