2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

अयं प्रयोगः मुख्यतया केषुचित् वाइन-दत्तांशसमूहेषु केएनएन-प्रयोगान् कर्तुं MindSpore-इत्यस्य उपयोगस्य परिचयं करोति ।
K-Nearest-Neighbor (KNN) इति वर्गीकरणस्य प्रतिगमनस्य च गैर-पैरामीटरिकसांख्यिकीयपद्धतिः अस्ति, मूलतः १९६८ तमे वर्षे कवर-हार्टेन प्रस्ताविता (कवर एट अल., 1967 ), यन्त्रशिक्षणस्य मूलभूतानाम् अल्गोरिदम्-मध्ये अन्यतमम् अस्ति । उपर्युक्तविचारस्य आधारेण भवति यत् नमूनायाः श्रेणीं निर्धारयितुं भवान् सर्वेभ्यः प्रशिक्षणनमूनेभ्यः तस्य दूरं गणयितुं शक्नोति, ततः नमूनायाः समीपस्थं k नमूनानि अन्वेष्टुं शक्नोति, एतेषां नमूनानां श्रेणीं गणयितुं शक्नोति, तथा च The one with the most votes सः वर्गः वर्गीकरणस्य परिणामः अस्ति। केएनएन इत्यस्य त्रयः मूलभूततत्त्वानि : १.
K मूल्यं, नमूनायाः वर्गीकरणं K प्रतिवेशिनः "बहुमतमतेन" निर्धारितं भवति । K मूल्यं यथा लघु भवति तथा कोलाहलेन प्रभावितं भवितुं सुकरं भवति प्रत्युत श्रेणीनां सीमाः धुन्धलाः भविष्यन्ति ।
दूरमापः विशेषतास्थाने द्वयोः नमूनायोः साम्यं प्रतिबिम्बयति । सामान्यतया प्रयुक्तेषु Lp दूरी (यदा p=2 भवति तदा यूक्लिडियनदूरता भवति), Manhattan दूरी, Hamming दूरी इत्यादयः सन्ति ।
वर्गीकरणनिर्णयनियमाः, प्रायः बहुमतमतदानं, अथवा दूरभारस्य आधारेण बहुमतमतदानं (भाराः दूरस्य विपरीतरूपेण आनुपातिकाः भवन्ति) ।
अ-पैरामीटरिक-सांख्यिकीय-विधयः तान् सांख्यिकीय-विधयः निर्दिशन्ति ये पैरामीटरिक-रूपेषु (यथा पारम्परिक-सांख्यिकीयेषु सामान्य-वितरण-अनुमानम् इत्यादिषु) न अवलम्बन्ते, अर्थात् ते दत्तांश-वितरणस्य विषये कठोर-अनुमानं न कुर्वन्ति पैरामीटरिकसांख्यिकीयविधिभिः (यथा रेखीयप्रतिगमनम्, टी-परीक्षा इत्यादिभिः) तुलने, अ-पैरामीटरिकसांख्यिकीयविधयः अधिकं लचीलाः भवन्ति यतोहि ते न कल्पयन्ति यत् दत्तांशः विशिष्टवितरणप्रतिमानस्य अनुसरणं करोति
पैरामीटरिकसांख्यिकीयविधयः दत्तांशवितरणस्य विशिष्टानि धारणानि आवश्यकताश्च कर्तुं निर्भराः भवन्ति, तथा च दत्तांशस्य वितरणस्य आकारस्य वर्णनार्थं कतिपयानां मापदण्डानां उपयोगं कुर्वन्ति एते पैरामीटरिकरूपाः आदर्शान् विश्लेषणं च महत्त्वपूर्णतया सरलीकर्तुं शक्नुवन्ति, परन्तु तेषां कृते एतासां धारणानां मापदण्डानां च वास्तविकदत्तांशैः सह सङ्गतिः अपि आवश्यकी भवति, येन धारणानां पूर्तिः न भवति चेत् भ्रामकनिष्कर्षाः भवितुं शक्नुवन्ति
1. रेखीय प्रतिगमनम् : १.
धारणा : आश्रितचरस्य (प्रतिक्रियाचरस्य) स्वतन्त्रचरस्य (व्याख्यात्मकचरस्य) च रेखीयसम्बन्धः अस्ति ।
मापदण्डाः : प्रतिगमनगुणांकाः (प्रवणता तथा अवरोधः), सामान्यतया एतत् कल्पयित्वा यत् त्रुटिपदस्य शून्यं माध्यं, नित्यविचरणं (होमोस्केडास्टिसिटी), सामान्यवितरणं च भवति
2. लॉजिस्टिक रिग्रेशन : १.
धारणा: आश्रितः चरः (श्रेणीगतचरः) लॉजिस्टिकप्रतिगमनप्रतिरूपं सन्तुष्टं करोति, प्रतिगमनगुणकं च नियतमूल्यं भवति ।
पैरामीटर् : प्रतिगमनगुणकः, आश्रितचरानाम् उपरि स्वतन्त्रचरानाम् प्रभावस्य वर्णनार्थं प्रयुक्तः, अधिकतमसंभावनाअनुमानस्य माध्यमेन अनुमानितः
3. टी-परीक्षा : १.
धारणा : नमूनादत्तांशः सामान्यतया वितरितजनसंख्यातः आगच्छति ।
मापदण्डाः : औसतं विचरणं च, एकनमूना-टी-परीक्षा जनसंख्या-माध्यं गृह्णाति, द्वि-नमूना-टी-परीक्षा द्वयोः जनसंख्यायोः माध्ययोः मध्ये अन्तरं गृह्णाति
भविष्यवाणी एल्गोरिदमस्य (वर्गीकरणस्य) प्रक्रिया निम्नलिखितरूपेण अस्ति ।
(1) प्रशिक्षणनमूनासमूहे परीक्षणनमूना x_test इत्यस्य समीपस्थं k नमूनानि ज्ञात्वा N सेट् मध्ये रक्षन्तु;
(2)统计集合N中每一类样本的个数𝐶𝑖,𝑖=1,2,3,...,𝑐;
(3)最终的分类结果为argmax𝐶𝑖 (最大的对应的𝐶𝑖)那个类。
उपर्युक्ते कार्यान्वयनप्रक्रियायां k इत्यस्य मूल्यं विशेषतया महत्त्वपूर्णं भवति । समस्यायाः, दत्तांशलक्षणस्य च आधारेण निर्धारयितुं शक्यते । विशिष्टकार्यन्वयने नमूनायाः भारं विचारयितुं शक्यते, अर्थात् प्रत्येकस्य नमूनायाः भिन्नः मतदानभारः भवति एषा पद्धतिः भारित-समीपस्थ-परिजन-अल्गोरिदम् इति कथ्यते, यत् k-समीपस्थ-परिजन-अल्गोरिदम्-इत्यस्य एकः प्रकारः अस्ति
假设离测试样本最近的k个训练样本的标签值为𝑦𝑖,则对样本的回归预测输出值为:

सः सर्वेषां प्रतिवेशिनां मध्यमं लेबलमूल्यं भवति ।
नमूनाभारयुक्तं प्रतिगमनपूर्वसूचनाकार्यं भवति :

其中𝑤𝑖为第个𝑖样本的权重。
KNN算法的实现依赖于样本之间的距离,其中最常用的距离函数就是欧氏距离(欧几里得距离)。ℝ𝑛空间中的两点𝑥和𝑦,它们之间的欧氏距离定义为:
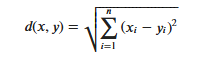
ज्ञातव्यं यत् यूक्लिडियन-अन्तरस्य उपयोगं कुर्वन् विशेषता-मूल्यानां भिन्न-भिन्न-स्केल-परिधिभिः उत्पद्यमानं हस्तक्षेपं न्यूनीकर्तुं विशेषता-सदिशस्य प्रत्येकं घटकं सामान्यीकृतं कर्तव्यम् अन्यथा लघु-मूल्यानां विशेषता-घटकानाम् स्थाने बृहत्-युक्तैः विशेषताभिः स्थाप्यते मूल्यानि लक्षणीयघटकाः डुबन्ति।
अन्येषु दूरगणनाविधिषु महालनोबिसदूरता, भट्टाचार्यदूरता इत्यादयः सन्ति ।
प्रारम्भिक ज्ञान : १.
प्रयोगशाला वातावरणम् : १.
वाइन-दत्तांशसमूहः प्रतिमान-परिचयार्थं प्रसिद्धेषु आँकडा-समूहेषु अन्यतमः अस्ति Wine-दत्तांशसमूहस्य आधिकारिकजालस्थलम् :वाइन डाटा सेट् . इटलीदेशस्य एकस्यैव प्रदेशस्य परन्तु त्रयाणां भिन्नप्रकारस्य मद्यस्य रासायनिकविश्लेषणस्य परिणामः अयं दत्तांशः अस्ति । दत्तांशसमूहः त्रयाणां मद्यस्य प्रत्येकस्मिन् निहितानाम् १३ अवयवानां परिमाणानां विश्लेषणं करोति ।एते १३ गुणाः सन्ति
| कुंजी | मूल्यम् | कुंजी | मूल्यम् |
|---|---|---|---|
| दत्तांशसमूहस्य लक्षणम् : १. | बहुचर | उदाहरणानां संख्या : १. | 178 |
| विशेषता लक्षणम् : १. | पूर्णाङ्कः, वास्तविकः | विशेषतानां संख्या : १. | 13 |
| सम्बद्धानि कार्याणि : १. | वर्गीकरण | मूल्यानि लुप्ताः ? | नहि |
- %%capture captured_output
- # 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
- !pip uninstall mindspore -y
- !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
- # 查看当前 mindspore 版本
- !pip show mindspore
Name: mindspore Version: 2.2.14 Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Home-page: https://www.mindspore.cn Author: The MindSpore Authors Author-email: [email protected] License: Apache 2.0 Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy Required-by:
- from download import download
-
- # 下载红酒数据集
- url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
- path = download(url, "./", kind="zip", replace=True)
Downloading data from https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip (4 kB) file_sizes: 100%|██████████████████████████| 4.09k/4.09k [00:00<00:00, 2.51MB/s] Extracting zip file... Successfully downloaded / unzipped to ./
दत्तांशं जनयितुं पूर्वं आवश्यकानि पायथन् पुस्तकालयाः आयातयन्तु ।
os पुस्तकालयस्य उपयोगः सम्प्रति भवति अवगमनस्य सुविधायै वयं अन्ये आवश्यकाः पुस्तकालयाः यदा विशेषरूपेण उपयुज्यन्ते तदा व्याख्यास्यामः ।
विस्तृतं MindSpore मॉड्यूलविवरणं MindSpore API पृष्ठे अन्वेष्टुं शक्यते ।
भवान् context.set_context इत्यस्य माध्यमेन संचालनाय आवश्यकं सूचनां विन्यस्तुं शक्नोति, यथा संचालनविधिः, पृष्ठभागसूचना, हार्डवेयर इत्यादीनि सूचनाः ।
सन्दर्भमॉड्यूल् आयात्य संचालनाय आवश्यकी सूचना विन्यस्यताम् ।
- %matplotlib inline
- import os
- import csv
- import numpy as np
- import matplotlib.pyplot as plt
-
- import mindspore as ms
- from mindspore import nn, ops
-
- ms.set_context(device_target="CPU")

wine.data, तथा केचन दत्तांशाः पश्यन्तु।- with open('wine.data') as csv_file:
- data = list(csv.reader(csv_file, delimiter=','))
- print(data[56:62]+data[130:133])
[['1', '14.22', '1.7', '2.3', '16.3', '118', '3.2', '3', '.26', '2.03', '6.38', '.94', '3.31', '970'], ['1', '13.29', '1.97', '2.68', '16.8', '102', '3', '3.23', '.31', '1.66', '6', '1.07', '2.84', '1270'], ['1', '13.72', '1.43', '2.5', '16.7', '108', '3.4', '3.67', '.19', '2.04', '6.8', '.89', '2.87', '1285'], ['2', '12.37', '.94', '1.36', '10.6', '88', '1.98', '.57', '.28', '.42', '1.95', '1.05', '1.82', '520'], ['2', '12.33', '1.1', '2.28', '16', '101', '2.05', '1.09', '.63', '.41', '3.27', '1.25', '1.67', '680'], ['2', '12.64', '1.36', '2.02', '16.8', '100', '2.02', '1.41', '.53', '.62', '5.75', '.98', '1.59', '450'], ['3', '12.86', '1.35', '2.32', '18', '122', '1.51', '1.25', '.21', '.94', '4.1', '.76', '1.29', '630'], ['3', '12.88', '2.99', '2.4', '20', '104', '1.3', '1.22', '.24', '.83', '5.4', '.74', '1.42', '530'], ['3', '12.81', '2.31', '2.4', '24', '98', '1.15', '1.09', '.27', '.83', '5.7', '.66', '1.36', '560']]
- X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
- Y = np.array([s[0] for s in data[:178]], np.int32)
- attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
- 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
- 'OD280/OD315 of diluted wines', 'Proline']
- plt.figure(figsize=(10, 8))
- for i in range(0, 4):
- plt.subplot(2, 2, i+1)
- a1, a2 = 2 * i, 2 * i + 1
- plt.scatter(X[:59, a1], X[:59, a2], label='1')
- plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
- plt.scatter(X[130:, a1], X[130:, a2], label='3')
- plt.xlabel(attrs[a1])
- plt.ylabel(attrs[a2])
- plt.legend()
- plt.show()
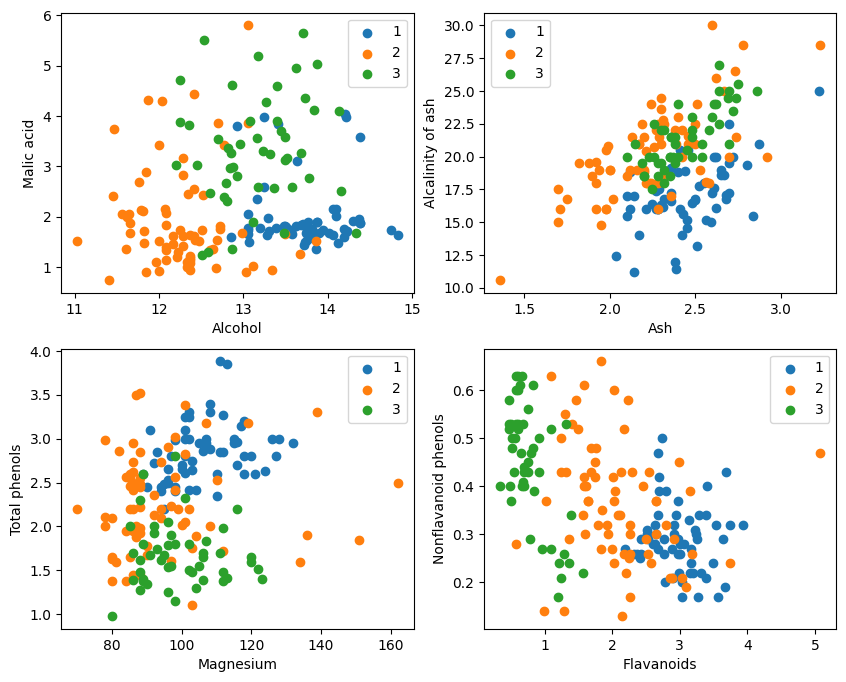
चित्रात्मकप्रदर्शनात्, आलेखस्य उपरि वामकोणे अधः दक्षिणकोणे च द्वौ विशेषतावर्गीकरणप्रभावौ तुल्यकालिकरूपेण उत्तमौ स्तः, विशेषतः १ तथा २ श्रेणीयोः मध्ये सीमाः तुल्यकालिकरूपेण स्पष्टाः सन्ति
- train_idx = np.random.choice(178, 128, replace=False)
- test_idx = np.array(list(set(range(178)) - set(train_idx)))
- X_train, Y_train = X[train_idx], Y[train_idx]
- X_test, Y_test = X[test_idx], Y[test_idx]
分解test_idx = np.array (सूची (सेट (रेंज (178)) - सेट (ट्रेन_idx)))
1. range(178) 0 तः 177 पर्यन्तं पूर्णाङ्कानां क्रमं जनयति ।
2. set(range(178)) इत्यनेन पूर्णाङ्कानां एतत् क्रमं सेट् मध्ये परिवर्तयति । समुच्चयः एकः दत्तांशसंरचना अस्ति यः पुनरावृत्तितत्त्वानां अनुमतिं न ददाति तथा च कुशलसमूहक्रियाणां (यथा संघः, प्रतिच्छेदनं, भेदः इत्यादयः) समर्थयति ।
3. set(train_idx) यादृच्छिकरूपेण चयनितं प्रशिक्षणसमूहसूचकाङ्कसूचीं train_idx एकस्मिन् सेट् मध्ये परिवर्तयति ।
4. set(range(178)) - set(train_idx) setस्य difference set operation गणयति तथा च तान् तत्त्वान् प्राप्नोति ये set(range(178)) मध्ये सन्ति परन्तु set(train_idx) मध्ये न सन्ति, ये the test set. इदं एकं सेट् ऑपरेशनं यत् शीघ्रं कुशलतया च भेदतत्त्वानां गणनां कर्तुं शक्नोति ।
5. list(...) इत्यनेन भेदक्रियायाः परिणामं पुनः सूचीयां परिवर्तयति ।
6. np.array(...) इत्येतत् सूचीं numpy array X तथा Y इत्यनेन सह indexing कृते numpy array इत्यत्र परिवर्तयति。
MindSpore यत् प्रदाति तस्य लाभं गृहाणtile, square, ReduceSum, sqrt, TopKतथा अन्ये संचालकाः, एकत्रितरूपेण इनपुटनमूना x अन्येषां स्पष्टतया वर्गीकृतनमूनानां X_train इत्येतयोः मध्ये दूरीं मैट्रिक्ससञ्चालनानां माध्यमेन गणयन्ति, तथा च शीर्ष k निकटतमपरिजनस्य गणनां कुर्वन्ति
- class KnnNet(nn.Cell):
- def __init__(self, k):
- super(KnnNet, self).__init__()
- self.k = k
-
- def construct(self, x, X_train):
- #平铺输入x以匹配X_train中的样本数
- x_tile = ops.tile(x, (128, 1))
- square_diff = ops.square(x_tile - X_train)
- square_dist = ops.sum(square_diff, 1)
- dist = ops.sqrt(square_dist)
- #-dist表示值越大,样本就越接近
- values, indices = ops.topk(-dist, self.k)
- return indices
-
- def knn(knn_net, x, X_train, Y_train):
- x, X_train = ms.Tensor(x), ms.Tensor(X_train)
- indices = knn_net(x, X_train)
- topk_cls = [0]*len(indices.asnumpy())
- for idx in indices.asnumpy():
- topk_cls[Y_train[idx]] += 1
- cls = np.argmax(topk_cls)
- return cls
1. KNN संजालवर्गं परिभाषयन्तु: KnnNet
__init__ function: संजालस्य आरम्भं कृत्वा K मूल्यं (अर्थात् चयनितस्य समीपस्थपरिजनस्य संख्या) सेट् कुर्वन्तु ।
construct function: प्रशिक्षणसमूहे X_train इत्यस्मिन् इनपुट् नमूना x इत्यस्य प्रत्येकस्य नमूनायाः च मध्ये यूक्लिडियन-अन्तरस्य गणनां कुर्वन्तु, तथा च k (अर्थात् निकटतम-परिजनस्य) नमूनानां सूचकाङ्कं लघुतम-दूरेण सह प्रत्यागच्छन्तु
2. KNN फंक्शन् परिभाषयन्तु: knn
knn_net (KNN संजालदृष्टान्त), परीक्षणनमूना x, प्रशिक्षणनमूना X_train तथा प्रशिक्षणलेबल Y_train इनपुटरूपेण प्राप्नोति ।
x इत्यस्य k निकटतमपरिजननमूनानि अन्वेष्टुं, एतेषां नमूनानां लेबलानुसारं वर्गीकृत्य, वर्गीकरणपरिणामं (अर्थात्, पूर्वानुमानितवर्गः) प्रत्यागन्तुं knn_net इत्यस्य उपयोगं कुर्वन्तु
在验证集上验证KNN算法的有效性,取𝑘=5,验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
- acc = 0
- knn_net = KnnNet(5)
- for x, y in zip(X_test, Y_test):
- pred = knn(knn_net, x, X_train, Y_train)
- acc += (pred == y)
- print('label: %d, prediction: %s' % (y, pred))
- print('Validation accuracy is %f' % (acc/len(Y_test)))
परीक्षणसमूहस्य सटीकता गणनां कृत्वा मुद्रयन्तु
परीक्षणसमूहे X_test तथा Y_test इत्यस्मिन् प्रत्येकं नमूनायाः माध्यमेन लूप् कुर्वन्तु, तथा च प्रत्येकं नमूनानां वर्गीकरणार्थं knn फंक्शन् इत्यस्य उपयोगं कुर्वन्तु ।
सांख्यिकी समीचीननमूनानां संख्यायाः पूर्वानुमानं करोति, वर्गीकरणस्य सटीकतायां गणनां करोति, निर्गच्छति च ।
label: 1, prediction: 1 label: 2, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 2 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 Validation accuracy is 0.660000
प्रतिवारं ८०% प्राप्तुं न शक्यते बहुवारं प्रयत्नस्य अनन्तरं सटीकता अन्ततः ८०% यावत् अभवत् ।
label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 3 label: 3, prediction: 3 label: 1, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 Validation accuracy is 0.820000
अस्मिन् प्रयोगे 3-वर्गीकरणसमस्यायाः समाधानार्थं KNN एल्गोरिदम् कार्यान्वितुं MindSpore इत्यस्य उपयोगः भवति । मद्यदत्तांशसमूहे ३ प्रकारस्य नमूनानि गृहीत्वा सत्यापनीयानां ज्ञातवर्गनमूनानां नमूनानां च विभाजनं कुर्वन्तु सत्यापनपरिणामात् वयं द्रष्टुं शक्नुमः यत् केएनएन एल्गोरिदम् अस्मिन् कार्ये प्रभावी अस्ति तथा च आधारेण मद्यस्य विविधतां निर्धारयितुं शक्नोति १३ मद्यस्य गुणाः ।
आँकडा-निर्माणम् : Wine dataset official website अथवा Huawei Cloud OBS तः data डाउनलोड् कृत्वा पठित्वा तत् संसाधयन्तु।
आँकडासंसाधनम् : दत्तांशसमूहं स्वतन्त्रचरयोः (१३ विशेषताः) आश्रितचरयोः (३ श्रेणयः) च विभज्य, नमूनावितरणस्य अवलोकनार्थं तान् दृश्यमानं कुर्वन्तु
मॉडल निर्माणम् : KNN संजालसंरचना परिभाषयन्तु, MindSpore द्वारा प्रदत्तस्य ऑपरेटरस्य उपयोगं कृत्वा इनपुट् नमूनायाः प्रशिक्षणनमूनायाश्च मध्ये दूरी गणनां कुर्वन्तु, तथा च समीपस्थं k प्रतिवेशिनः अन्वेष्टुम्।
आदर्श भविष्यवाणी : सत्यापनसमूहे भविष्यवाणीं कुर्वन्तु भविष्यवाणीसटीकतायाः गणनां कुर्वन्तु।
प्रयोगात्मकपरिणामेषु ज्ञायते यत् Wine आँकडासमूहे KNN एल्गोरिदमस्य वर्गीकरणसटीकता ८०% (६६%) समीपे अस्ति ।

सः ३० वर्षाणाम् अनुसरणं प्रौयोगिक क्रमबद्धता युक्तं, आलंकार, जावा, जावास्विस्च, ph, css, सद्भावना संस्कृती, ph, css निर्वहनशील भाषा सुनावंश, ससरोत विद्वान विपक्षी विद्वान विनियोग विनियोग विनियोग विनियोग्य विवेचन विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग

