2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

In diesem Experiment wird hauptsächlich die Verwendung von MindSpore zur Durchführung von KNN-Experimenten an einigen Weindatensätzen vorgestellt.
K-Nearest-Neighbor (KNN) ist eine nichtparametrische statistische Methode zur Klassifizierung und Regression, die ursprünglich 1968 von Cover und Hart vorgeschlagen wurde (Cover et al., 1967 ) ist einer der grundlegendsten Algorithmen des maschinellen Lernens. Es basiert auf der obigen Idee: Um die Kategorie einer Stichprobe zu bestimmen, können Sie deren Abstand zu allen Trainingsstichproben berechnen, dann die k Stichproben finden, die der Stichprobe am nächsten liegen, die Kategorien dieser Stichproben zählen und abstimmen die meisten Stimmen Diese Klasse ist das Ergebnis der Klassifizierung. Drei Grundelemente von KNN:
K-Wert, die Klassifizierung einer Stichprobe wird durch die „Mehrheitsstimme“ von K Nachbarn bestimmt. Je kleiner der K-Wert ist, desto leichter kann er durch Rauschen beeinflusst werden. Im Gegenteil, die Grenzen zwischen den Kategorien verschwimmen.
Das Abstandsmaß spiegelt die Ähnlichkeit zwischen zwei Stichproben im Merkmalsraum wider. Je kleiner der Abstand, desto ähnlicher sind sie. Zu den häufig verwendeten gehören die Lp-Distanz (wenn p=2 ist es die euklidische Distanz), die Manhattan-Distanz, die Hamming-Distanz usw.
Klassifizierungsentscheidungsregeln, normalerweise Mehrheitsentscheidung oder Mehrheitsentscheidung basierend auf der Distanzgewichtung (Gewichte sind umgekehrt proportional zur Distanz).
Nichtparametrische statistische Methoden beziehen sich auf statistische Methoden, die nicht auf parametrischen Formen beruhen (wie die Normalverteilungsannahme in der traditionellen Statistik usw.), das heißt, sie treffen keine strengen Annahmen über die Datenverteilung. Im Vergleich zu parametrischen statistischen Methoden (wie lineare Regression, t-Test usw.) sind nichtparametrische statistische Methoden flexibler, da sie nicht davon ausgehen, dass die Daten einem bestimmten Verteilungsmuster folgen.
Parametrische statistische Methoden basieren auf spezifischen Annahmen und Anforderungen für die Datenverteilung und verwenden bestimmte Parameter, um die Verteilungsform der Daten zu beschreiben. Diese parametrischen Formen können Modelle und Analysen erheblich vereinfachen, erfordern aber auch, dass diese Annahmen und Parameter mit den tatsächlichen Daten übereinstimmen, was zu irreführenden Schlussfolgerungen führen kann, wenn die Annahmen nicht erfüllt sind.
1. Lineare Regression:
Annahme: Es besteht ein linearer Zusammenhang zwischen der abhängigen Variablen (Antwortvariable) und der unabhängigen Variablen (erklärende Variable).
Parameter: Regressionskoeffizienten (Steigung und Achsenabschnitt), normalerweise unter der Annahme, dass der Fehlerterm einen Mittelwert von Null, eine konstante Varianz (Homoskedastizität) und eine Normalverteilung aufweist.
2. Logistische Regression:
Annahme: Die abhängige Variable (kategoriale Variable) erfüllt das logistische Regressionsmodell und der Regressionskoeffizient ist ein fester Wert.
Parameter: Regressionskoeffizient, der zur Beschreibung des Einflusses unabhängiger Variablen auf abhängige Variablen verwendet wird und durch Maximum-Likelihood-Schätzung geschätzt wird.
3. t-Test:
Annahme: Die Stichprobendaten stammen aus einer normalverteilten Grundgesamtheit.
Parameter: Mittelwert und Varianz, der T-Test bei einer Stichprobe geht vom Mittelwert der Grundgesamtheit aus, der T-Test bei zwei Stichproben geht von der Differenz zwischen den Mittelwerten zweier Grundgesamtheiten aus.
Der Prozess des Vorhersagealgorithmus (Klassifizierung) ist wie folgt:
(1) Finden Sie die k Stichproben, die der Teststichprobe x_test im Trainingsstichprobensatz am nächsten liegen, und speichern Sie sie im Satz N;
(2)统计集合N中每一类样本的个数𝐶𝑖,𝑖=1,2,3,...,𝑐;
(3)最终的分类结果为argmax𝐶𝑖 (最大的对应的𝐶𝑖)那个类。
Im obigen Implementierungsprozess ist der Wert von k besonders wichtig. Sie kann anhand von Problem- und Datenmerkmalen ermittelt werden. In der spezifischen Implementierung kann das Gewicht der Stichprobe berücksichtigt werden, das heißt, jede Stichprobe hat ein anderes Abstimmungsgewicht. Diese Methode wird als gewichteter k-nächster-Nachbarn-Algorithmus bezeichnet, der eine Variante des k-nächsten-Nachbarn-Algorithmus ist.
假设离测试样本最近的k个训练样本的标签值为𝑦𝑖,则对样本的回归预测输出值为:

Das ist der mittlere Labelwert aller Nachbarn.
Die Regressionsvorhersagefunktion mit Stichprobengewichten lautet:

其中𝑤𝑖为第个𝑖样本的权重。
KNN算法的实现依赖于样本之间的距离,其中最常用的距离函数就是欧氏距离(欧几里得距离)。ℝ𝑛空间中的两点𝑥和𝑦,它们之间的欧氏距离定义为:
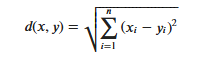
Es ist zu beachten, dass bei Verwendung des euklidischen Abstands jede Komponente des Merkmalsvektors normalisiert werden sollte, um die durch die unterschiedlichen Skalenbereiche der Merkmalswerte verursachten Interferenzen zu verringern. Andernfalls werden Merkmalskomponenten mit kleinen Werten durch Merkmale mit großen ersetzt Charakteristische Komponenten sind untergetaucht.
Andere Entfernungsberechnungsmethoden umfassen die Mahalanobis-Entfernung, die Bhattacharyya-Entfernung usw.
Vorkenntnisse:
Laborumgebung:
Der Wine-Datensatz ist einer der bekanntesten Datensätze zur Mustererkennung. Die offizielle Website des Wine-Datensatzes:Weindatensatz . Die Daten sind das Ergebnis einer chemischen Analyse von Weinen aus derselben Region Italiens, aber aus drei verschiedenen Sorten. Der Datensatz analysiert die Mengen von 13 Zutaten, die in jedem der drei Weine enthalten sind.Diese 13 Attribute sind
| Schlüssel | Wert | Schlüssel | Wert |
|---|---|---|---|
| Datensatzmerkmale: | Multivariat | Anzahl der Instanzen: | 178 |
| Attributeigenschaften: | Ganze Zahl, reelle Zahl | Anzahl der Attribute: | 13 |
| Zugehörige Aufgaben: | Einstufung | Fehlende Werte? | NEIN |
- %%capture captured_output
- # 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
- !pip uninstall mindspore -y
- !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
- # 查看当前 mindspore 版本
- !pip show mindspore
Name: mindspore Version: 2.2.14 Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Home-page: https://www.mindspore.cn Author: The MindSpore Authors Author-email: [email protected] License: Apache 2.0 Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy Required-by:
- from download import download
-
- # 下载红酒数据集
- url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
- path = download(url, "./", kind="zip", replace=True)
Downloading data from https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip (4 kB) file_sizes: 100%|██████████████████████████| 4.09k/4.09k [00:00<00:00, 2.51MB/s] Extracting zip file... Successfully downloaded / unzipped to ./
Importieren Sie vor dem Generieren von Daten die erforderlichen Python-Bibliotheken.
Derzeit wird die Betriebssystembibliothek verwendet. Um das Verständnis zu erleichtern, werden wir andere erforderliche Bibliotheken erläutern, wenn sie konkret verwendet werden.
Detaillierte Beschreibungen des MindSpore-Moduls können auf der MindSpore-API-Seite durchsucht werden.
Sie können die für den Betrieb erforderlichen Informationen über context.set_context konfigurieren, z. B. Betriebsmodus, Backend-Informationen, Hardware und andere Informationen.
Importieren Sie das Kontextmodul und konfigurieren Sie die für den Betrieb erforderlichen Informationen.
- %matplotlib inline
- import os
- import csv
- import numpy as np
- import matplotlib.pyplot as plt
-
- import mindspore as ms
- from mindspore import nn, ops
-
- ms.set_context(device_target="CPU")

wine.data, und zeigen Sie einige Daten an.- with open('wine.data') as csv_file:
- data = list(csv.reader(csv_file, delimiter=','))
- print(data[56:62]+data[130:133])
[['1', '14.22', '1.7', '2.3', '16.3', '118', '3.2', '3', '.26', '2.03', '6.38', '.94', '3.31', '970'], ['1', '13.29', '1.97', '2.68', '16.8', '102', '3', '3.23', '.31', '1.66', '6', '1.07', '2.84', '1270'], ['1', '13.72', '1.43', '2.5', '16.7', '108', '3.4', '3.67', '.19', '2.04', '6.8', '.89', '2.87', '1285'], ['2', '12.37', '.94', '1.36', '10.6', '88', '1.98', '.57', '.28', '.42', '1.95', '1.05', '1.82', '520'], ['2', '12.33', '1.1', '2.28', '16', '101', '2.05', '1.09', '.63', '.41', '3.27', '1.25', '1.67', '680'], ['2', '12.64', '1.36', '2.02', '16.8', '100', '2.02', '1.41', '.53', '.62', '5.75', '.98', '1.59', '450'], ['3', '12.86', '1.35', '2.32', '18', '122', '1.51', '1.25', '.21', '.94', '4.1', '.76', '1.29', '630'], ['3', '12.88', '2.99', '2.4', '20', '104', '1.3', '1.22', '.24', '.83', '5.4', '.74', '1.42', '530'], ['3', '12.81', '2.31', '2.4', '24', '98', '1.15', '1.09', '.27', '.83', '5.7', '.66', '1.36', '560']]
- X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
- Y = np.array([s[0] for s in data[:178]], np.int32)
- attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
- 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
- 'OD280/OD315 of diluted wines', 'Proline']
- plt.figure(figsize=(10, 8))
- for i in range(0, 4):
- plt.subplot(2, 2, i+1)
- a1, a2 = 2 * i, 2 * i + 1
- plt.scatter(X[:59, a1], X[:59, a2], label='1')
- plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
- plt.scatter(X[130:, a1], X[130:, a2], label='3')
- plt.xlabel(attrs[a1])
- plt.ylabel(attrs[a2])
- plt.legend()
- plt.show()
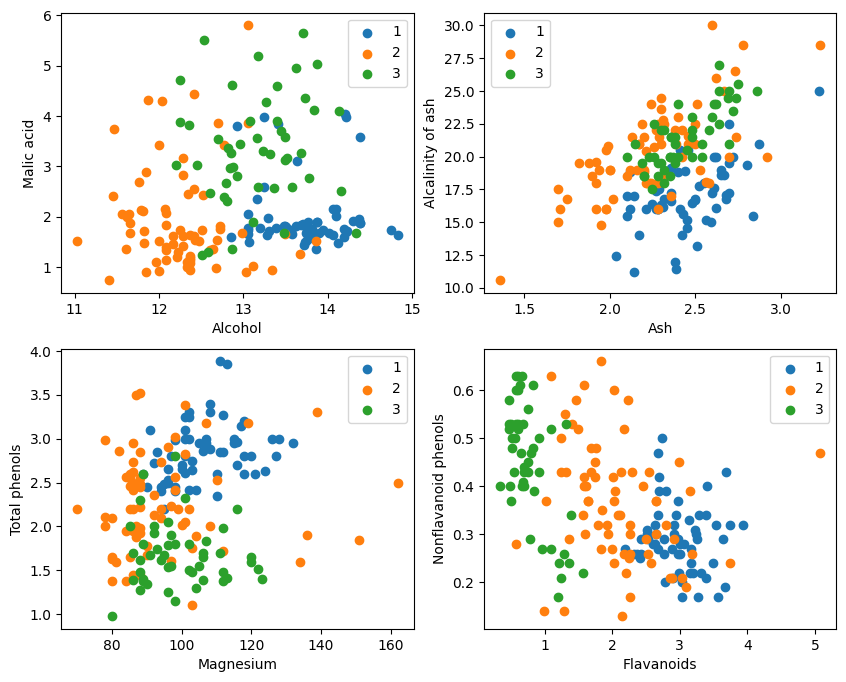
Aus der grafischen Darstellung sind die beiden Attributklassifizierungseffekte in der oberen linken Ecke und der unteren rechten Ecke des Diagramms relativ gut, insbesondere sind die Grenzen zwischen den Kategorien 1 und 2 relativ offensichtlich.
- train_idx = np.random.choice(178, 128, replace=False)
- test_idx = np.array(list(set(range(178)) - set(train_idx)))
- X_train, Y_train = X[train_idx], Y[train_idx]
- X_test, Y_test = X[test_idx], Y[test_idx]
Gibt test_idx zurück = np.array(list(set(range(178)) - set(train_idx)))
1. range(178) generiert eine Folge von Ganzzahlen von 0 bis 177.
2. set(range(178)) wandelt diese Folge von ganzen Zahlen in eine Menge um. Eine Menge ist eine Datenstruktur, die keine wiederholten Elemente zulässt und effiziente Mengenoperationen (wie Vereinigung, Schnittmenge, Differenz usw.) unterstützt.
3. set(train_idx) konvertiert die zufällig ausgewählte Trainingssatz-Indexliste train_idx in einen Satz.
4. set(range(178)) – set(train_idx) berechnet die Differenzmengenoperation der Menge und erhält die Elemente, die in set(range(178)), aber nicht in set(train_idx) sind, die die Indizes der Menge sind Testsatz. Dies ist eine Mengenoperation, mit der die Differenzelemente schnell und effizient berechnet werden können.
5. list(...) wandelt das Ergebnis der Differenzoperation zurück in eine Liste.
6. np.array(...) konvertiert diese Liste in ein Numpy-Array zur Indizierung mit den Numpy-Arrays X und Y。
Nutzen Sie die Angebote von MindSporetile, square, ReduceSum, sqrt, TopKund andere Operatoren berechnen gleichzeitig den Abstand zwischen der Eingabeprobe x und anderen klar klassifizierten Proben X_train durch Matrixoperationen und berechnen die obersten k nächsten Nachbarn
- class KnnNet(nn.Cell):
- def __init__(self, k):
- super(KnnNet, self).__init__()
- self.k = k
-
- def construct(self, x, X_train):
- #平铺输入x以匹配X_train中的样本数
- x_tile = ops.tile(x, (128, 1))
- square_diff = ops.square(x_tile - X_train)
- square_dist = ops.sum(square_diff, 1)
- dist = ops.sqrt(square_dist)
- #-dist表示值越大,样本就越接近
- values, indices = ops.topk(-dist, self.k)
- return indices
-
- def knn(knn_net, x, X_train, Y_train):
- x, X_train = ms.Tensor(x), ms.Tensor(X_train)
- indices = knn_net(x, X_train)
- topk_cls = [0]*len(indices.asnumpy())
- for idx in indices.asnumpy():
- topk_cls[Y_train[idx]] += 1
- cls = np.argmax(topk_cls)
- return cls
1. Definieren Sie die KNN-Netzwerkklasse: KnnNet
__init__-Funktion: Initialisieren Sie das Netzwerk und legen Sie den K-Wert fest (dh die Anzahl der ausgewählten nächsten Nachbarn).
Konstruktfunktion: Berechnen Sie den euklidischen Abstand zwischen der Eingabeprobe x und jeder Probe im Trainingssatz X_train und geben Sie den Index der k (dh nächsten Nachbarn) Proben mit dem kleinsten Abstand zurück.
2. Definieren Sie die KNN-Funktion: knn
Empfängt knn_net (KNN-Netzwerkinstanz), Testbeispiel x, Trainingsbeispiel X_train und Trainingslabel Y_train als Eingabe.
Verwenden Sie knn_net, um die k nächsten Nachbarstichproben von x zu finden, sie anhand der Beschriftungen dieser Stichproben zu klassifizieren und das Klassifizierungsergebnis (d. h. die vorhergesagte Kategorie) zurückzugeben.
在验证集上验证KNN算法的有效性,取𝑘=5,验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
- acc = 0
- knn_net = KnnNet(5)
- for x, y in zip(X_test, Y_test):
- pred = knn(knn_net, x, X_train, Y_train)
- acc += (pred == y)
- print('label: %d, prediction: %s' % (y, pred))
- print('Validation accuracy is %f' % (acc/len(Y_test)))
Berechnen Sie die Genauigkeit des Testsatzes und drucken Sie sie aus
Durchlaufen Sie jede Probe im Testsatz X_test und Y_test und verwenden Sie die knn-Funktion, um jede Probe zu klassifizieren.
Statistiken sagen die Anzahl der richtigen Stichproben voraus, berechnen die Genauigkeit der Klassifizierung und geben sie aus.
label: 1, prediction: 1 label: 2, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 2 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 Validation accuracy is 0.660000
Es ist nicht möglich, jedes Mal 80 % zu erreichen. Nach vielen Versuchen erreichte die Genauigkeit schließlich 80 %:
label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 3 label: 3, prediction: 3 label: 1, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 Validation accuracy is 0.820000
Dieses Experiment verwendet MindSpore, um den KNN-Algorithmus zur Lösung des 3-Klassifizierungsproblems zu implementieren. Nehmen Sie die drei Arten von Proben im Weindatensatz und unterteilen Sie sie in Proben bekannter Kategorien und zu überprüfende Proben. Aus den Überprüfungsergebnissen können wir ersehen, dass der KNN-Algorithmus bei dieser Aufgabe effektiv ist und die Weinsorte anhand dessen bestimmen kann 13 Attribute von Wein.
Datenvorbereitung: Laden Sie Daten von der offiziellen Wine-Dataset-Website oder Huawei Cloud OBS herunter, lesen und verarbeiten Sie sie.
Datenverarbeitung: Teilen Sie den Datensatz in unabhängige Variablen (13 Attribute) und abhängige Variablen (3 Kategorien) auf und visualisieren Sie diese, um die Stichprobenverteilung zu beobachten.
Modellkonstruktion: Definieren Sie die KNN-Netzwerkstruktur, berechnen Sie mit dem von MindSpore bereitgestellten Operator den Abstand zwischen der Eingabeprobe und der Trainingsprobe und ermitteln Sie die nächsten k Nachbarn.
Modellvorhersage: Treffen Sie Vorhersagen zum Validierungssatz und berechnen Sie die Vorhersagegenauigkeit.
Experimentelle Ergebnisse zeigen, dass die Klassifizierungsgenauigkeit des KNN-Algorithmus für den Wine-Datensatz nahezu 80 % (66 %) beträgt.

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen

