2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

Hoc experimentum maxime usum MindSporis introducit ad experimenta KNN in aliquo vino dato inducens.
K-Narest-Vicinus (KNN) est methodus statistica parametrica pro classificatione et regressione, primum a Cover et Hart, anno 1968 proposita.Cover et al., 1967 ), est algorithmorum fundamentalium in machina discendi. Fundatur in superiori idea: genus exempli definire, distantiam ab omni disciplinarum exemplorum computare potes, deinde exempla k proximis specimen invenire, genera horum exemplorum computa, ac suffragium plurimae suffragiorum genus is the result of classification. Tria elementa fundamentalia KNN;
K valorem, classificatio exempli determinatur per "majorem suffragium" proximorum K. Quoque minor est K aestimatio, eo facilius sonitu afficitur. Quin potius circumscriptiones inter genera turbabuntur.
Distantia mensurae similitudinem inter duo exempla in pluma spatium reflectit. Vulgo adhibitae sunt distantiae Lp (cum p=2, est spatium Euclideum), Manhattan spatium, Hamming intervallum, etc.
Classificationis decisionum regulae, plerumque maioritas suffragationis, vel maioritas suffragiorum in distantia ponderis innixa (pondera sunt inverse proportionalia distantiae).
Rationes statisticae non-parametricae ad methodos statisticas spectant, quae in formis parametricis non nituntur (qualis est normalis distributio suppositionis in statisticis traditis, etc.), hoc est, non faciunt principia stricte de data distributione. Comparati cum methodis statisticis parametricis (ut regressio linearis, t-test, etc.), statisticae non-parametricae magis flexibiles sunt, quia non assumunt, quod notitia certae distributionis exemplar consequitur.
Modi statisticae parametrici nituntur in certis suppositis et requisitis ad distributionem datam faciendam, et utimur quibusdam parametris ad describendam figuram distributionis notitiarum. Hae formae parametricae signanter simpliciorem reddere possunt exempla et analyses, sed etiam indigent suppositionibus et parametris ut cum ipsa notitia consentanea sint, quae concludere possunt ad seductionem cum suppositionibus non occurrentibus.
Linearibus 1. Regressionem:
Assumptio: Est relatio linearis inter variabilis dependens (variabilis responsio) et independens variabilis (variabilis explicationis).
Parametri: Regressio coefficientium (clivi et intercipiendi), fere supponens terminum erroris nihilum habere medium, constantem dissidentiam (homoskedasticity) ac distributionem normalem.
2. Regressio Logistic:
Assumptio: Dependens variabilis (variabilis categorica) exemplar regressionis logisticae satisfacit, et regressio coefficiens valorem certum est.
Parameter: Regressio coefficiens, influentiam variabilium independentium variabilium dependens, maximam aestimationem verisimilis aestimavit.
3. t-test;
Assumptio: The sample data ex normaliter distributa multitudo.
Parametri: medium et variatum, unum exemplum medium incolarum sumit, duo-sempla experimentum sumit differentiam inter mediorum duarum incolarum.
Praenuntiationis processus algorithmus (classificationis) talis est:
(1) Reperio exempla k proxima ad specimen probatum x_test in forma formativa statuta et salva ea in N statuto;
(2)统计集合N中每一类样本的个数𝐶𝑖,𝑖=1,2,3,...,𝑐;
(3)最终的分类结果为argmax𝐶𝑖 (最大的对应的𝐶𝑖)那个类。
In processu exsecutione supra, valor ipsius k magni momenti est. Determinari potest secundum problematum notas et notas. In exsecutione specifica, pondus exempli considerari potest, hoc est, unumquodque specimen aliud pondus suffragii habet. Haec methodus vocatur algorithm gravem proximum k-proximum, quod est variatio proximi algorithmi k-proximi.
假设离测试样本最近的k个训练样本的标签值为𝑦𝑖,则对样本的回归预测输出值为:

Istud est medium valorem pittacii omnium vicinorum.
Regressio praedictionis munus cum ponderibus sample est:

其中𝑤𝑖为第个𝑖样本的权重。
KNN算法的实现依赖于样本之间的距离,其中最常用的距离函数就是欧氏距离(欧几里得距离)。ℝ𝑛空间中的两点𝑥和𝑦,它们之间的欧氏距离定义为:
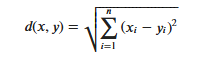
Animadvertendum est quod, cum distantiae Euclideae utens, unumquodque elementum vectoris lineae normalizari debet ad impedimentum reducendum quod variae scalae elatae lineae liniamenta valorum sunt values.
Aliae rationes distantiae calculi includit Mahalanobis distantiam, distantiam Bhattacharyya, etc.
Praevia cognitio;
lab ambitu:
Data copia vini est unum ex clarissimis notitias pro exemplaris recognitione.Vinum Data Set . Notitia analysis chemicae vinorum ex eadem regione Italiae proveniunt, sed ex tribus variis generibus. Data copia analyses summas 13 ingredientium in singulis vinis tribus contentas.Haec XIII attributa sunt
| Clavis | Precium | Clavis | Precium |
|---|---|---|---|
| Data Set Characteres: | Multivariate | Numerus instantiarum: | 178 |
| Characteres attributi: | Integer, Real | Numerus attributorum: | 13 |
| Negotium Associatur: | Classification | Absentis Pretio? | No |
- %%capture captured_output
- # 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
- !pip uninstall mindspore -y
- !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
- # 查看当前 mindspore 版本
- !pip show mindspore
Name: mindspore Version: 2.2.14 Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Home-page: https://www.mindspore.cn Author: The MindSpore Authors Author-email: [email protected] License: Apache 2.0 Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy Required-by:
- from download import download
-
- # 下载红酒数据集
- url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
- path = download(url, "./", kind="zip", replace=True)
Downloading data from https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip (4 kB) file_sizes: 100%|██████████████████████████| 4.09k/4.09k [00:00<00:00, 2.51MB/s] Extracting zip file... Successfully downloaded / unzipped to ./
Antequam generare notitias, Python bibliothecas requiri importat.
In bibliotheca os currently adhibetur.
Detailed descriptiones moduli MindSpore investigabiles possunt in pagina MindSpore API.
Configurare potes informationes ad operandum requisitas per context.set_contextum, ut modus operationis, notitia tergum, hardware et alia informationes.
Contextum moduli importe et informationes ad operandum requisitas configurare.
- %matplotlib inline
- import os
- import csv
- import numpy as np
- import matplotlib.pyplot as plt
-
- import mindspore as ms
- from mindspore import nn, ops
-
- ms.set_context(device_target="CPU")

wine.dataac nonnulla.- with open('wine.data') as csv_file:
- data = list(csv.reader(csv_file, delimiter=','))
- print(data[56:62]+data[130:133])
[['1', '14.22', '1.7', '2.3', '16.3', '118', '3.2', '3', '.26', '2.03', '6.38', '.94', '3.31', '970'], ['1', '13.29', '1.97', '2.68', '16.8', '102', '3', '3.23', '.31', '1.66', '6', '1.07', '2.84', '1270'], ['1', '13.72', '1.43', '2.5', '16.7', '108', '3.4', '3.67', '.19', '2.04', '6.8', '.89', '2.87', '1285'], ['2', '12.37', '.94', '1.36', '10.6', '88', '1.98', '.57', '.28', '.42', '1.95', '1.05', '1.82', '520'], ['2', '12.33', '1.1', '2.28', '16', '101', '2.05', '1.09', '.63', '.41', '3.27', '1.25', '1.67', '680'], ['2', '12.64', '1.36', '2.02', '16.8', '100', '2.02', '1.41', '.53', '.62', '5.75', '.98', '1.59', '450'], ['3', '12.86', '1.35', '2.32', '18', '122', '1.51', '1.25', '.21', '.94', '4.1', '.76', '1.29', '630'], ['3', '12.88', '2.99', '2.4', '20', '104', '1.3', '1.22', '.24', '.83', '5.4', '.74', '1.42', '530'], ['3', '12.81', '2.31', '2.4', '24', '98', '1.15', '1.09', '.27', '.83', '5.7', '.66', '1.36', '560']]
- X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
- Y = np.array([s[0] for s in data[:178]], np.int32)
- attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
- 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
- 'OD280/OD315 of diluted wines', 'Proline']
- plt.figure(figsize=(10, 8))
- for i in range(0, 4):
- plt.subplot(2, 2, i+1)
- a1, a2 = 2 * i, 2 * i + 1
- plt.scatter(X[:59, a1], X[:59, a2], label='1')
- plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
- plt.scatter(X[130:, a1], X[130:, a2], label='3')
- plt.xlabel(attrs[a1])
- plt.ylabel(attrs[a2])
- plt.legend()
- plt.show()
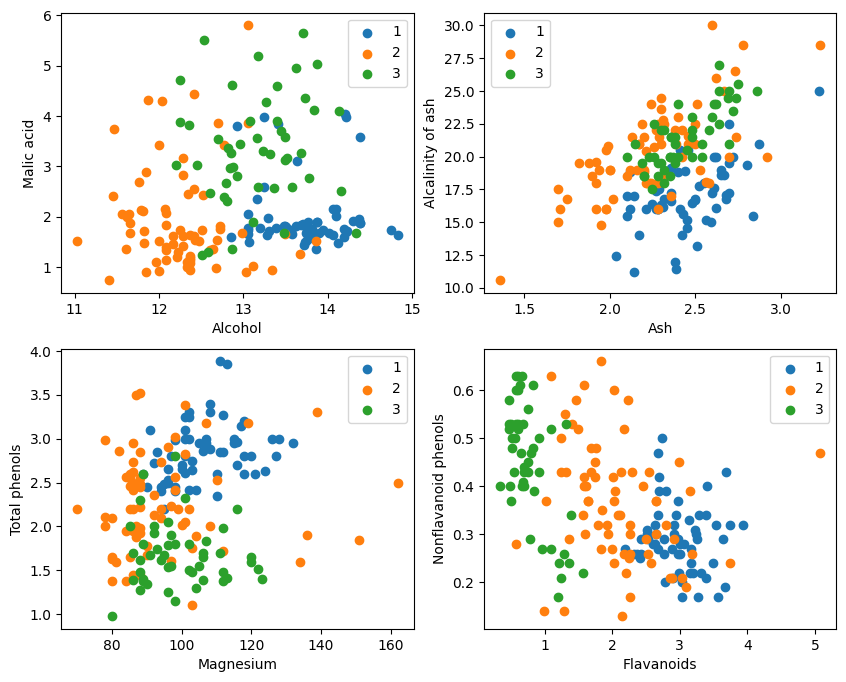
Ex graphice ostentatione, duo effectus classificationis attributi in angulo sinistro superiore et dextro graphi angulo dextro inferiores sunt relativi boni, praesertim termini inter genera 1 et 2 relativorum manifesti sunt.
- train_idx = np.random.choice(178, 128, replace=False)
- test_idx = np.array(list(set(range(178)) - set(train_idx)))
- X_train, Y_train = X[train_idx], Y[train_idx]
- X_test, Y_test = X[test_idx], Y[test_idx]
分解test_idx = np.array(list(set(range (178)) - set(train_idx)))
1. range (178) generat ordinem integrorum ab 0 ad 177.
2. paro(range (178)) hanc seriem integrorum in statuto convertit. Copia data est structura quae crebris elementis sustinet nec operationes constituit efficientes (ut unionem, intersectionem, differentiam etc.).
3. paro(train_idx) convertens passim electa formatio index indices train_idx in statuto.
4. paro(range (178)) - set (train_idx) differentiam determinati operationis computat et obtinet elementa quae in statuto(178)) sed non in statuto (train_idx), quae sunt indices test posuit. Operatio haec est, quae cito et efficaciter differentiam elementorum computare potest.
5. album(...) eventum differentiae operationis in album vertit.
6. np.array(...) hunc album in numpy vertit ad indexing cum numpy vestit X et Y。
Abutendumque quod MindSpore offerstile, square, ReduceSum, sqrt, TopKet alii operatores simul computant distantiam inter input specimen x et alia exemplaria X_train per matrix operationes distincte classificatae et summo k proximis proximis computant.
- class KnnNet(nn.Cell):
- def __init__(self, k):
- super(KnnNet, self).__init__()
- self.k = k
-
- def construct(self, x, X_train):
- #平铺输入x以匹配X_train中的样本数
- x_tile = ops.tile(x, (128, 1))
- square_diff = ops.square(x_tile - X_train)
- square_dist = ops.sum(square_diff, 1)
- dist = ops.sqrt(square_dist)
- #-dist表示值越大,样本就越接近
- values, indices = ops.topk(-dist, self.k)
- return indices
-
- def knn(knn_net, x, X_train, Y_train):
- x, X_train = ms.Tensor(x), ms.Tensor(X_train)
- indices = knn_net(x, X_train)
- topk_cls = [0]*len(indices.asnumpy())
- for idx in indices.asnumpy():
- topk_cls[Y_train[idx]] += 1
- cls = np.argmax(topk_cls)
- return cls
1. Definire KNN network genus: KnnNet
__init__ function: Initialize retis et pone valorem K (id est numerus proximi proximi delecti).
functionem construe: Euclidea computa distantiam inter specimen x input et unumquodque specimen in disciplina X_train positum, et redde indicem exemplorum k (id est vicini proximi) minimo intervallo.
2. Definire munus KNN: knn
Knn_net (KNN retis exempli gratia), test sample x, formatio exempli X_train et institutio label Y_train sicut input.
Utere knn_net ad exempla proxima k proxima ipsius x invenire, ea secundum pittacia exemplarium indica, et proventum classificationem redde (i.e. praedicationem praedicatam).
在验证集上验证KNN算法的有效性,取𝑘=5,验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
- acc = 0
- knn_net = KnnNet(5)
- for x, y in zip(X_test, Y_test):
- pred = knn(knn_net, x, X_train, Y_train)
- acc += (pred == y)
- print('label: %d, prediction: %s' % (y, pred))
- print('Validation accuracy is %f' % (acc/len(Y_test)))
Calculare et imprimere subtiliter test paro
Lope per singulas specimen in testi X_test et Y_test, et uti knn functioni ad singula exempla referenda.
Statistics numerum exemplorum rectarum praedicunt, subtiliter classificationis computant et output.
label: 1, prediction: 1 label: 2, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 2 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 Validation accuracy is 0.660000
Fieri non potest ut omni tempore 80% consequi possit.
label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 3 label: 3, prediction: 3 label: 1, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 Validation accuracy is 0.820000
Hoc experimentum MindSpore utitur ad algorithmum KNN efficiendum ad problema III classificationis solvendum. Sume 3 genera speciminum in vino datos et in notis categoriis exempla et exempla ut verificanda divide. Vini attributa XIII.
Praeparatio data: data e Vino dataset rutrum vel Huawei Cloud OBS, lege et processum est.
MGE: Data commoda in variabiles independens (13 attributa) et variabilium dependentium (3 genera), divide et visualise ut distributio specimen observet.
Exemplar constructionis: Definire structuram retis KNN, auctoris uti ab MindSpore proviso computare distantiam inter specimen input specimen et formationem disciplinae, et proximos k proximos invenire.
Exemplar praedictum: Fac praedictiones in radice convalidationis et accurate praedictionem computa.
Eventus experimentales ostendunt accurationem algorithmi KNN in notitia copiae Vini classificationem prope 80% (66%).

technologiae technologiae plus quam 30 annos operam dedit et in variis linguis proficit ut java, linux, javascript, php, css, etc. Multas contributiones in aperto fonte campo fecit elit documentorum statione ad communicandas quaestiones technologiarum progressus ad futuram referentiam

