2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

Tämä kokeilu esittelee pääasiassa MindSporen käytön KNN-kokeiden suorittamiseen joillakin viinitietosarjoilla.
K-lähin naapuri (KNN) on ei-parametrinen tilastollinen luokittelu- ja regressiomenetelmä, jonka Cover ja Hart ehdottivat alun perin vuonna 1968 (Cover et ai., 1967 ), on yksi koneoppimisen perusalgoritmeista. Se perustuu yllä olevaan ajatukseen: voit määrittää näytteen luokan laskemalla sen etäisyyden kaikista harjoitusnäytteistä, etsimällä näytettä lähinnä olevat k näytettä, laskemalla näiden näytteiden luokat ja äänestämällä eniten ääniä Tämä luokka on luokituksen tulos. Kolme KNN:n peruselementtiä:
K arvo, näytteen luokittelu määräytyy K naapurien "enemmistöäänestyksellä". Mitä pienempi K-arvo on, sitä helpompi kohina vaikuttaa. Päinvastoin, kategorioiden väliset rajat hämärtyvät.
Etäisyysmitta heijastaa samankaltaisuutta piirreavaruuden kahden näytteen välillä Mitä pienempi etäisyys on, sitä samankaltaisempia ne ovat. Yleisesti käytettyjä ovat Lp-etäisyys (kun p = 2, se on euklidinen etäisyys), Manhattanin etäisyys, Hamming-etäisyys jne.
Luokittelupäätössäännöt, yleensä enemmistöpäätös tai etäisyyspainotukseen perustuva enemmistöpäätös (painot ovat kääntäen verrannollisia etäisyyteen).
Ei-parametrisillä tilastollisilla menetelmillä tarkoitetaan tilastollisia menetelmiä, jotka eivät perustu parametrisiin muotoihin (kuten perinteisen tilaston normaalijakauman oletus jne.), eli ne eivät tee tiukkoja oletuksia tiedon jakautumisesta. Verrattuna parametrisiin tilastollisiin menetelmiin (kuten lineaarinen regressio, t-testi jne.), ei-parametriset tilastolliset menetelmät ovat joustavampia, koska ne eivät oleta tietojen noudattavan tiettyä jakautumamallia.
Parametriset tilastolliset menetelmät perustuvat tiettyjen olettamusten ja vaatimusten tekemiseen tiedon jakautumiselle ja käyttävät tiettyjä parametreja kuvaamaan datan jakautumismuotoa. Nämä parametriset muodot voivat yksinkertaistaa malleja ja analyyseja merkittävästi, mutta ne edellyttävät myös näiden oletusten ja parametrien olevan yhdenmukaisia todellisen tiedon kanssa, mikä voi johtaa harhaanjohtaviin johtopäätöksiin, jos oletukset eivät täyty.
1. Lineaarinen regressio:
Oletus: Riippuvan muuttujan (vastausmuuttuja) ja riippumattoman muuttujan (selittävä muuttuja) välillä on lineaarinen suhde.
Parametrit: Regressiokertoimet (jyrkkyys ja leikkauspiste), yleensä olettaen, että virhetermin keskiarvo on nolla, vakiovarianssi (homoskedastisiteetti) ja normaalijakauma.
2. Logistinen regressio:
Oletus: Riippuva muuttuja (kategorinen muuttuja) täyttää logistisen regressiomallin ja regressiokerroin on kiinteä arvo.
Parametri: Regressiokerroin, jota käytetään kuvaamaan riippumattomien muuttujien vaikutusta riippuviin muuttujiin, arvioituna maksimitodennäköisyyden estimoinnilla.
3. t-testi:
Oletus: Otosdata tulee normaalijakaumasta populaatiosta.
Parametrit: keskiarvo ja varianssi, yhden otoksen t-testi olettaa perusjoukon keskiarvon, kahden otoksen t-testi kahden populaation keskiarvojen eron.
Ennustealgoritmin (luokituksen) prosessi on seuraava:
(1) Etsi k näytettä lähimpänä testinäytettä x_test harjoitusnäytejoukosta ja tallenna ne joukkoon N;
(2)统计集合N中每一类样本的个数𝐶𝑖,𝑖=1,2,3,...,𝑐;
(3)最终的分类结果为argmax𝐶𝑖 (最大的对应的𝐶𝑖)那个类。
Yllä olevassa toteutusprosessissa k:n arvo on erityisen tärkeä. Se voidaan määrittää ongelman ja datan ominaisuuksien perusteella. Tietyssä toteutuksessa voidaan ottaa huomioon otoksen paino, eli jokaisella näytteellä on erilainen äänestyspaino. Tätä menetelmää kutsutaan painotetuksi k-lähimmän naapurin algoritmiksi, joka on muunnelma k-lähimmän naapurin algoritmista.
假设离测试样本最近的k个训练样本的标签值为𝑦𝑖,则对样本的回归预测输出值为:

Se on kaikkien naapureiden keskimääräinen etikettiarvo.
Regression ennustefunktio näytepainoilla on:

其中𝑤𝑖为第个𝑖样本的权重。
KNN算法的实现依赖于样本之间的距离,其中最常用的距离函数就是欧氏距离(欧几里得距离)。ℝ𝑛空间中的两点𝑥和𝑦,它们之间的欧氏距离定义为:
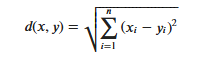
On huomioitava, että euklidista etäisyyttä käytettäessä piirrevektorin jokainen komponentti tulee normalisoida piirrearvojen eri mittakaava-alueiden aiheuttamien häiriöiden vähentämiseksi. Muuten pieniarvoiset piirrekomponentit korvataan suurilla piirteillä arvot ovat upotettuja.
Muita etäisyyden laskentamenetelmiä ovat Mahalanobis-etäisyys, Bhattacharyya-etäisyys jne.
Ennakkotieto:
laboratorioympäristö:
Wine-tietojoukko on yksi tunnetuimmista muodontunnistuksen tietojoukoista. Viini-tietojoukon virallinen verkkosivusto:Viinin tietojoukko . Tiedot ovat tulosta saman Italian alueen viinien kemiallisesta analyysistä, mutta kolmesta eri lajikkeesta. Aineisto analysoi kunkin kolmen viinin sisältämän 13 ainesosan määriä.Nämä 13 ominaisuutta ovat
| Avain | Arvo | Avain | Arvo |
|---|---|---|---|
| Tietojoukon ominaisuudet: | Monimuuttuja | Tapausten määrä: | 178 |
| Ominaisuudet: | Kokonaisluku, todellinen | Attribuuttien määrä: | 13 |
| Liittyvät tehtävät: | Luokittelu | Puuttuvat arvot? | Ei |
- %%capture captured_output
- # 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
- !pip uninstall mindspore -y
- !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
- # 查看当前 mindspore 版本
- !pip show mindspore
Name: mindspore Version: 2.2.14 Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Home-page: https://www.mindspore.cn Author: The MindSpore Authors Author-email: [email protected] License: Apache 2.0 Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy Required-by:
- from download import download
-
- # 下载红酒数据集
- url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
- path = download(url, "./", kind="zip", replace=True)
Downloading data from https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip (4 kB) file_sizes: 100%|██████████████████████████| 4.09k/4.09k [00:00<00:00, 2.51MB/s] Extracting zip file... Successfully downloaded / unzipped to ./
Tuo tarvittavat Python-kirjastot ennen tietojen luomista.
OS-kirjasto on tällä hetkellä käytössä Ymmärtämisen helpottamiseksi, selitämme muut vaaditut kirjastot, kun niitä käytetään.
Yksityiskohtaiset MindSpore-moduulikuvaukset löytyvät MindSporen API-sivulta.
Context.set_context avulla voit määrittää toiminnan edellyttämät tiedot, kuten toimintatilan, taustatiedot, laitteiston ja muut tiedot.
Tuo kontekstimoduuli ja määritä toiminnan edellyttämät tiedot.
- %matplotlib inline
- import os
- import csv
- import numpy as np
- import matplotlib.pyplot as plt
-
- import mindspore as ms
- from mindspore import nn, ops
-
- ms.set_context(device_target="CPU")

wine.dataja tarkastella tietoja.- with open('wine.data') as csv_file:
- data = list(csv.reader(csv_file, delimiter=','))
- print(data[56:62]+data[130:133])
[['1', '14.22', '1.7', '2.3', '16.3', '118', '3.2', '3', '.26', '2.03', '6.38', '.94', '3.31', '970'], ['1', '13.29', '1.97', '2.68', '16.8', '102', '3', '3.23', '.31', '1.66', '6', '1.07', '2.84', '1270'], ['1', '13.72', '1.43', '2.5', '16.7', '108', '3.4', '3.67', '.19', '2.04', '6.8', '.89', '2.87', '1285'], ['2', '12.37', '.94', '1.36', '10.6', '88', '1.98', '.57', '.28', '.42', '1.95', '1.05', '1.82', '520'], ['2', '12.33', '1.1', '2.28', '16', '101', '2.05', '1.09', '.63', '.41', '3.27', '1.25', '1.67', '680'], ['2', '12.64', '1.36', '2.02', '16.8', '100', '2.02', '1.41', '.53', '.62', '5.75', '.98', '1.59', '450'], ['3', '12.86', '1.35', '2.32', '18', '122', '1.51', '1.25', '.21', '.94', '4.1', '.76', '1.29', '630'], ['3', '12.88', '2.99', '2.4', '20', '104', '1.3', '1.22', '.24', '.83', '5.4', '.74', '1.42', '530'], ['3', '12.81', '2.31', '2.4', '24', '98', '1.15', '1.09', '.27', '.83', '5.7', '.66', '1.36', '560']]
- X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
- Y = np.array([s[0] for s in data[:178]], np.int32)
- attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
- 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
- 'OD280/OD315 of diluted wines', 'Proline']
- plt.figure(figsize=(10, 8))
- for i in range(0, 4):
- plt.subplot(2, 2, i+1)
- a1, a2 = 2 * i, 2 * i + 1
- plt.scatter(X[:59, a1], X[:59, a2], label='1')
- plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
- plt.scatter(X[130:, a1], X[130:, a2], label='3')
- plt.xlabel(attrs[a1])
- plt.ylabel(attrs[a2])
- plt.legend()
- plt.show()
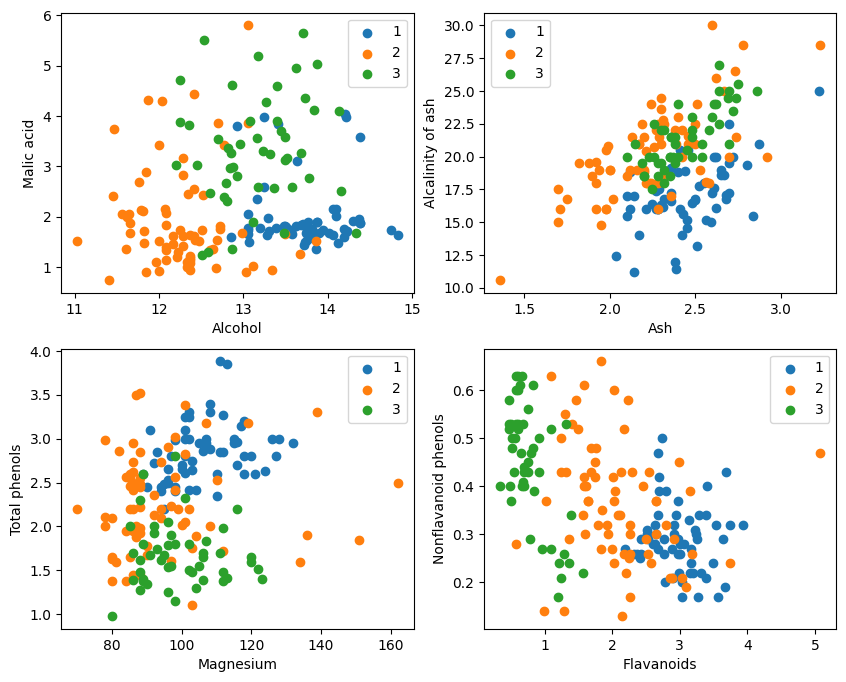
Graafisesta näytöstä kaksi attribuuttiluokitustehostetta kaavion vasemmassa yläkulmassa ja oikeassa alakulmassa ovat suhteellisen hyviä, erityisesti rajat luokkien 1 ja 2 välillä ovat suhteellisen ilmeisiä.
- train_idx = np.random.choice(178, 128, replace=False)
- test_idx = np.array(list(set(range(178)) - set(train_idx)))
- X_train, Y_train = X[train_idx], Y[train_idx]
- X_test, Y_test = X[test_idx], Y[test_idx]
分解test_idx = np.array(list(set(alue(178)) - set(train_idx)))
1. range(178) luo sarjan kokonaislukuja 0-177.
2. set(alue(178)) muuntaa tämän kokonaislukujonon joukoksi. Joukko on tietorakenne, joka ei salli toistuvia elementtejä ja tukee tehokkaita joukkotoimintoja (kuten liitto, leikkaus, ero jne.).
3. set(train_idx) muuntaa satunnaisesti valitun harjoitusjoukon indeksiluettelon train_idx joukoksi.
4. set(alue(178)) - set(train_idx) laskee joukon erojoukon toiminnan ja saa alkiot, jotka ovat joukossa(alue(178)), mutta eivät joukossa(train_idx), jotka ovat joukon indeksejä. testisarja. Tämä on sarjatoiminto, jolla voidaan nopeasti ja tehokkaasti laskea eroelementit.
5. lista(...) muuntaa erotusoperaation tuloksen takaisin listaksi.
6. np.array(...) muuntaa tämän luettelon numpy-taulukoksi indeksointia varten numpy-taulukoilla X ja Y。
Hyödynnä MindSporen tarjontatile, square, ReduceSum, sqrt, TopKja muut operaattorit, laskevat samanaikaisesti syötenäytteen x ja muiden selkeästi luokiteltujen näytteiden X_train välillä matriisioperaatioiden välisen etäisyyden ja laskevat ylimmät k lähintä naapuria
- class KnnNet(nn.Cell):
- def __init__(self, k):
- super(KnnNet, self).__init__()
- self.k = k
-
- def construct(self, x, X_train):
- #平铺输入x以匹配X_train中的样本数
- x_tile = ops.tile(x, (128, 1))
- square_diff = ops.square(x_tile - X_train)
- square_dist = ops.sum(square_diff, 1)
- dist = ops.sqrt(square_dist)
- #-dist表示值越大,样本就越接近
- values, indices = ops.topk(-dist, self.k)
- return indices
-
- def knn(knn_net, x, X_train, Y_train):
- x, X_train = ms.Tensor(x), ms.Tensor(X_train)
- indices = knn_net(x, X_train)
- topk_cls = [0]*len(indices.asnumpy())
- for idx in indices.asnumpy():
- topk_cls[Y_train[idx]] += 1
- cls = np.argmax(topk_cls)
- return cls
1. Määritä KNN-verkkoluokka: KnnNet
__init__-toiminto: Alusta verkko ja aseta K-arvo (eli valittujen lähimpien naapureiden lukumäärä).
konstruktiofunktio: Laske euklidinen etäisyys syötenäytteen x ja jokaisen opetusjoukon X_train näytteen välillä ja palauta k (eli lähimmän naapurin) näytteen indeksi, joilla on pienin etäisyys.
2. Määritä KNN-funktio: knn
Vastaanottaa syötteenä knn_net (KNN-verkkoinstanssi), testinäytteen x, harjoitusnäytteen X_train ja koulutustunnisteen Y_train.
Käytä knn_netiä löytääksesi k lähintä x:n naapurinäytettä, luokittele ne näiden näytteiden nimikkeiden mukaan ja palauta luokittelutulos (eli ennustettu luokka).
在验证集上验证KNN算法的有效性,取𝑘=5,验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
- acc = 0
- knn_net = KnnNet(5)
- for x, y in zip(X_test, Y_test):
- pred = knn(knn_net, x, X_train, Y_train)
- acc += (pred == y)
- print('label: %d, prediction: %s' % (y, pred))
- print('Validation accuracy is %f' % (acc/len(Y_test)))
Laske ja tulosta testisarjan tarkkuus
Käy läpi jokainen näyte testijoukossa X_test ja Y_test ja luokittele jokainen näyte knn-funktiolla.
Tilastot ennustavat oikeiden näytteiden määrän, laskevat ja tulostavat luokituksen tarkkuuden.
label: 1, prediction: 1 label: 2, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 2 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 Validation accuracy is 0.660000
Ei ole mahdollista saavuttaa 80% joka kerta Usean yrittämisen jälkeen tarkkuus saavutti lopulta 80%.
label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 3 label: 3, prediction: 3 label: 1, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 Validation accuracy is 0.820000
Tämä kokeilu käyttää MindSporea KNN-algoritmin toteuttamiseen 3-luokitteluongelman ratkaisemiseksi. Ota viinitietojoukossa olevat 3 näytetyyppiä ja jaa ne tunnettuihin luokkanäytteisiin ja todennettaviin näytteisiin Varmennustuloksista nähdään, että KNN-algoritmi on tehokas tässä tehtävässä ja voi määrittää viinilajikkeen sen perusteella. 13 viinin ominaisuutta.
Tietojen valmistelu: Lataa tiedot Wine-tietojoukon viralliselta verkkosivustolta tai Huawei Cloud OBS:stä, lue ja käsittele ne.
Tiedonkäsittely: Jaa tietojoukko itsenäisiin muuttujiin (13 attribuuttia) ja riippuvaisiin muuttujiin (3 luokkaa) ja visualisoi ne otosjakauman tarkkailemiseksi.
Mallin rakentaminen: Määritä KNN-verkon rakenne, käytä MindSporen tarjoamaa operaattoria laskeaksesi syötenäytteen ja harjoitusnäytteen välisen etäisyyden ja etsi lähin k naapuri.
Mallin ennuste: Tee ennusteita validointijoukosta ja laske ennusteen tarkkuus.
Kokeet osoittavat, että KNN-algoritmin luokittelutarkkuus Wine-tietojoukossa on lähes 80 % (66 %).

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema, jossa voit jakaa joitakin teknologian kehittämisen ongelmia myöhempää käyttöä varten

