
моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

Этот эксперимент в основном знакомит с использованием MindSpore для проведения экспериментов KNN с некоторыми наборами данных о вине.
K-Nearest-Neighbor (KNN) — это непараметрический статистический метод классификации и регрессии, первоначально предложенный Ковером и Хартом в 1968 году (Ковер и др., 1967 г. ), является одним из самых основных алгоритмов машинного обучения. В его основе лежит изложенная выше идея: для определения категории выборки можно вычислить расстояние между ней и всеми обучающими выборками, затем найти k ближайших к выборке k выборок, посчитать категории этих выборок и проголосовать за ту, у которой наибольшее количество голосов. Этот класс является результатом классификации. Три основных элемента KNN:
При значении K классификация выборки определяется «большинством голосов» K соседей. Чем меньше значение K, тем легче подвергаться воздействию шума. Наоборот, границы между категориями станут размытыми.
Мера расстояния отражает сходство между двумя выборками в пространстве признаков. Чем меньше расстояние, тем более они похожи. Обычно используемые из них включают расстояние Lp (при p=2 это евклидово расстояние), расстояние Манхэттена, расстояние Хэмминга и т. д.
Правила принятия решений о классификации, обычно большинством голосов или большинством голосов на основе взвешивания по расстоянию (веса обратно пропорциональны расстоянию).
Непараметрические статистические методы относятся к статистическим методам, которые не полагаются на параметрические формы (например, предположение о нормальном распределении в традиционной статистике и т. д.), то есть они не делают строгих предположений о распределении данных. По сравнению с параметрическими статистическими методами (такими как линейная регрессия, t-критерий и т. д.), непараметрические статистические методы более гибки, поскольку они не предполагают, что данные следуют определенной схеме распределения.
Параметрические статистические методы основаны на конкретных предположениях и требованиях к распределению данных и используют определенные параметры для описания формы распределения данных. Эти параметрические формы могут значительно упростить модели и анализ, но они также требуют, чтобы эти предположения и параметры соответствовали фактическим данным, что может привести к ошибочным выводам, когда предположения не выполняются.
1. Линейная регрессия:
Предположение: существует линейная связь между зависимой переменной (переменной отклика) и независимой переменной (объясняющей переменной).
Параметры: коэффициенты регрессии (наклон и точка пересечения), обычно предполагающие, что термин ошибки имеет нулевое среднее, постоянную дисперсию (гомоскедастичность) и нормальное распределение.
2. Логистическая регрессия:
Предположение: зависимая переменная (категорическая переменная) удовлетворяет модели логистической регрессии, а коэффициент регрессии имеет фиксированное значение.
Параметр: коэффициент регрессии, используемый для описания влияния независимых переменных на зависимые переменные, оцениваемые посредством оценки максимального правдоподобия.
3. t-тест:
Предположение: данные выборки взяты из нормально распределенной совокупности.
Параметры: среднее значение и дисперсия, t-критерий для одной выборки предполагает среднее значение генеральной совокупности, t-критерий для двух выборок предполагает разницу между средними значениями двух совокупностей.
Алгоритм прогнозирования (классификации) выглядит следующим образом:
(1) Найдите k выборок, ближайших к тестовой выборке x_test в наборе обучающих выборок, и сохраните их в наборе N;
(2)统计集合N中每一类样本的个数𝐶𝑖,𝑖=1,2,3,...,𝑐;
(3)最终的分类结果为argmax𝐶𝑖 (最大的对应的𝐶𝑖)那个类。
В описанном выше процессе реализации значение k особенно важно. Его можно определить на основе характеристик проблемы и данных. В конкретной реализации можно учитывать вес выборки, то есть каждая выборка имеет разный вес голосования. Этот метод называется взвешенным алгоритмом k-ближайшего соседа, который является вариантом алгоритма k-ближайшего соседа.
假设离测试样本最近的k个训练样本的标签值为𝑦𝑖,则对样本的回归预测输出值为:

Это среднее значение метки всех соседей.
Функция прогнозирования регрессии с весами выборки:

其中𝑤𝑖为第个𝑖样本的权重。
KNN算法的实现依赖于样本之间的距离,其中最常用的距离函数就是欧氏距离(欧几里得距离)。ℝ𝑛空间中的两点𝑥和𝑦,它们之间的欧氏距离定义为:
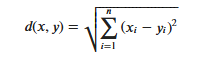
Важно отметить, что при использовании евклидова расстояния каждый компонент вектора признаков должен быть нормализован, чтобы уменьшить помехи, вызванные разными диапазонами масштабов значений признаков. В противном случае компоненты признаков с небольшими значениями будут заменены признаками с. большие значения характеристических компонентов скрыты.
Другие методы расчета расстояний включают расстояние Махаланобиса, расстояние Бхаттачарьи и т. Д.
Предварительные знания:
лабораторная среда:
Набор данных Wine — один из самых известных наборов данных для распознавания образов. Официальный сайт набора данных Wine:Набор данных о вине . Данные являются результатом химического анализа вин из одного и того же региона Италии, но из трех разных сортов. Набор данных анализирует количество 13 ингредиентов, содержащихся в каждом из трех вин.Эти 13 атрибутов
| Ключ | Ценить | Ключ | Ценить |
|---|---|---|---|
| Характеристики набора данных: | Многомерный | Количество экземпляров: | 178 |
| Характеристики атрибута: | Целое число, Действительное число | Количество атрибутов: | 13 |
| Сопутствующие задачи: | Классификация | Отсутствуют значения? | Нет |
- %%capture captured_output
- # 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
- !pip uninstall mindspore -y
- !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
- # 查看当前 mindspore 版本
- !pip show mindspore
Name: mindspore Version: 2.2.14 Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Home-page: https://www.mindspore.cn Author: The MindSpore Authors Author-email: [email protected] License: Apache 2.0 Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy Required-by:
- from download import download
-
- # 下载红酒数据集
- url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
- path = download(url, "./", kind="zip", replace=True)
Downloading data from https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip (4 kB) file_sizes: 100%|██████████████████████████| 4.09k/4.09k [00:00<00:00, 2.51MB/s] Extracting zip file... Successfully downloaded / unzipped to ./
Прежде чем генерировать данные, импортируйте необходимые библиотеки Python.
В настоящее время используется библиотека os. Для облегчения понимания мы объясним другие необходимые библиотеки, когда они используются конкретно.
Подробные описания модулей MindSpore можно найти на странице MindSpore API.
Вы можете настроить информацию, необходимую для работы, через context.set_context, такую как режим работы, серверная информация, оборудование и другая информация.
Импортируйте контекстный модуль и настройте необходимую для работы информацию.
- %matplotlib inline
- import os
- import csv
- import numpy as np
- import matplotlib.pyplot as plt
-
- import mindspore as ms
- from mindspore import nn, ops
-
- ms.set_context(device_target="CPU")

wine.dataи просмотрите некоторые данные.- with open('wine.data') as csv_file:
- data = list(csv.reader(csv_file, delimiter=','))
- print(data[56:62]+data[130:133])
[['1', '14.22', '1.7', '2.3', '16.3', '118', '3.2', '3', '.26', '2.03', '6.38', '.94', '3.31', '970'], ['1', '13.29', '1.97', '2.68', '16.8', '102', '3', '3.23', '.31', '1.66', '6', '1.07', '2.84', '1270'], ['1', '13.72', '1.43', '2.5', '16.7', '108', '3.4', '3.67', '.19', '2.04', '6.8', '.89', '2.87', '1285'], ['2', '12.37', '.94', '1.36', '10.6', '88', '1.98', '.57', '.28', '.42', '1.95', '1.05', '1.82', '520'], ['2', '12.33', '1.1', '2.28', '16', '101', '2.05', '1.09', '.63', '.41', '3.27', '1.25', '1.67', '680'], ['2', '12.64', '1.36', '2.02', '16.8', '100', '2.02', '1.41', '.53', '.62', '5.75', '.98', '1.59', '450'], ['3', '12.86', '1.35', '2.32', '18', '122', '1.51', '1.25', '.21', '.94', '4.1', '.76', '1.29', '630'], ['3', '12.88', '2.99', '2.4', '20', '104', '1.3', '1.22', '.24', '.83', '5.4', '.74', '1.42', '530'], ['3', '12.81', '2.31', '2.4', '24', '98', '1.15', '1.09', '.27', '.83', '5.7', '.66', '1.36', '560']]
- X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
- Y = np.array([s[0] for s in data[:178]], np.int32)
- attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
- 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
- 'OD280/OD315 of diluted wines', 'Proline']
- plt.figure(figsize=(10, 8))
- for i in range(0, 4):
- plt.subplot(2, 2, i+1)
- a1, a2 = 2 * i, 2 * i + 1
- plt.scatter(X[:59, a1], X[:59, a2], label='1')
- plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
- plt.scatter(X[130:, a1], X[130:, a2], label='3')
- plt.xlabel(attrs[a1])
- plt.ylabel(attrs[a2])
- plt.legend()
- plt.show()
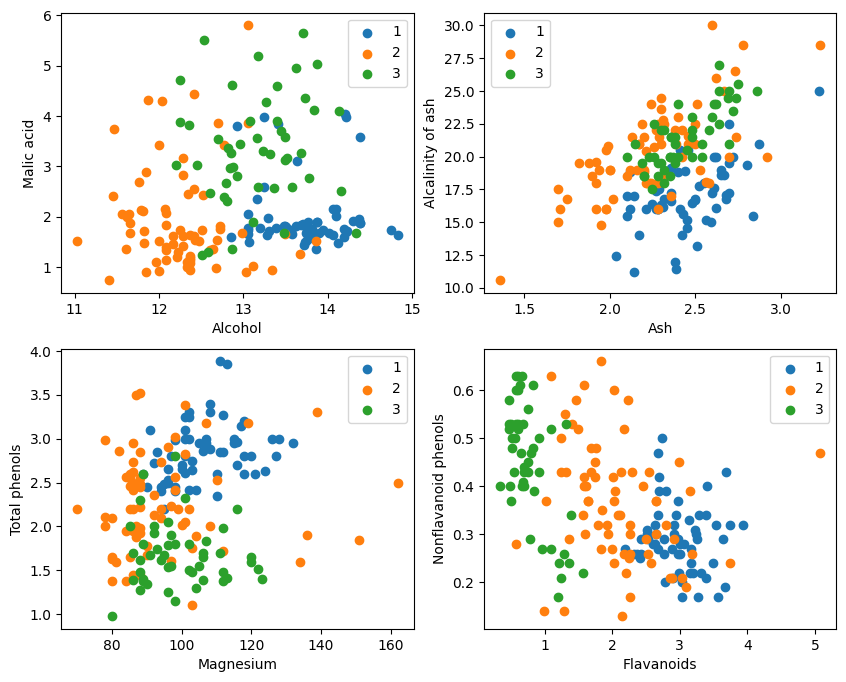
Судя по графическому отображению, два эффекта классификации атрибутов в верхнем левом и нижнем правом углах графика относительно хороши, особенно границы между категориями 1 и 2 относительно очевидны.
- train_idx = np.random.choice(178, 128, replace=False)
- test_idx = np.array(list(set(range(178)) - set(train_idx)))
- X_train, Y_train = X[train_idx], Y[train_idx]
- X_test, Y_test = X[test_idx], Y[test_idx]
Пример test_idx = np.array(list(set(range(178)) - set(train_idx)))
1. range(178) генерирует последовательность целых чисел от 0 до 177.
2. set(range(178)) преобразует эту последовательность целых чисел в набор. Набор — это структура данных, которая не допускает повторяющихся элементов и поддерживает эффективные операции над множествами (такие как объединение, пересечение, разность и т. д.).
3. set(train_idx) преобразует случайно выбранный список индексов обучающего набора train_idx в набор.
4. set(range(178)) - set(train_idx) вычисляет операцию набора разностей набора и получает элементы, которые находятся в наборе(диапазон(178)) но не в наборе(train_idx), которые являются индексами тестовый набор. Это заданная операция, позволяющая быстро и эффективно вычислить разностные элементы.
5. list(...) преобразует результат операции разности обратно в список.
6. np.array(...) преобразует этот список в массив numpy для индексации с помощью массивов numpy X и Y.。
Воспользуйтесь преимуществами, которые предлагает MindSporetile, square, ReduceSum, sqrt, TopKи другие операторы одновременно вычисляют расстояние между входной выборкой x и другими четко классифицированными выборками X_train с помощью матричных операций и вычисляют k верхних ближайших соседей.
- class KnnNet(nn.Cell):
- def __init__(self, k):
- super(KnnNet, self).__init__()
- self.k = k
-
- def construct(self, x, X_train):
- #平铺输入x以匹配X_train中的样本数
- x_tile = ops.tile(x, (128, 1))
- square_diff = ops.square(x_tile - X_train)
- square_dist = ops.sum(square_diff, 1)
- dist = ops.sqrt(square_dist)
- #-dist表示值越大,样本就越接近
- values, indices = ops.topk(-dist, self.k)
- return indices
-
- def knn(knn_net, x, X_train, Y_train):
- x, X_train = ms.Tensor(x), ms.Tensor(X_train)
- indices = knn_net(x, X_train)
- topk_cls = [0]*len(indices.asnumpy())
- for idx in indices.asnumpy():
- topk_cls[Y_train[idx]] += 1
- cls = np.argmax(topk_cls)
- return cls
1. Определите класс сети KNN: KnnNet.
Функция __init__: инициализируйте сеть и установите значение K (то есть количество выбранных ближайших соседей).
Функция построения: вычисляет евклидово расстояние между входной выборкой x и каждой выборкой в обучающем наборе X_train и возвращает индекс k выборок (то есть ближайших соседей) с наименьшим расстоянием.
2. Определите функцию KNN: knn
Получает в качестве входных данных knn_net (экземпляр сети KNN), тестовую выборку x, обучающую выборку X_train и обучающую метку Y_train.
Используйте knn_net, чтобы найти k образцов ближайших соседей x, классифицировать их в соответствии с метками этих образцов и вернуть результат классификации (т. е. предсказанную категорию).
在验证集上验证KNN算法的有效性,取𝑘=5,验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
- acc = 0
- knn_net = KnnNet(5)
- for x, y in zip(X_test, Y_test):
- pred = knn(knn_net, x, X_train, Y_train)
- acc += (pred == y)
- print('label: %d, prediction: %s' % (y, pred))
- print('Validation accuracy is %f' % (acc/len(Y_test)))
Рассчитайте и распечатайте точность тестового набора
Прокрутите каждый образец в тестовом наборе X_test и Y_test и используйте функцию knn для классификации каждого образца.
Статистика прогнозирует количество правильных выборок, рассчитывает и выводит точность классификации.
label: 1, prediction: 1 label: 2, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 2 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 Validation accuracy is 0.660000
Невозможно добиться 80% каждый раз. После многократных попыток точность наконец достигла 80%.
label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 3 label: 3, prediction: 3 label: 1, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 Validation accuracy is 0.820000
В этом эксперименте MindSpore используется для реализации алгоритма KNN для решения проблемы 3-классификации. Возьмите 3 типа образцов из набора данных о вине и разделите их на образцы известных категорий и образцы, подлежащие проверке. Из результатов проверки мы видим, что алгоритм KNN эффективен в этой задаче и может определять сорт вина на основе. 13 атрибутов вина.
Подготовка данных: Загрузите данные с официального сайта набора данных Wine или Huawei Cloud OBS, прочитайте и обработайте их.
Обработка данных: разделите набор данных на независимые переменные (13 атрибутов) и зависимые переменные (3 категории) и визуализируйте их, чтобы наблюдать распределение выборки.
Построение модели: определите структуру сети KNN, используйте оператор, предоставленный MindSpore, для расчета расстояния между входной выборкой и обучающей выборкой и найдите ближайших k соседей.
Прогноз модели: делайте прогнозы на проверочном наборе и рассчитывайте точность прогноза.
Результаты экспериментов показывают, что точность классификации алгоритма KNN на наборе данных Wine близка к 80% (66%).

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования.

Почтамезофия@protonmail.com