
informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

Eksperimen ini terutama memperkenalkan penggunaan MindSpore untuk melakukan eksperimen KNN pada beberapa kumpulan data anggur.
K-Nearest-Neighbor (KNN) adalah metode statistik non-parametrik untuk klasifikasi dan regresi, yang awalnya diusulkan oleh Cover dan Hart pada tahun 1968 (Sampul dkk., 1967 ), adalah salah satu algoritma paling dasar dalam pembelajaran mesin. Hal ini didasarkan pada gagasan di atas: untuk menentukan kategori suatu sampel, Anda dapat menghitung jaraknya dari semua sampel pelatihan, kemudian mencari k sampel yang paling dekat dengan sampel, menghitung kategori sampel tersebut, dan memilih yang memiliki suara terbanyak Kelas itu merupakan hasil klasifikasi. Tiga elemen dasar KNN:
Nilai K, klasifikasi suatu sampel ditentukan oleh “suara terbanyak” dari K tetangganya. Semakin kecil nilai K maka semakin mudah terpengaruh oleh noise. Sebaliknya, batas antar kategori menjadi kabur.
Ukuran jarak mencerminkan kesamaan antara dua sampel dalam ruang fitur. Semakin kecil jaraknya, semakin mirip pula keduanya. Yang umum digunakan antara lain jarak Lp (bila p=2, maka jarak Euclidean), jarak Manhattan, jarak Hamming, dll.
Aturan pengambilan keputusan klasifikasi, biasanya voting mayoritas, atau voting mayoritas berdasarkan bobot jarak (bobot berbanding terbalik dengan jarak).
Metode statistik nonparametrik mengacu pada metode statistik yang tidak bergantung pada bentuk parametrik (seperti asumsi distribusi normal dalam statistik tradisional, dll), yaitu tidak membuat asumsi yang ketat tentang distribusi data. Dibandingkan dengan metode statistik parametrik (seperti regresi linier, uji-t, dll), metode statistik nonparametrik lebih fleksibel karena tidak mengasumsikan bahwa data mengikuti pola distribusi tertentu.
Metode statistik parametrik mengandalkan pembuatan asumsi dan persyaratan khusus untuk distribusi data, dan menggunakan parameter tertentu untuk menggambarkan bentuk distribusi data. Bentuk parametrik ini dapat menyederhanakan model dan analisis secara signifikan, namun juga memerlukan asumsi dan parameter yang konsisten dengan data aktual, sehingga dapat menghasilkan kesimpulan yang menyesatkan jika asumsi tidak terpenuhi.
1. Regresi Linier:
Asumsi: Terdapat hubungan linier antara variabel terikat (variabel respon) dan variabel bebas (variabel penjelas).
Parameter: Koefisien regresi (kemiringan dan intersep), biasanya dengan asumsi bahwa error term memiliki mean nol, varians konstan (homoskedastisitas), dan berdistribusi normal.
2. Regresi Logistik:
Asumsi: Variabel terikat (variabel kategori) memenuhi model regresi logistik, dan koefisien regresi bernilai tetap.
Parameter: Koefisien regresi, digunakan untuk menggambarkan pengaruh variabel independen terhadap variabel dependen, diperkirakan melalui estimasi kemungkinan maksimum.
3. uji-t:
Asumsi: Data sampel berasal dari populasi yang berdistribusi normal.
Parameter: mean dan varians, uji t satu sampel mengasumsikan mean populasi, uji t dua sampel mengasumsikan perbedaan mean dua populasi.
Proses algoritma prediksi (klasifikasi) adalah sebagai berikut:
(1) Temukan k sampel yang paling dekat dengan sampel uji x_test di kumpulan sampel pelatihan dan simpan di kumpulan N;
(2)统计集合N中每一类样本的个数𝐶𝑖,𝑖=1,2,3,...,𝑐;
(3)最终的分类结果为argmax𝐶𝑖 (最大的对应的𝐶𝑖)那个类。
Dalam proses implementasi di atas, nilai k sangatlah penting. Hal ini dapat ditentukan berdasarkan masalah dan karakteristik data. Dalam implementasi spesifiknya dapat dipertimbangkan bobot sampelnya, yaitu setiap sampel mempunyai bobot voting yang berbeda-beda. Metode ini disebut dengan algoritma k-nearest neighbour tertimbang yang merupakan varian dari algoritma k-nearest neighbour.
假设离测试样本最近的k个训练样本的标签值为𝑦𝑖,则对样本的回归预测输出值为:

Itu adalah nilai label rata-rata semua tetangga.
Fungsi prediksi regresi dengan bobot sampel adalah:

其中𝑤𝑖为第个𝑖样本的权重。
KNN算法的实现依赖于样本之间的距离,其中最常用的距离函数就是欧氏距离(欧几里得距离)。ℝ𝑛空间中的两点𝑥和𝑦,它们之间的欧氏距离定义为:
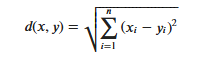
Perlu dicatat bahwa ketika menggunakan jarak Euclidean, setiap komponen vektor fitur harus dinormalisasi untuk mengurangi interferensi yang disebabkan oleh perbedaan rentang skala nilai fitur. Jika tidak, komponen fitur dengan nilai kecil akan digantikan oleh fitur dengan nilai besar nilai. Komponen karakteristik terendam.
Metode penghitungan jarak lainnya termasuk jarak Mahalanobis, jarak Bhattacharyya, dll.
Pengetahuan awal:
lingkungan laboratorium:
Kumpulan data Wine adalah salah satu kumpulan data paling terkenal untuk pengenalan pola. Situs web resmi kumpulan data Wine:Set Data Anggur . Data tersebut merupakan hasil analisis kimiawi wine dari wilayah yang sama di Italia tetapi dari tiga varietas berbeda. Kumpulan data menganalisis jumlah 13 bahan yang terkandung dalam masing-masing tiga anggur.13 atribut tersebut adalah
| Kunci | Nilai | Kunci | Nilai |
|---|---|---|---|
| Karakteristik Set Data: | Multivariat | Jumlah Contoh: | 178 |
| Karakteristik Atribut: | Bilangan Bulat, Nyata | Jumlah Atribut: | 13 |
| Tugas Terkait: | Klasifikasi | Nilai yang hilang? | TIDAK |
- %%capture captured_output
- # 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
- !pip uninstall mindspore -y
- !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
- # 查看当前 mindspore 版本
- !pip show mindspore
Name: mindspore Version: 2.2.14 Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Home-page: https://www.mindspore.cn Author: The MindSpore Authors Author-email: [email protected] License: Apache 2.0 Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy Required-by:
- from download import download
-
- # 下载红酒数据集
- url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
- path = download(url, "./", kind="zip", replace=True)
Downloading data from https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip (4 kB) file_sizes: 100%|██████████████████████████| 4.09k/4.09k [00:00<00:00, 2.51MB/s] Extracting zip file... Successfully downloaded / unzipped to ./
Sebelum membuat data, impor pustaka Python yang diperlukan.
Library os yang saat ini digunakan. Untuk memudahkan pemahaman, kami akan menjelaskan pustaka lain yang diperlukan saat digunakan secara khusus.
Deskripsi modul MindSpore secara detail dapat dicari di halaman MindSpore API.
Anda dapat mengonfigurasi informasi yang diperlukan untuk pengoperasian melalui konteks.set_context, seperti mode operasi, informasi backend, perangkat keras, dan informasi lainnya.
Impor modul konteks dan konfigurasikan informasi yang diperlukan untuk pengoperasian.
- %matplotlib inline
- import os
- import csv
- import numpy as np
- import matplotlib.pyplot as plt
-
- import mindspore as ms
- from mindspore import nn, ops
-
- ms.set_context(device_target="CPU")

wine.data, dan melihat beberapa data.- with open('wine.data') as csv_file:
- data = list(csv.reader(csv_file, delimiter=','))
- print(data[56:62]+data[130:133])
[['1', '14.22', '1.7', '2.3', '16.3', '118', '3.2', '3', '.26', '2.03', '6.38', '.94', '3.31', '970'], ['1', '13.29', '1.97', '2.68', '16.8', '102', '3', '3.23', '.31', '1.66', '6', '1.07', '2.84', '1270'], ['1', '13.72', '1.43', '2.5', '16.7', '108', '3.4', '3.67', '.19', '2.04', '6.8', '.89', '2.87', '1285'], ['2', '12.37', '.94', '1.36', '10.6', '88', '1.98', '.57', '.28', '.42', '1.95', '1.05', '1.82', '520'], ['2', '12.33', '1.1', '2.28', '16', '101', '2.05', '1.09', '.63', '.41', '3.27', '1.25', '1.67', '680'], ['2', '12.64', '1.36', '2.02', '16.8', '100', '2.02', '1.41', '.53', '.62', '5.75', '.98', '1.59', '450'], ['3', '12.86', '1.35', '2.32', '18', '122', '1.51', '1.25', '.21', '.94', '4.1', '.76', '1.29', '630'], ['3', '12.88', '2.99', '2.4', '20', '104', '1.3', '1.22', '.24', '.83', '5.4', '.74', '1.42', '530'], ['3', '12.81', '2.31', '2.4', '24', '98', '1.15', '1.09', '.27', '.83', '5.7', '.66', '1.36', '560']]
- X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
- Y = np.array([s[0] for s in data[:178]], np.int32)
- attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
- 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
- 'OD280/OD315 of diluted wines', 'Proline']
- plt.figure(figsize=(10, 8))
- for i in range(0, 4):
- plt.subplot(2, 2, i+1)
- a1, a2 = 2 * i, 2 * i + 1
- plt.scatter(X[:59, a1], X[:59, a2], label='1')
- plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
- plt.scatter(X[130:, a1], X[130:, a2], label='3')
- plt.xlabel(attrs[a1])
- plt.ylabel(attrs[a2])
- plt.legend()
- plt.show()
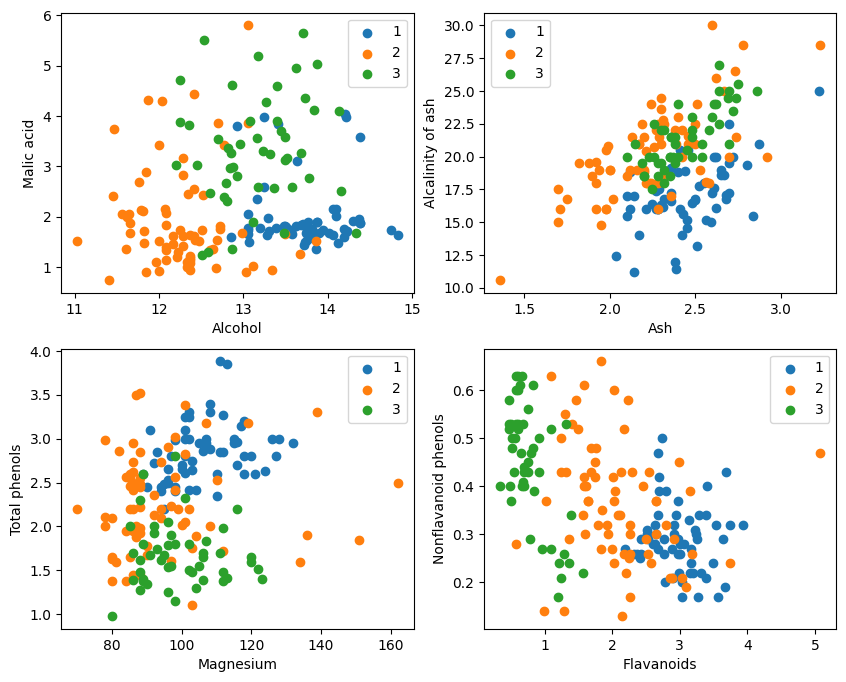
Dari tampilan grafis, efek klasifikasi dua atribut di pojok kiri atas dan pojok kanan bawah grafik relatif baik, terutama batas antara kategori 1 dan 2 relatif jelas.
- train_idx = np.random.choice(178, 128, replace=False)
- test_idx = np.array(list(set(range(178)) - set(train_idx)))
- X_train, Y_train = X[train_idx], Y[train_idx]
- X_test, Y_test = X[test_idx], Y[test_idx]
Fungsi test_idx = np.array(list(set(range(178)) - set(train_idx)))
1. range(178) menghasilkan urutan bilangan bulat dari 0 hingga 177.
2. set(range(178)) mengubah barisan bilangan bulat ini menjadi satu set. Himpunan adalah struktur data yang tidak memungkinkan elemen berulang dan mendukung operasi himpunan yang efisien (seperti penyatuan, perpotongan, perbedaan, dll.).
3. set(train_idx) mengubah daftar indeks set pelatihan yang dipilih secara acak train_idx menjadi satu set.
4. set(range(178)) - set(train_idx) menghitung operasi himpunan selisih dari himpunan dan mendapatkan elemen yang ada di set(range(178)) tetapi tidak di set(train_idx), yang merupakan indeks dari set tes. Ini adalah operasi himpunan yang dapat dengan cepat dan efisien menghitung elemen perbedaan.
5. list(...) mengubah hasil operasi perbedaan kembali menjadi daftar.
6. np.array(...) mengubah daftar ini menjadi array numpy untuk diindeks dengan array numpy X dan Y。
Manfaatkan apa yang ditawarkan MindSporetile, square, ReduceSum, sqrt, TopKdan operator lain, secara bersamaan menghitung jarak antara sampel masukan x dan sampel lain yang diklasifikasikan dengan jelas X_train melalui operasi matriks, dan menghitung k tetangga terdekat teratas
- class KnnNet(nn.Cell):
- def __init__(self, k):
- super(KnnNet, self).__init__()
- self.k = k
-
- def construct(self, x, X_train):
- #平铺输入x以匹配X_train中的样本数
- x_tile = ops.tile(x, (128, 1))
- square_diff = ops.square(x_tile - X_train)
- square_dist = ops.sum(square_diff, 1)
- dist = ops.sqrt(square_dist)
- #-dist表示值越大,样本就越接近
- values, indices = ops.topk(-dist, self.k)
- return indices
-
- def knn(knn_net, x, X_train, Y_train):
- x, X_train = ms.Tensor(x), ms.Tensor(X_train)
- indices = knn_net(x, X_train)
- topk_cls = [0]*len(indices.asnumpy())
- for idx in indices.asnumpy():
- topk_cls[Y_train[idx]] += 1
- cls = np.argmax(topk_cls)
- return cls
1. Tentukan kelas jaringan KNN: KnnNet
Fungsi __init__: Inisialisasi jaringan dan tetapkan nilai K (yaitu, jumlah tetangga terdekat yang dipilih).
fungsi konstruk: Hitung jarak Euclidean antara sampel input x dan setiap sampel di set pelatihan X_train, dan kembalikan indeks sampel k (yaitu tetangga terdekat) dengan jarak terkecil.
2. Definisikan fungsi KNN: knn
Menerima knn_net (contoh jaringan KNN), sampel uji x, sampel pelatihan X_train, dan label pelatihan Y_train sebagai masukan.
Gunakan knn_net untuk menemukan k sampel tetangga terdekat dari x, klasifikasikan berdasarkan label sampel tersebut, dan kembalikan hasil klasifikasi (yaitu, kategori prediksi).
在验证集上验证KNN算法的有效性,取𝑘=5,验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
- acc = 0
- knn_net = KnnNet(5)
- for x, y in zip(X_test, Y_test):
- pred = knn(knn_net, x, X_train, Y_train)
- acc += (pred == y)
- print('label: %d, prediction: %s' % (y, pred))
- print('Validation accuracy is %f' % (acc/len(Y_test)))
Hitung dan cetak keakuratan set pengujian
Ulangi setiap sampel di set pengujian X_test dan Y_test, dan gunakan fungsi knn untuk mengklasifikasikan setiap sampel.
Statistik memprediksi jumlah sampel yang benar, menghitung dan menghasilkan keakuratan klasifikasi.
label: 1, prediction: 1 label: 2, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 2 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 Validation accuracy is 0.660000
Tidak mungkin mencapai 80% setiap saat. Setelah mencoba berkali-kali, akhirnya akurasi mencapai 80%:
label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 3 label: 3, prediction: 3 label: 1, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 Validation accuracy is 0.820000
Eksperimen ini menggunakan MindSpore untuk mengimplementasikan algoritma KNN untuk menyelesaikan masalah 3 klasifikasi. Ambil 3 jenis sampel pada kumpulan data wine dan bagi menjadi sampel kategori yang diketahui dan sampel yang akan diverifikasi. Dari hasil verifikasi, kita dapat melihat bahwa algoritma KNN efektif dalam tugas ini dan dapat menentukan variasi wine berdasarkan 13 atribut anggur.
Persiapan data: Unduh data dari situs resmi kumpulan data Wine atau Huawei Cloud OBS, baca dan proses.
Pengolahan data: Bagilah kumpulan data menjadi variabel independen (13 atribut) dan variabel dependen (3 kategori), dan visualisasikan untuk mengamati distribusi sampel.
Konstruksi model: Tentukan struktur jaringan KNN, gunakan operator yang disediakan oleh MindSpore untuk menghitung jarak antara sampel masukan dan sampel pelatihan, dan temukan k tetangga terdekat.
Prediksi model: Membuat prediksi pada set validasi dan menghitung akurasi prediksi.
Hasil eksperimen menunjukkan akurasi klasifikasi algoritma KNN pada dataset Wine mendekati 80% (66%).

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]