
私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
AIを学習すれば賞品を獲得できるでしょうか? AI Rendu Second Meridian を開くには 1 日 30 分、25 日かかります (qq.com)

この実験では主に、いくつかのワイン データ セットに対して KNN 実験を実行するための MindSpore の使用を紹介します。
K-Nearest-Neighbor (KNN) は、分類と回帰のためのノンパラメトリック統計手法であり、1968 年に Cover と Hart によって最初に提案されました (カバー他、1967 ) は、機械学習の最も基本的なアルゴリズムの 1 つです。これは上記の考え方に基づいています。サンプルのカテゴリを決定するには、そのサンプルとすべてのトレーニング サンプルの間の距離を計算し、そのサンプルに最も近い k 個のサンプルを見つけ、これらのサンプルのカテゴリを数えて、次のカテゴリに投票します。最も多くの票が得られたクラスが分類の結果です。 KNN の 3 つの基本要素:
K 値。サンプルの分類は、K 個の近傍の「多数決」によって決定されます。 Kの値が小さいほどノイズの影響を受けやすくなり、逆にカテゴリー間の境界が曖昧になります。
距離測定は、特徴空間内の 2 つのサンプル間の類似性を反映します。距離が小さいほど、それらは類似しています。よく使われるのは、Lp距離(p=2の場合はユークリッド距離)、マンハッタン距離、ハミング距離などです。
分類決定ルール。通常は多数決、または距離の重み付けに基づく多数決 (重みは距離に反比例します)。
ノンパラメトリック統計手法とは、パラメトリック形式 (従来の統計における正規分布の仮定など) に依存しない統計手法を指します。つまり、データ分布について厳密な仮定を立てません。パラメトリック統計手法 (線形回帰、t 検定など) と比較して、ノンパラメトリック統計手法は、データが特定の分布パターンに従うことを想定していないため、より柔軟です。
パラメトリック統計手法は、データ分布に関する特定の仮定と要件の作成に依存し、特定のパラメーターを使用してデータの分布形状を記述します。これらのパラメトリック形式はモデルと分析を大幅に簡素化できますが、これらの仮定とパラメータが実際のデータと一致している必要もあり、仮定が満たされない場合には誤解を招く結論につながる可能性があります。
1. 線形回帰:
仮定: 従属変数 (応答変数) と独立変数 (説明変数) の間には線形関係があります。
パラメータ: 回帰係数 (傾きと切片)、通常、誤差項の平均値がゼロ、定数分散 (等分散性)、正規分布があると仮定します。
2. ロジスティック回帰:
仮定: 従属変数 (カテゴリ変数) はロジスティック回帰モデルを満たし、回帰係数は固定値です。
パラメーター: 回帰係数。従属変数に対する独立変数の影響を説明するために使用され、最尤推定によって推定されます。
3. t 検定:
仮定: サンプル データは正規分布した母集団から得られます。
パラメーター: 平均と分散、1 サンプル t 検定は母集団の平均を仮定し、2 サンプル t 検定は 2 つの母集団の平均間の差を仮定します。
予測アルゴリズム(分類)のプロセスは次のとおりです。
(1) トレーニング サンプル セット内のテスト サンプル x_test に最も近い k 個のサンプルを見つけて、それらをセット N に保存します。
(2)统计集合N中每一类样本的个数𝐶𝑖,𝑖=1,2,3,...,𝑐;
(3)最终的分类结果为argmax𝐶𝑖 (最大的对应的𝐶𝑖)那个类。
上記の実装プロセスでは、k の値が特に重要です。これは、問題とデータの特性に基づいて決定できます。特定の実装では、サンプルの重みが考慮されます。つまり、各サンプルは異なる投票重みを持ちます。この方法は、k 最近傍アルゴリズムの変形である加重 k 最近傍アルゴリズムと呼ばれます。
假设离测试样本最近的k个训练样本的标签值为𝑦𝑖,则对样本的回归预测输出值为:

これは、すべての近傍の平均ラベル値です。
サンプルの重みを使用した回帰予測関数は次のとおりです。

其中𝑤𝑖为第个𝑖样本的权重。
KNN算法的实现依赖于样本之间的距离,其中最常用的距离函数就是欧氏距离(欧几里得距离)。ℝ𝑛空间中的两点𝑥和𝑦,它们之间的欧氏距离定义为:
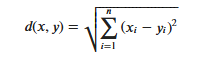
ユークリッド距離を使用する場合、特徴値の異なるスケール範囲によって引き起こされる干渉を減らすために特徴ベクトルの各成分を正規化する必要があることに注意することが重要です。そうしないと、値が小さい特徴成分が次の特徴に置き換えられます。値が大きいと特徴的な成分が埋もれてしまいます。
他の距離計算方法には、マハラノビス距離、バタチャリヤ距離などがあります。
予備知識:
ラボ環境:
Wine データ セットは、パターン認識用の最も有名なデータ セットの 1 つです。Wine データ セットの公式 Web サイトは次のとおりです。ワインデータセット 。このデータは、イタリアの同じ地域で生産された 3 つの異なる品種のワインの化学分析の結果です。このデータセットは、3 つのワインのそれぞれに含まれる 13 種類の成分の量を分析します。これら 13 の属性は、
| 鍵 | 価値 | 鍵 | 価値 |
|---|---|---|---|
| データセットの特性: | 多変量 | インスタンス数: | 178 |
| 属性特性: | 整数、実数 | 属性の数: | 13 |
| 関連タスク: | 分類 | 値が欠落していますか? | いいえ |
- %%capture captured_output
- # 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
- !pip uninstall mindspore -y
- !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
- # 查看当前 mindspore 版本
- !pip show mindspore
Name: mindspore Version: 2.2.14 Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Home-page: https://www.mindspore.cn Author: The MindSpore Authors Author-email: [email protected] License: Apache 2.0 Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy Required-by:
- from download import download
-
- # 下载红酒数据集
- url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
- path = download(url, "./", kind="zip", replace=True)
Downloading data from https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip (4 kB) file_sizes: 100%|██████████████████████████| 4.09k/4.09k [00:00<00:00, 2.51MB/s] Extracting zip file... Successfully downloaded / unzipped to ./
データを生成する前に、必要な Python ライブラリをインポートします。
現在はosライブラリを使用していますが、その他の必要なライブラリについては、具体的に使用する際にわかりやすく説明します。
MindSpore モジュールの詳細な説明は、MindSpore API ページで検索できます。
context.set_contextにより動作モード、バックエンド情報、ハードウェア等の動作に必要な情報を設定できます。
コンテキストモジュールをインポートし、動作に必要な情報を設定します。
- %matplotlib inline
- import os
- import csv
- import numpy as np
- import matplotlib.pyplot as plt
-
- import mindspore as ms
- from mindspore import nn, ops
-
- ms.set_context(device_target="CPU")

wine.dataをクリックして、いくつかのデータを表示します。- with open('wine.data') as csv_file:
- data = list(csv.reader(csv_file, delimiter=','))
- print(data[56:62]+data[130:133])
[['1', '14.22', '1.7', '2.3', '16.3', '118', '3.2', '3', '.26', '2.03', '6.38', '.94', '3.31', '970'], ['1', '13.29', '1.97', '2.68', '16.8', '102', '3', '3.23', '.31', '1.66', '6', '1.07', '2.84', '1270'], ['1', '13.72', '1.43', '2.5', '16.7', '108', '3.4', '3.67', '.19', '2.04', '6.8', '.89', '2.87', '1285'], ['2', '12.37', '.94', '1.36', '10.6', '88', '1.98', '.57', '.28', '.42', '1.95', '1.05', '1.82', '520'], ['2', '12.33', '1.1', '2.28', '16', '101', '2.05', '1.09', '.63', '.41', '3.27', '1.25', '1.67', '680'], ['2', '12.64', '1.36', '2.02', '16.8', '100', '2.02', '1.41', '.53', '.62', '5.75', '.98', '1.59', '450'], ['3', '12.86', '1.35', '2.32', '18', '122', '1.51', '1.25', '.21', '.94', '4.1', '.76', '1.29', '630'], ['3', '12.88', '2.99', '2.4', '20', '104', '1.3', '1.22', '.24', '.83', '5.4', '.74', '1.42', '530'], ['3', '12.81', '2.31', '2.4', '24', '98', '1.15', '1.09', '.27', '.83', '5.7', '.66', '1.36', '560']]
- X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
- Y = np.array([s[0] for s in data[:178]], np.int32)
- attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
- 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
- 'OD280/OD315 of diluted wines', 'Proline']
- plt.figure(figsize=(10, 8))
- for i in range(0, 4):
- plt.subplot(2, 2, i+1)
- a1, a2 = 2 * i, 2 * i + 1
- plt.scatter(X[:59, a1], X[:59, a2], label='1')
- plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
- plt.scatter(X[130:, a1], X[130:, a2], label='3')
- plt.xlabel(attrs[a1])
- plt.ylabel(attrs[a2])
- plt.legend()
- plt.show()
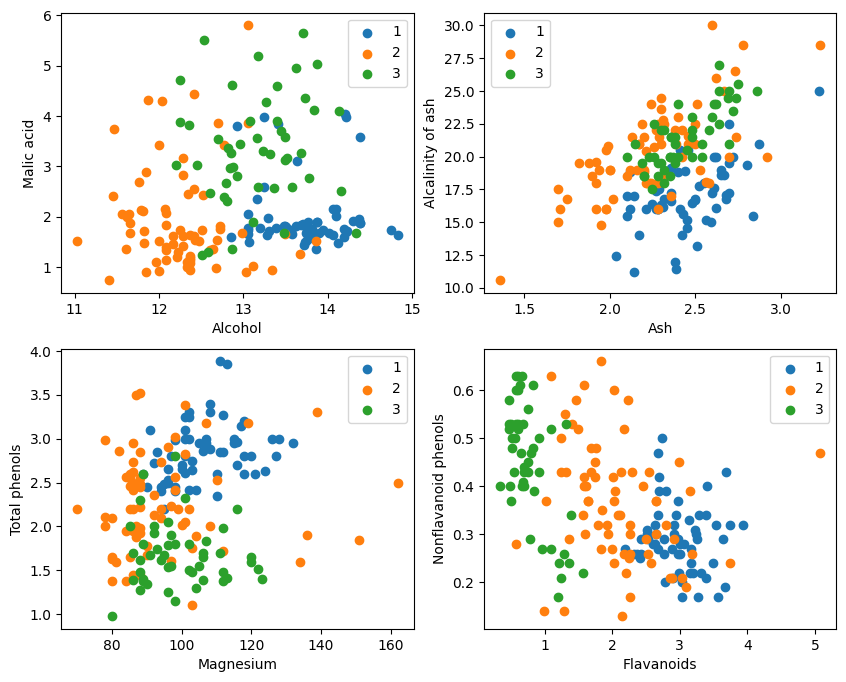
グラフィック表示からは、グラフの左上隅と右下隅の 2 つの属性分類効果が比較的良好であり、特にカテゴリ 1 とカテゴリ 2 の間の境界が比較的明白です。
- train_idx = np.random.choice(178, 128, replace=False)
- test_idx = np.array(list(set(range(178)) - set(train_idx)))
- X_train, Y_train = X[train_idx], Y[train_idx]
- X_test, Y_test = X[test_idx], Y[test_idx]
分解test_idx = np.array(list(set(range(178)) - set(train_idx)))
1. range(178) は、0 から 177 までの整数のシーケンスを生成します。
2. set(range(178)) は、この一連の整数をセットに変換します。セットは、要素の繰り返しを許可せず、効率的なセット演算 (和集合、交差、差分など) をサポートするデータ構造です。
3. set(train_idx) は、ランダムに選択されたトレーニング セット インデックス リスト train_idx をセットに変換します。
4. set(range(178)) - set(train_idx) は、セットの差集合演算を計算し、set(range(178)) にはあるが set(train_idx) には含まれていない要素を取得します。お試しセット。これは、差分要素を迅速かつ効率的に計算できる集合演算です。
5. list(...) は、差分演算の結果をリストに変換します。
6. np.array(...) は、このリストを numpy 配列に変換し、numpy 配列 X および Y でインデックスを付けます。。
MindSpore が提供するものを活用するtile, square, ReduceSum, sqrt, TopKおよび他の演算子は、行列演算を通じて入力サンプル x と他の明確に分類されたサンプル X_train の間の距離を同時に計算し、上位 k 個の最近傍を計算します。
- class KnnNet(nn.Cell):
- def __init__(self, k):
- super(KnnNet, self).__init__()
- self.k = k
-
- def construct(self, x, X_train):
- #平铺输入x以匹配X_train中的样本数
- x_tile = ops.tile(x, (128, 1))
- square_diff = ops.square(x_tile - X_train)
- square_dist = ops.sum(square_diff, 1)
- dist = ops.sqrt(square_dist)
- #-dist表示值越大,样本就越接近
- values, indices = ops.topk(-dist, self.k)
- return indices
-
- def knn(knn_net, x, X_train, Y_train):
- x, X_train = ms.Tensor(x), ms.Tensor(X_train)
- indices = knn_net(x, X_train)
- topk_cls = [0]*len(indices.asnumpy())
- for idx in indices.asnumpy():
- topk_cls[Y_train[idx]] += 1
- cls = np.argmax(topk_cls)
- return cls
1. KNN ネットワーク クラスを定義します: KnnNet
__init__ 関数: ネットワークを初期化し、K 値 (つまり、選択された最近傍の数) を設定します。
構築関数: 入力サンプル x とトレーニング セット X_train 内の各サンプル間のユークリッド距離を計算し、距離が最小の k (つまり最近傍) サンプルのインデックスを返します。
2. KNN 関数を定義します: knn
knn_net (KNN ネットワーク インスタンス)、テスト サンプル x、トレーニング サンプル X_train、トレーニング ラベル Y_train を入力として受け取ります。
knn_net を使用して、x の k 個の最近傍サンプルを見つけ、これらのサンプルのラベルに従ってそれらを分類し、分類結果 (つまり、予測されたカテゴリ) を返します。
在验证集上验证KNN算法的有效性,取𝑘=5,验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
- acc = 0
- knn_net = KnnNet(5)
- for x, y in zip(X_test, Y_test):
- pred = knn(knn_net, x, X_train, Y_train)
- acc += (pred == y)
- print('label: %d, prediction: %s' % (y, pred))
- print('Validation accuracy is %f' % (acc/len(Y_test)))
テストセットの精度を計算して印刷します。
テスト セット X_test および Y_test 内の各サンプルをループし、関数 knn を使用して各サンプルを分類します。
統計は正しいサンプルの数を予測し、分類の精度を計算して出力します。
label: 1, prediction: 1 label: 2, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 2 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 Validation accuracy is 0.660000
毎回 80% を達成することは不可能ですが、何度も試行した結果、最終的に精度は 80% に達しました。
label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 3 label: 3, prediction: 3 label: 1, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 Validation accuracy is 0.820000
この実験では、MindSpore を使用して KNN アルゴリズムを実装し、3 分類問題を解決します。ワインデータセット上の 3 種類のサンプルを取得し、それらを既知のカテゴリのサンプルと検証対象のサンプルに分割する検証結果から、KNN アルゴリズムがこのタスクに有効であり、以下に基づいてワインの種類を決定できることがわかります。ワインの13の属性。
データの準備: Wine データセットの公式 Web サイトまたは Huawei Cloud OBS からデータをダウンロードし、読み取って処理します。
データ処理: データセットを独立変数 (13 属性) と従属変数 (3 カテゴリ) に分割し、それらを視覚化してサンプル分布を観察します。
モデルの構築: KNN ネットワーク構造を定義し、MindSpore が提供する演算子を使用して入力サンプルとトレーニング サンプル間の距離を計算し、最も近い k 個の近傍を見つけます。
モデル予測: 検証セットで予測を行い、予測精度を計算します。
実験結果は、Wine データセットに対する KNN アルゴリズムの分類精度が 80% (66%) に近いことを示しています。

彼は 30 年以上テクノロジーの研究に専念しており、java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: