
내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
AI를 학습하면 상금을 받을 수 있나요? 하루 30분, 25일 동안 AI 렌두 세컨드 메리디안(qq.com)을 열어보세요

이 실험에서는 주로 MindSpore를 사용하여 일부 와인 데이터 세트에 대한 KNN 실험을 수행하는 방법을 소개합니다.
KNN(K-Nearest-Neighbor)은 1968년 Cover와 Hart가 처음 제안한 분류 및 회귀를 위한 비모수적 통계 방법입니다(커버 등, 1967 )은 머신러닝의 가장 기본적인 알고리즘 중 하나입니다. 이는 위의 아이디어를 기반으로 합니다. 샘플의 범주를 결정하려면 모든 훈련 샘플과의 거리를 계산한 다음 샘플에 가장 가까운 k개 샘플을 찾고 이러한 샘플의 범주를 계산한 다음 투표할 수 있습니다. 가장 많은 표를 얻은 클래스는 분류 결과입니다. KNN의 세 가지 기본 요소:
K 값, 샘플의 분류는 K 이웃의 "과반수 투표"에 의해 결정됩니다. K 값이 작을수록 노이즈의 영향을 받기 쉬워지고, 반대로 카테고리 간의 경계가 흐려집니다.
거리 측정은 특징 공간에 있는 두 샘플 간의 유사성을 반영합니다. 거리가 작을수록 샘플이 더 유사합니다. 일반적으로 사용되는 거리에는 Lp 거리(p=2일 때 유클리드 거리), Manhattan 거리, Hamming 거리 등이 있습니다.
분류 결정 규칙은 일반적으로 다수결 또는 거리 가중치를 기반으로 하는 다수결입니다(가중치는 거리에 반비례합니다).
비모수적 통계 방법은 모수적 형식(예: 전통적인 통계의 정규 분포 가정 등)에 의존하지 않는 통계 방법, 즉 데이터 분포에 대해 엄격한 가정을 하지 않는 통계 방법을 말합니다. 모수적 통계 방법(예: 선형 회귀, t-검정 등)과 비교할 때 비모수적 통계 방법은 데이터가 특정 분포 패턴을 따른다고 가정하지 않기 때문에 더 유연합니다.
모수적 통계 방법은 데이터 분포에 대한 특정 가정과 요구 사항을 만드는 데 의존하며 특정 매개변수를 사용하여 데이터의 분포 형태를 설명합니다. 이러한 매개변수 형식은 모델과 분석을 크게 단순화할 수 있지만 이러한 가정과 매개변수가 실제 데이터와 일치해야 하므로 가정이 충족되지 않을 경우 잘못된 결론을 내릴 수 있습니다.
1. 선형 회귀:
가정: 종속변수(반응변수)와 독립변수(설명변수) 사이에는 선형 관계가 있습니다.
매개변수: 회귀 계수(기울기 및 절편). 일반적으로 오류 항의 평균이 0이고 분산이 일정하며(동분산성) 정규 분포가 있다고 가정합니다.
2. 로지스틱 회귀:
가정: 종속변수(범주형변수)는 로지스틱 회귀모형을 만족하며, 회귀계수는 고정된 값이다.
모수: 독립변수가 종속변수에 미치는 영향을 설명하는 데 사용되는 회귀계수로, 최대 우도 추정을 통해 추정됩니다.
3. t-테스트:
가정: 표본 데이터는 정규 분포 모집단에서 나옵니다.
매개변수: 평균 및 분산, 1표본 t-검정은 모집단 평균을 가정하고 2-표본 t-검정은 두 모집단 평균 간의 차이를 가정합니다.
예측 알고리즘(분류)의 과정은 다음과 같습니다.
(1) 훈련 샘플 세트에서 테스트 샘플 x_test에 가장 가까운 k 샘플을 찾아 세트 N에 저장합니다.
(2)统计集合N中每一类样本的个数𝐶𝑖,𝑖=1,2,3,...,𝑐;
(3)最终的分类结果为argmax𝐶𝑖 (最大的对应的𝐶𝑖)那个类。
위의 구현 과정에서 k 값은 특히 중요합니다. 문제와 데이터의 특성을 토대로 판단할 수 있습니다. 구체적인 구현에서는 샘플의 가중치를 고려할 수 있습니다. 즉, 각 샘플은 서로 다른 투표 가중치를 갖습니다. 이 방법을 k-최근접 이웃 알고리즘의 변형인 가중치 k-최근접 이웃 알고리즘이라고 합니다.
假设离测试样本最近的k个训练样本的标签值为𝑦𝑖,则对样本的回归预测输出值为:

이는 모든 이웃의 평균 레이블 값입니다.
샘플 가중치를 사용한 회귀 예측 함수는 다음과 같습니다.

其中𝑤𝑖为第个𝑖样本的权重。
KNN算法的实现依赖于样本之间的距离,其中最常用的距离函数就是欧氏距离(欧几里得距离)。ℝ𝑛空间中的两点𝑥和𝑦,它们之间的欧氏距离定义为:
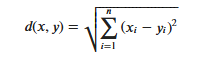
유클리드 거리를 사용할 때 특징 벡터의 각 구성 요소는 특징 값의 다양한 스케일 범위로 인한 간섭을 줄이기 위해 정규화되어야 합니다. 그렇지 않으면 작은 값을 가진 특징 구성 요소가 큰 특징으로 대체됩니다. 값은 특징적인 구성 요소가 잠겨 있습니다.
다른 거리 계산 방법으로는 Mahalanobis 거리, Bhattacharyya 거리 등이 있습니다.
예비 지식:
연구실 환경:
Wine 데이터 세트는 패턴 인식을 위한 가장 유명한 데이터 세트 중 하나입니다. Wine 데이터 세트의 공식 웹사이트는 다음과 같습니다.와인 데이터 세트 . 데이터는 이탈리아의 같은 지역에서 생산되었지만 세 가지 다른 품종의 와인을 화학적으로 분석한 결과입니다. 데이터 세트는 세 가지 와인 각각에 포함된 13가지 성분의 양을 분석합니다.이 13가지 속성은
| 열쇠 | 값 | 열쇠 | 값 |
|---|---|---|---|
| 데이터 세트 특성: | 다변량 | 인스턴스 수: | 178 |
| 속성 특성: | 정수, 실수 | 속성 수: | 13 |
| 연관된 작업: | 분류 | 값이 누락되었습니까? | 아니요 |
- %%capture captured_output
- # 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
- !pip uninstall mindspore -y
- !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
- # 查看当前 mindspore 版本
- !pip show mindspore
Name: mindspore Version: 2.2.14 Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Home-page: https://www.mindspore.cn Author: The MindSpore Authors Author-email: [email protected] License: Apache 2.0 Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy Required-by:
- from download import download
-
- # 下载红酒数据集
- url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
- path = download(url, "./", kind="zip", replace=True)
Downloading data from https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip (4 kB) file_sizes: 100%|██████████████████████████| 4.09k/4.09k [00:00<00:00, 2.51MB/s] Extracting zip file... Successfully downloaded / unzipped to ./
데이터를 생성하기 전에 필요한 Python 라이브러리를 가져옵니다.
현재는 os 라이브러리를 사용하고 있으며, 이해를 돕기 위해 구체적으로 사용할 때 필요한 기타 라이브러리에 대해서도 설명하겠습니다.
자세한 MindSpore 모듈 설명은 MindSpore API 페이지에서 검색할 수 있습니다.
context.set_context를 통해 동작 모드, 백엔드 정보, 하드웨어, 기타 정보 등 동작에 필요한 정보를 구성할 수 있습니다.
컨텍스트 모듈을 가져와서 작업에 필요한 정보를 구성합니다.
- %matplotlib inline
- import os
- import csv
- import numpy as np
- import matplotlib.pyplot as plt
-
- import mindspore as ms
- from mindspore import nn, ops
-
- ms.set_context(device_target="CPU")

wine.data, 일부 데이터를 봅니다.- with open('wine.data') as csv_file:
- data = list(csv.reader(csv_file, delimiter=','))
- print(data[56:62]+data[130:133])
[['1', '14.22', '1.7', '2.3', '16.3', '118', '3.2', '3', '.26', '2.03', '6.38', '.94', '3.31', '970'], ['1', '13.29', '1.97', '2.68', '16.8', '102', '3', '3.23', '.31', '1.66', '6', '1.07', '2.84', '1270'], ['1', '13.72', '1.43', '2.5', '16.7', '108', '3.4', '3.67', '.19', '2.04', '6.8', '.89', '2.87', '1285'], ['2', '12.37', '.94', '1.36', '10.6', '88', '1.98', '.57', '.28', '.42', '1.95', '1.05', '1.82', '520'], ['2', '12.33', '1.1', '2.28', '16', '101', '2.05', '1.09', '.63', '.41', '3.27', '1.25', '1.67', '680'], ['2', '12.64', '1.36', '2.02', '16.8', '100', '2.02', '1.41', '.53', '.62', '5.75', '.98', '1.59', '450'], ['3', '12.86', '1.35', '2.32', '18', '122', '1.51', '1.25', '.21', '.94', '4.1', '.76', '1.29', '630'], ['3', '12.88', '2.99', '2.4', '20', '104', '1.3', '1.22', '.24', '.83', '5.4', '.74', '1.42', '530'], ['3', '12.81', '2.31', '2.4', '24', '98', '1.15', '1.09', '.27', '.83', '5.7', '.66', '1.36', '560']]
- X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
- Y = np.array([s[0] for s in data[:178]], np.int32)
- attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
- 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
- 'OD280/OD315 of diluted wines', 'Proline']
- plt.figure(figsize=(10, 8))
- for i in range(0, 4):
- plt.subplot(2, 2, i+1)
- a1, a2 = 2 * i, 2 * i + 1
- plt.scatter(X[:59, a1], X[:59, a2], label='1')
- plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
- plt.scatter(X[130:, a1], X[130:, a2], label='3')
- plt.xlabel(attrs[a1])
- plt.ylabel(attrs[a2])
- plt.legend()
- plt.show()
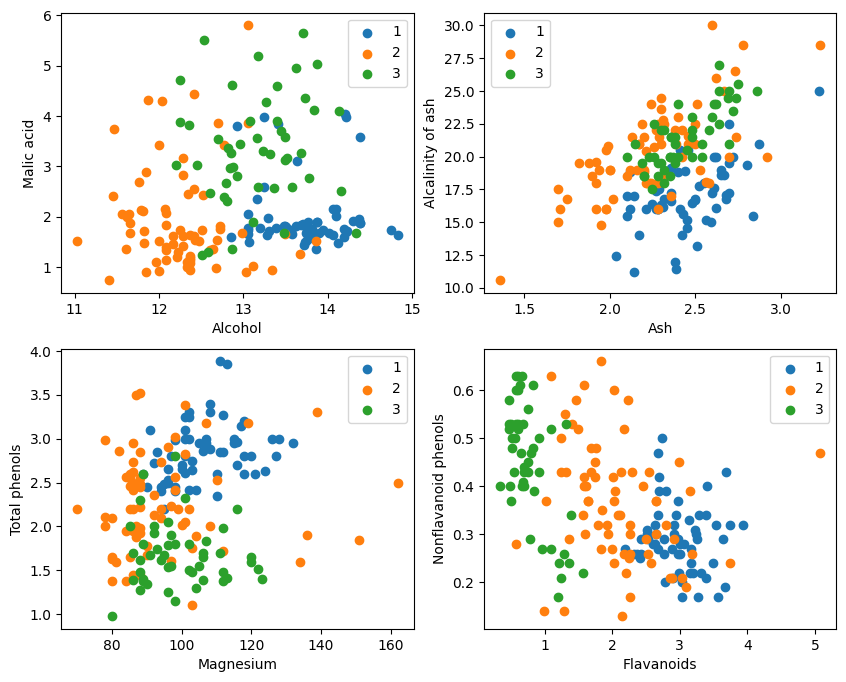
그래픽 표시에서 그래프의 왼쪽 상단 모서리와 오른쪽 하단 모서리에 있는 두 가지 속성 분류 효과가 상대적으로 양호하며, 특히 카테고리 1과 2 사이의 경계가 상대적으로 분명합니다.
- train_idx = np.random.choice(178, 128, replace=False)
- test_idx = np.array(list(set(range(178)) - set(train_idx)))
- X_train, Y_train = X[train_idx], Y[train_idx]
- X_test, Y_test = X[test_idx], Y[test_idx]
test_idx를 분배하세요 = np.array(list(set(range(178)) - set(train_idx)))
1. range(178)는 0부터 177까지의 정수 시퀀스를 생성합니다.
2. set(range(178))은 이 정수 시퀀스를 집합으로 변환합니다. 집합은 반복되는 요소를 허용하지 않고 효율적인 집합 연산(합집합, 교차점, 차이 등)을 지원하는 데이터 구조입니다.
3. set(train_idx)는 무작위로 선택된 훈련 세트 인덱스 목록 train_idx를 세트로 변환합니다.
4. set(range(178)) - set(train_idx)는 집합의 차이 집합 연산을 계산하고 set(range(178))에는 있지만 set(train_idx)에는 없는 요소를 가져옵니다. 테스트 세트. 이는 차분 요소를 빠르고 효율적으로 계산할 수 있는 집합 연산입니다.
5. list(...)는 차이 연산의 결과를 다시 목록으로 변환합니다.
6. np.array(...)는 numpy 배열 X 및 Y를 사용하여 인덱싱하기 위해 이 목록을 numpy 배열로 변환합니다.。
MindSpore가 제공하는 기능을 활용하세요tile, square, ReduceSum, sqrt, TopK및 기타 연산자는 행렬 연산을 통해 입력 샘플 x와 명확하게 분류된 다른 샘플 X_train 사이의 거리를 동시에 계산하고 상위 k개의 최근접 이웃을 계산합니다.
- class KnnNet(nn.Cell):
- def __init__(self, k):
- super(KnnNet, self).__init__()
- self.k = k
-
- def construct(self, x, X_train):
- #平铺输入x以匹配X_train中的样本数
- x_tile = ops.tile(x, (128, 1))
- square_diff = ops.square(x_tile - X_train)
- square_dist = ops.sum(square_diff, 1)
- dist = ops.sqrt(square_dist)
- #-dist表示值越大,样本就越接近
- values, indices = ops.topk(-dist, self.k)
- return indices
-
- def knn(knn_net, x, X_train, Y_train):
- x, X_train = ms.Tensor(x), ms.Tensor(X_train)
- indices = knn_net(x, X_train)
- topk_cls = [0]*len(indices.asnumpy())
- for idx in indices.asnumpy():
- topk_cls[Y_train[idx]] += 1
- cls = np.argmax(topk_cls)
- return cls
1. KNN 네트워크 클래스 정의: KnnNet
__init__ 함수: 네트워크를 초기화하고 K 값(즉, 선택된 최근접 이웃의 수)을 설정합니다.
생성 함수: 입력 샘플 x와 훈련 세트 X_train의 각 샘플 사이의 유클리드 거리를 계산하고 거리가 가장 작은 k(가장 가까운 이웃) 샘플의 인덱스를 반환합니다.
2. KNN 함수 정의: knn
knn_net(KNN 네트워크 인스턴스), 테스트 샘플 x, 훈련 샘플 X_train 및 훈련 라벨 Y_train을 입력으로 받습니다.
knn_net을 사용하여 x의 가장 가까운 이웃 샘플 k개를 찾고, 이 샘플의 레이블에 따라 분류하고, 분류 결과(예: 예측 범주)를 반환합니다.
在验证集上验证KNN算法的有效性,取𝑘=5,验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
- acc = 0
- knn_net = KnnNet(5)
- for x, y in zip(X_test, Y_test):
- pred = knn(knn_net, x, X_train, Y_train)
- acc += (pred == y)
- print('label: %d, prediction: %s' % (y, pred))
- print('Validation accuracy is %f' % (acc/len(Y_test)))
테스트 세트의 정확도 계산 및 인쇄
테스트 세트 X_test 및 Y_test의 각 샘플을 반복하고 knn 함수를 사용하여 각 샘플을 분류합니다.
통계는 올바른 샘플 수를 예측하고 분류 정확도를 계산하여 출력합니다.
label: 1, prediction: 1 label: 2, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 2 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 Validation accuracy is 0.660000
매번 80%를 달성하는 것은 불가능합니다. 여러 번 시도한 끝에 정확도는 80%에 도달했습니다.
label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 3 label: 3, prediction: 3 label: 1, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 Validation accuracy is 0.820000
이 실험에서는 MindSpore를 사용하여 KNN 알고리즘을 구현하여 3-분류 문제를 해결합니다. 와인 데이터 세트에서 3가지 유형의 샘플을 가져와 알려진 카테고리 샘플과 검증할 샘플로 나눕니다. 검증 결과에서 우리는 KNN 알고리즘이 이 작업에 효과적이며 이를 기반으로 와인의 다양성을 결정할 수 있음을 알 수 있습니다. 와인의 13가지 속성.
데이터 준비: Wine 데이터 세트 공식 웹사이트 또는 Huawei Cloud OBS에서 데이터를 다운로드하고 읽고 처리합니다.
데이터 처리: 데이터 세트를 독립변수(13개 속성)와 종속변수(3개 범주)로 나누고 이를 시각화하여 표본 분포를 관찰합니다.
모델 구성: KNN 네트워크 구조를 정의하고 MindSpore에서 제공하는 연산자를 사용하여 입력 샘플과 훈련 샘플 사이의 거리를 계산하고 가장 가까운 k개의 이웃을 찾습니다.
모델 예측: 검증 세트에 대해 예측을 수행하고 예측 정확도를 계산합니다.
실험 결과 Wine 데이터 세트에 대한 KNN 알고리즘의 분류 정확도는 80%(66%)에 가까운 것으로 나타났습니다.

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com