
le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

Questo esperimento introduce principalmente l'uso di MindSpore per condurre esperimenti KNN su alcuni set di dati sul vino.
K-Nearest-Neighbor (KNN) è un metodo statistico non parametrico per la classificazione e la regressione, originariamente proposto da Cover e Hart nel 1968 (Copertina et al., 1967 ), è uno degli algoritmi più basilari nell'apprendimento automatico. Si basa sull'idea di cui sopra: per determinare la categoria di un campione, è possibile calcolare la sua distanza da tutti i campioni di addestramento, quindi trovare i k campioni più vicini al campione, contare le categorie di questi campioni e votare Quello con la maggior parte dei voti Quella classe è il risultato della classificazione. Tre elementi fondamentali di KNN:
Valore K, la classificazione di un campione è determinata dal "voto della maggioranza" dei vicini K. Più piccolo è il valore K, più facile sarà essere colpiti dal rumore. Al contrario, i confini tra le categorie diventeranno sfumati.
La misura della distanza riflette la somiglianza tra due campioni nello spazio delle caratteristiche. Quanto minore è la distanza, tanto più simili sono i campioni. Quelli comunemente usati includono la distanza Lp (quando p=2, è la distanza euclidea), la distanza di Manhattan, la distanza di Hamming, ecc.
Regole decisionali di classificazione, solitamente voto a maggioranza o voto a maggioranza basato sulla ponderazione della distanza (i pesi sono inversamente proporzionali alla distanza).
I metodi statistici non parametrici si riferiscono a metodi statistici che non si basano su forme parametriche (come l'ipotesi di distribuzione normale nelle statistiche tradizionali, ecc.), ovvero non fanno ipotesi rigorose sulla distribuzione dei dati. Rispetto ai metodi statistici parametrici (come la regressione lineare, il t-test, ecc.), i metodi statistici non parametrici sono più flessibili perché non presuppongono che i dati seguano uno schema di distribuzione specifico.
I metodi statistici parametrici si basano sulla formulazione di presupposti e requisiti specifici per la distribuzione dei dati e utilizzano determinati parametri per descrivere la forma di distribuzione dei dati. Queste forme parametriche possono semplificare notevolmente modelli e analisi, ma richiedono anche che tali ipotesi e parametri siano coerenti con i dati effettivi, il che può portare a conclusioni fuorvianti quando le ipotesi non vengono soddisfatte.
1. Regressione lineare:
Presupposto: esiste una relazione lineare tra la variabile dipendente (variabile di risposta) e la variabile indipendente (variabile esplicativa).
Parametri: coefficienti di regressione (pendenza e intercetta), solitamente presupponendo che il termine di errore abbia media zero, varianza costante (omoschedasticità) e distribuzione normale.
2. Regressione logistica:
Presupposto: la variabile dipendente (variabile categoriale) soddisfa il modello di regressione logistica e il coefficiente di regressione è un valore fisso.
Parametro: coefficiente di regressione, utilizzato per descrivere l'influenza delle variabili indipendenti sulle variabili dipendenti, stimata mediante stima di massima verosimiglianza.
3. prova t:
Presupposto: i dati del campione provengono da una popolazione distribuita normalmente.
Parametri: media e varianza, il test t per un campione presuppone la media della popolazione, il test t per due campioni presuppone la differenza tra le medie di due popolazioni.
Il processo dell'algoritmo di previsione (classificazione) è il seguente:
(1) Trova i k campioni più vicini al campione di prova x_test nel set di campioni di addestramento e salvali nel set N;
(2)统计集合N中每一类样本的个数𝐶𝑖,𝑖=1,2,3,...,𝑐;
(3)最终的分类结果为argmax𝐶𝑖 (最大的对应的𝐶𝑖)那个类。
Nel processo di implementazione di cui sopra, il valore di k è particolarmente importante. Può essere determinato in base al problema e alle caratteristiche dei dati. Nell'implementazione specifica, è possibile considerare il peso del campione, ovvero ogni campione ha un peso di voto diverso. Questo metodo è chiamato algoritmo del vicino k-più vicino pesato, che è una variante dell'algoritmo del vicino più vicino k.
假设离测试样本最近的k个训练样本的标签值为𝑦𝑖,则对样本的回归预测输出值为:

Questo è il valore medio dell'etichetta di tutti i vicini.
La funzione di previsione della regressione con pesi campionari è:

其中𝑤𝑖为第个𝑖样本的权重。
KNN算法的实现依赖于样本之间的距离,其中最常用的距离函数就是欧氏距离(欧几里得距离)。ℝ𝑛空间中的两点𝑥和𝑦,它们之间的欧氏距离定义为:
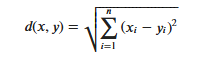
Va notato che quando si utilizza la distanza euclidea, ciascuna componente del vettore delle caratteristiche dovrebbe essere normalizzata per ridurre l'interferenza causata dai diversi intervalli di scala dei valori delle caratteristiche. Altrimenti, le componenti delle caratteristiche con valori piccoli verranno sostituite da caratteristiche con grandi valori. I componenti caratteristici sono sommersi.
Altri metodi di calcolo della distanza includono la distanza Mahalanobis, la distanza Bhattacharyya, ecc.
Conoscenze preliminari:
ambiente di laboratorio:
Il set di dati Wine è uno dei set di dati più famosi per il riconoscimento di modelli Il sito web ufficiale del set di dati Wine:Set di dati sul vino . I dati sono il risultato di un'analisi chimica di vini della stessa regione d'Italia ma di tre varietà diverse. Il set di dati analizza le quantità di 13 ingredienti contenuti in ciascuno dei tre vini.Questi 13 attributi sono
| Chiave | Valore | Chiave | Valore |
|---|---|---|---|
| Caratteristiche del set di dati: | Multivariato | Numero di istanze: | 178 |
| Caratteristiche degli attributi: | Intero, Reale | Numero di attributi: | 13 |
| Attività associate: | Classificazione | Valori mancanti? | NO |
- %%capture captured_output
- # 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
- !pip uninstall mindspore -y
- !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
- # 查看当前 mindspore 版本
- !pip show mindspore
Name: mindspore Version: 2.2.14 Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Home-page: https://www.mindspore.cn Author: The MindSpore Authors Author-email: [email protected] License: Apache 2.0 Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy Required-by:
- from download import download
-
- # 下载红酒数据集
- url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
- path = download(url, "./", kind="zip", replace=True)
Downloading data from https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip (4 kB) file_sizes: 100%|██████████████████████████| 4.09k/4.09k [00:00<00:00, 2.51MB/s] Extracting zip file... Successfully downloaded / unzipped to ./
Prima di generare dati, importare le librerie Python richieste.
Attualmente viene utilizzata la libreria del sistema operativo. Per facilitare la comprensione, spiegheremo le altre librerie richieste quando verranno utilizzate in modo specifico.
È possibile cercare descrizioni dettagliate del modulo MindSpore nella pagina API MindSpore.
È possibile configurare le informazioni richieste per il funzionamento tramite context.set_context, come modalità operativa, informazioni sul backend, hardware e altre informazioni.
Importa il modulo di contesto e configura le informazioni necessarie per il funzionamento.
- %matplotlib inline
- import os
- import csv
- import numpy as np
- import matplotlib.pyplot as plt
-
- import mindspore as ms
- from mindspore import nn, ops
-
- ms.set_context(device_target="CPU")

wine.datae visualizzare alcuni dati.- with open('wine.data') as csv_file:
- data = list(csv.reader(csv_file, delimiter=','))
- print(data[56:62]+data[130:133])
[['1', '14.22', '1.7', '2.3', '16.3', '118', '3.2', '3', '.26', '2.03', '6.38', '.94', '3.31', '970'], ['1', '13.29', '1.97', '2.68', '16.8', '102', '3', '3.23', '.31', '1.66', '6', '1.07', '2.84', '1270'], ['1', '13.72', '1.43', '2.5', '16.7', '108', '3.4', '3.67', '.19', '2.04', '6.8', '.89', '2.87', '1285'], ['2', '12.37', '.94', '1.36', '10.6', '88', '1.98', '.57', '.28', '.42', '1.95', '1.05', '1.82', '520'], ['2', '12.33', '1.1', '2.28', '16', '101', '2.05', '1.09', '.63', '.41', '3.27', '1.25', '1.67', '680'], ['2', '12.64', '1.36', '2.02', '16.8', '100', '2.02', '1.41', '.53', '.62', '5.75', '.98', '1.59', '450'], ['3', '12.86', '1.35', '2.32', '18', '122', '1.51', '1.25', '.21', '.94', '4.1', '.76', '1.29', '630'], ['3', '12.88', '2.99', '2.4', '20', '104', '1.3', '1.22', '.24', '.83', '5.4', '.74', '1.42', '530'], ['3', '12.81', '2.31', '2.4', '24', '98', '1.15', '1.09', '.27', '.83', '5.7', '.66', '1.36', '560']]
- X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
- Y = np.array([s[0] for s in data[:178]], np.int32)
- attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
- 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
- 'OD280/OD315 of diluted wines', 'Proline']
- plt.figure(figsize=(10, 8))
- for i in range(0, 4):
- plt.subplot(2, 2, i+1)
- a1, a2 = 2 * i, 2 * i + 1
- plt.scatter(X[:59, a1], X[:59, a2], label='1')
- plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
- plt.scatter(X[130:, a1], X[130:, a2], label='3')
- plt.xlabel(attrs[a1])
- plt.ylabel(attrs[a2])
- plt.legend()
- plt.show()
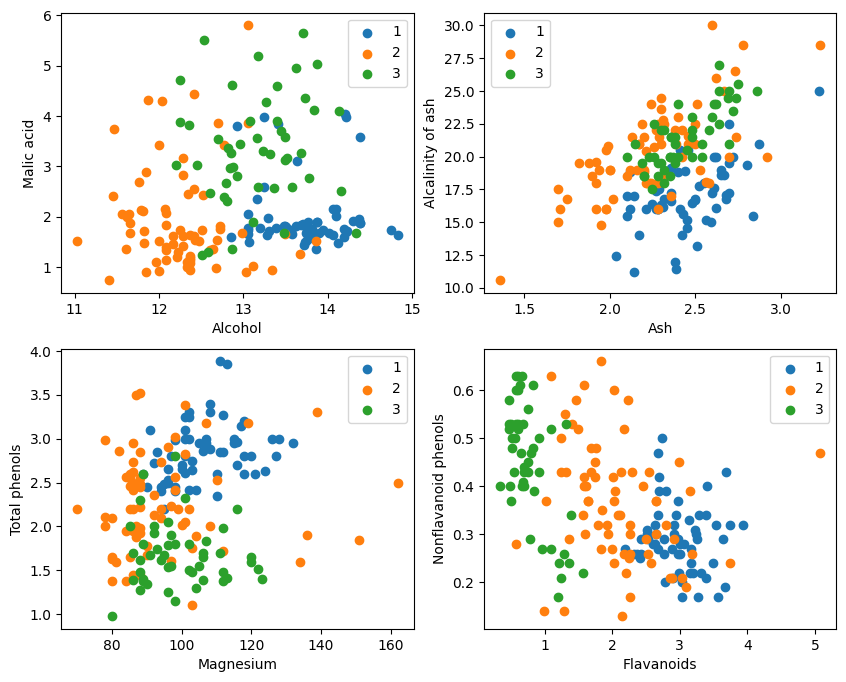
Dalla visualizzazione grafica, i due effetti di classificazione degli attributi nell'angolo superiore sinistro e nell'angolo inferiore destro del grafico sono relativamente buoni, in particolare i confini tra le categorie 1 e 2 sono relativamente evidenti.
- train_idx = np.random.choice(178, 128, replace=False)
- test_idx = np.array(list(set(range(178)) - set(train_idx)))
- X_train, Y_train = X[train_idx], Y[train_idx]
- X_test, Y_test = X[test_idx], Y[test_idx]
Specifica test_idx = np.array(list(set(range(178)) - set(train_idx)))
1. range(178) genera una sequenza di numeri interi da 0 a 177.
2. set(range(178)) converte questa sequenza di numeri interi in un insieme. Un insieme è una struttura di dati che non consente elementi ripetuti e supporta operazioni di insieme efficienti (come unione, intersezione, differenza, ecc.).
3. set(train_idx) converte l'elenco degli indici dei set di training train_idx selezionato casualmente in un set.
4. set(range(178)) - set(train_idx) calcola l'operazione di set di differenze del set e ottiene gli elementi che sono in set(range(178)) ma non in set(train_idx), che sono gli indici del set di prova. Questa è un'operazione impostata che può calcolare in modo rapido ed efficiente gli elementi di differenza.
5. list(...) riconverte il risultato dell'operazione di differenza in una lista.
6. np.array(...) converte questo elenco in un array numpy per l'indicizzazione con gli array numpy X e Y。
Approfitta di ciò che offre MindSporetile, square, ReduceSum, sqrt, TopKe altri operatori, calcolano simultaneamente la distanza tra il campione di input x e altri campioni chiaramente classificati X_train attraverso operazioni di matrice e calcolano i primi k vicini più vicini
- class KnnNet(nn.Cell):
- def __init__(self, k):
- super(KnnNet, self).__init__()
- self.k = k
-
- def construct(self, x, X_train):
- #平铺输入x以匹配X_train中的样本数
- x_tile = ops.tile(x, (128, 1))
- square_diff = ops.square(x_tile - X_train)
- square_dist = ops.sum(square_diff, 1)
- dist = ops.sqrt(square_dist)
- #-dist表示值越大,样本就越接近
- values, indices = ops.topk(-dist, self.k)
- return indices
-
- def knn(knn_net, x, X_train, Y_train):
- x, X_train = ms.Tensor(x), ms.Tensor(X_train)
- indices = knn_net(x, X_train)
- topk_cls = [0]*len(indices.asnumpy())
- for idx in indices.asnumpy():
- topk_cls[Y_train[idx]] += 1
- cls = np.argmax(topk_cls)
- return cls
1. Definire la classe di rete KNN: KnnNet
Funzione __init__: inizializza la rete e imposta il valore K (ovvero il numero di vicini più vicini selezionati).
funzione di costruzione: calcola la distanza euclidea tra il campione di input x e ciascun campione nel set di addestramento X_train e restituisce l'indice dei campioni k (ovvero il vicino più vicino) con la distanza più piccola.
2. Definire la funzione KNN: knn
Riceve knn_net (istanza di rete KNN), campione di test x, campione di addestramento X_train e etichetta di addestramento Y_train come input.
Utilizzare knn_net per trovare i k campioni vicini più vicini di x, classificarli in base alle etichette di questi campioni e restituire il risultato della classificazione (ovvero la categoria prevista).
在验证集上验证KNN算法的有效性,取𝑘=5,验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
- acc = 0
- knn_net = KnnNet(5)
- for x, y in zip(X_test, Y_test):
- pred = knn(knn_net, x, X_train, Y_train)
- acc += (pred == y)
- print('label: %d, prediction: %s' % (y, pred))
- print('Validation accuracy is %f' % (acc/len(Y_test)))
Calcolare e stampare la precisione del set di test
Passare in rassegna ciascun campione nel set di test X_test e Y_test e utilizzare la funzione knn per classificare ciascun campione.
Le statistiche prevedono il numero di campioni corretti, calcolano e restituiscono l'accuratezza della classificazione.
label: 1, prediction: 1 label: 2, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 2 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 Validation accuracy is 0.660000
Non è possibile raggiungere l'80% ogni volta Dopo aver provato molte volte, la precisione ha finalmente raggiunto l'80%:
label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 3 label: 3, prediction: 3 label: 1, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 Validation accuracy is 0.820000
Questo esperimento utilizza MindSpore per implementare l'algoritmo KNN per risolvere il problema della 3 classificazione. Prendi i 3 tipi di campioni sul set di dati del vino e dividili in campioni di categorie note e campioni da verificare. Dai risultati della verifica, possiamo vedere che l'algoritmo KNN è efficace in questo compito e può determinare la varietà di vino in base a 13 attributi del vino.
Preparazione dei dati: scarica i dati dal sito Web ufficiale del set di dati di Wine o Huawei Cloud OBS, leggili ed elaborali.
Elaborazione dei dati: dividere il set di dati in variabili indipendenti (13 attributi) e variabili dipendenti (3 categorie) e visualizzarle per osservare la distribuzione del campione.
Costruzione del modello: definire la struttura della rete KNN, utilizzare l'operatore fornito da MindSpore per calcolare la distanza tra il campione di input e il campione di addestramento e trovare i k vicini più vicini.
Previsione del modello: effettua previsioni sul set di validazione e calcola l'accuratezza della previsione.
I risultati sperimentali mostrano che l'accuratezza della classificazione dell'algoritmo KNN sul set di dati Wine è vicina all'80% (66%).

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]