2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

Cette expérience introduit principalement l'utilisation de MindSpore pour mener des expériences KNN sur certains ensembles de données sur le vin.
K-Nearest-Neighbour (KNN) est une méthode statistique non paramétrique de classification et de régression, initialement proposée par Cover et Hart en 1968 (Couverture et al., 1967 ), est l’un des algorithmes les plus fondamentaux de l’apprentissage automatique. Il est basé sur l'idée ci-dessus : pour déterminer la catégorie d'un échantillon, vous pouvez calculer la distance entre celui-ci et tous les échantillons d'apprentissage, puis trouver les k échantillons les plus proches de l'échantillon, compter les catégories de ces échantillons et voter, celui avec le plus de votes Cette classe est le résultat d'une classification. Trois éléments de base de KNN :
Valeur K, le classement d'un échantillon est déterminé par le « vote majoritaire » des K voisins. Plus la valeur K est petite, plus il est facile d'être affecté par le bruit. Au contraire, les frontières entre les catégories deviennent floues.
La mesure de distance reflète la similarité entre deux échantillons dans l’espace des caractéristiques. Plus la distance est petite, plus ils sont similaires. Les distances couramment utilisées incluent la distance Lp (lorsque p = 2, il s'agit de la distance euclidienne), la distance de Manhattan, la distance de Hamming, etc.
Règles de décision de classification, généralement un vote majoritaire ou un vote majoritaire basé sur la pondération de la distance (les pondérations sont inversement proportionnelles à la distance).
Les méthodes statistiques non paramétriques font référence à des méthodes statistiques qui ne reposent pas sur des formes paramétriques (telles que l'hypothèse de distribution normale dans les statistiques traditionnelles, etc.), c'est-à-dire qu'elles ne font pas d'hypothèses strictes sur la distribution des données. Par rapport aux méthodes statistiques paramétriques (telles que la régression linéaire, le test t, etc.), les méthodes statistiques non paramétriques sont plus flexibles car elles ne supposent pas que les données suivent un modèle de distribution spécifique.
Les méthodes statistiques paramétriques reposent sur des hypothèses et des exigences spécifiques en matière de distribution des données et utilisent certains paramètres pour décrire la forme de distribution des données. Ces formes paramétriques peuvent simplifier considérablement les modèles et les analyses, mais elles nécessitent également que ces hypothèses et paramètres soient cohérents avec les données réelles, ce qui peut conduire à des conclusions trompeuses lorsque les hypothèses ne sont pas satisfaites.
1. Régression linéaire :
Hypothèse : Il existe une relation linéaire entre la variable dépendante (variable de réponse) et la variable indépendante (variable explicative).
Paramètres : coefficients de régression (pente et ordonnée à l'origine), en supposant généralement que le terme d'erreur a une moyenne nulle, une variance constante (homoscédasticité) et une distribution normale.
2. Régression logistique :
Hypothèse : la variable dépendante (variable catégorielle) satisfait au modèle de régression logistique et le coefficient de régression est une valeur fixe.
Paramètre : Coefficient de régression, utilisé pour décrire l'influence des variables indépendantes sur les variables dépendantes, estimée par estimation du maximum de vraisemblance.
3. test t :
Hypothèse : les données de l'échantillon proviennent d'une population normalement distribuée.
Paramètres : moyenne et variance, le test t sur un échantillon suppose la moyenne de la population, le test t sur deux échantillons suppose la différence entre les moyennes de deux populations.
Le processus d’algorithme de prédiction (classification) est le suivant :
(1) Trouver les k échantillons les plus proches de l'échantillon de test x_test dans l'ensemble d'échantillons d'apprentissage et les enregistrer dans l'ensemble N ;
(2)统计集合N中每一类样本的个数𝐶𝑖,𝑖=1,2,3,...,𝑐;
(3)最终的分类结果为argmax𝐶𝑖 (最大的对应的𝐶𝑖)那个类。
Dans le processus de mise en œuvre ci-dessus, la valeur de k est particulièrement importante. Il peut être déterminé en fonction des caractéristiques du problème et des données. Dans la mise en œuvre spécifique, le poids de l'échantillon peut être pris en compte, c'est-à-dire que chaque échantillon a un poids de vote différent. Cette méthode est appelée algorithme pondéré du k-voisin le plus proche, qui est une variante de l'algorithme du k-voisin le plus proche.
假设离测试样本最近的k个训练样本的标签值为𝑦𝑖,则对样本的回归预测输出值为:

C'est la valeur moyenne de l'étiquette de tous les voisins.
La fonction de prédiction de régression avec des poids d'échantillon est :

其中𝑤𝑖为第个𝑖样本的权重。
KNN算法的实现依赖于样本之间的距离,其中最常用的距离函数就是欧氏距离(欧几里得距离)。ℝ𝑛空间中的两点𝑥和𝑦,它们之间的欧氏距离定义为:
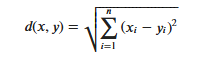
Il est important de noter que lors de l'utilisation de la distance euclidienne, chaque composante du vecteur de caractéristiques doit être normalisée pour réduire les interférences causées par les différentes plages d'échelle des valeurs des caractéristiques. Sinon, les composantes de caractéristiques avec de petites valeurs seront remplacées par des caractéristiques avec. les valeurs élevées. Les composants caractéristiques sont submergés.
D'autres méthodes de calcul de distance incluent la distance de Mahalanobis, la distance de Bhattacharyya, etc.
Connaissances préliminaires :
environnement de laboratoire :
L'ensemble de données Wine est l'un des ensembles de données les plus connus pour la reconnaissance de formes. Le site officiel de l'ensemble de données Wine :Ensemble de données sur le vin . Les données sont le résultat d'une analyse chimique de vins de la même région d'Italie mais de trois cépages différents. L'ensemble de données analyse les quantités de 13 ingrédients contenus dans chacun des trois vins.Ces 13 attributs sont
| Clé | Valeur | Clé | Valeur |
|---|---|---|---|
| Caractéristiques de l'ensemble de données : | Multivarié | Nombre d'instances : | 178 |
| Caractéristiques des attributs : | Entier, Réel | Nombre d'attributs : | 13 |
| Tâches associées : | Classification | Valeurs manquantes ? | Non |
- %%capture captured_output
- # 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
- !pip uninstall mindspore -y
- !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
- # 查看当前 mindspore 版本
- !pip show mindspore
Name: mindspore Version: 2.2.14 Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Home-page: https://www.mindspore.cn Author: The MindSpore Authors Author-email: [email protected] License: Apache 2.0 Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy Required-by:
- from download import download
-
- # 下载红酒数据集
- url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
- path = download(url, "./", kind="zip", replace=True)
Downloading data from https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip (4 kB) file_sizes: 100%|██████████████████████████| 4.09k/4.09k [00:00<00:00, 2.51MB/s] Extracting zip file... Successfully downloaded / unzipped to ./
Avant de générer des données, importez les bibliothèques Python requises.
La bibliothèque os est actuellement utilisée Pour faciliter la compréhension, nous expliquerons les autres bibliothèques requises lorsqu'elles sont spécifiquement utilisées.
Les descriptions détaillées des modules MindSpore peuvent être recherchées sur la page API MindSpore.
Vous pouvez configurer les informations requises pour le fonctionnement via context.set_context, telles que le mode de fonctionnement, les informations backend, le matériel et d'autres informations.
Importez le module contextuel et configurez les informations nécessaires au fonctionnement.
- %matplotlib inline
- import os
- import csv
- import numpy as np
- import matplotlib.pyplot as plt
-
- import mindspore as ms
- from mindspore import nn, ops
-
- ms.set_context(device_target="CPU")

wine.data, et affichez quelques données.- with open('wine.data') as csv_file:
- data = list(csv.reader(csv_file, delimiter=','))
- print(data[56:62]+data[130:133])
[['1', '14.22', '1.7', '2.3', '16.3', '118', '3.2', '3', '.26', '2.03', '6.38', '.94', '3.31', '970'], ['1', '13.29', '1.97', '2.68', '16.8', '102', '3', '3.23', '.31', '1.66', '6', '1.07', '2.84', '1270'], ['1', '13.72', '1.43', '2.5', '16.7', '108', '3.4', '3.67', '.19', '2.04', '6.8', '.89', '2.87', '1285'], ['2', '12.37', '.94', '1.36', '10.6', '88', '1.98', '.57', '.28', '.42', '1.95', '1.05', '1.82', '520'], ['2', '12.33', '1.1', '2.28', '16', '101', '2.05', '1.09', '.63', '.41', '3.27', '1.25', '1.67', '680'], ['2', '12.64', '1.36', '2.02', '16.8', '100', '2.02', '1.41', '.53', '.62', '5.75', '.98', '1.59', '450'], ['3', '12.86', '1.35', '2.32', '18', '122', '1.51', '1.25', '.21', '.94', '4.1', '.76', '1.29', '630'], ['3', '12.88', '2.99', '2.4', '20', '104', '1.3', '1.22', '.24', '.83', '5.4', '.74', '1.42', '530'], ['3', '12.81', '2.31', '2.4', '24', '98', '1.15', '1.09', '.27', '.83', '5.7', '.66', '1.36', '560']]
- X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
- Y = np.array([s[0] for s in data[:178]], np.int32)
- attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
- 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
- 'OD280/OD315 of diluted wines', 'Proline']
- plt.figure(figsize=(10, 8))
- for i in range(0, 4):
- plt.subplot(2, 2, i+1)
- a1, a2 = 2 * i, 2 * i + 1
- plt.scatter(X[:59, a1], X[:59, a2], label='1')
- plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
- plt.scatter(X[130:, a1], X[130:, a2], label='3')
- plt.xlabel(attrs[a1])
- plt.ylabel(attrs[a2])
- plt.legend()
- plt.show()
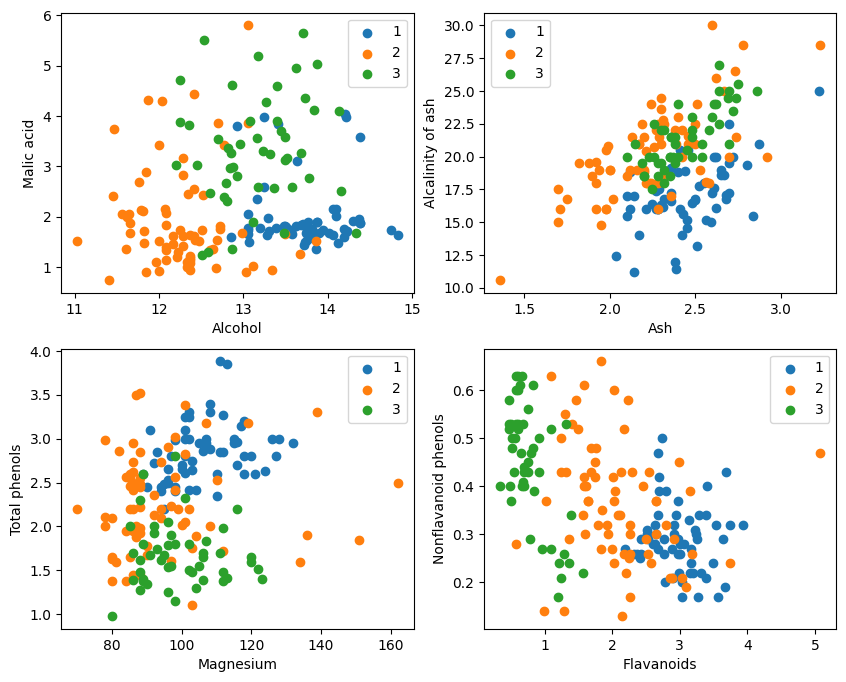
D'après l'affichage graphique, les deux effets de classification des attributs dans le coin supérieur gauche et le coin inférieur droit du graphique sont relativement bons, en particulier les limites entre les catégories 1 et 2 sont relativement évidentes.
- train_idx = np.random.choice(178, 128, replace=False)
- test_idx = np.array(list(set(range(178)) - set(train_idx)))
- X_train, Y_train = X[train_idx], Y[train_idx]
- X_test, Y_test = X[test_idx], Y[test_idx]
Calculertest_idx = np.array(list(set(range(178)) - set(train_idx)))
1. range(178) génère une séquence d'entiers de 0 à 177.
2. set(range(178)) convertit cette séquence d'entiers en un ensemble. Un ensemble est une structure de données qui n'autorise pas la répétition d'éléments et prend en charge des opérations d'ensemble efficaces (telles que l'union, l'intersection, la différence, etc.).
3. set(train_idx) convertit la liste d'index d'ensemble d'entraînement sélectionnée au hasard train_idx en un ensemble.
4. set(range(178)) - set(train_idx) calcule l'opération d'ensemble de différences de l'ensemble et obtient les éléments qui sont dans set(range(178)) mais pas dans set(train_idx), qui sont les index du ensemble d'essai. Il s'agit d'une opération définie qui permet de calculer rapidement et efficacement les éléments de différence.
5. list(...) reconvertit le résultat de l'opération de différence en liste.
6. np.array(...) convertit cette liste en un tableau numpy pour l'indexation avec les tableaux numpy X et Y。
Profitez de ce que propose MindSporetile, square, ReduceSum, sqrt, TopKet d'autres opérateurs, calculent simultanément la distance entre l'échantillon d'entrée x et d'autres échantillons clairement classés X_train via des opérations matricielles, et calculent les k premiers voisins les plus proches
- class KnnNet(nn.Cell):
- def __init__(self, k):
- super(KnnNet, self).__init__()
- self.k = k
-
- def construct(self, x, X_train):
- #平铺输入x以匹配X_train中的样本数
- x_tile = ops.tile(x, (128, 1))
- square_diff = ops.square(x_tile - X_train)
- square_dist = ops.sum(square_diff, 1)
- dist = ops.sqrt(square_dist)
- #-dist表示值越大,样本就越接近
- values, indices = ops.topk(-dist, self.k)
- return indices
-
- def knn(knn_net, x, X_train, Y_train):
- x, X_train = ms.Tensor(x), ms.Tensor(X_train)
- indices = knn_net(x, X_train)
- topk_cls = [0]*len(indices.asnumpy())
- for idx in indices.asnumpy():
- topk_cls[Y_train[idx]] += 1
- cls = np.argmax(topk_cls)
- return cls
1. Définissez la classe de réseau KNN : KnnNet
Fonction __init__ : initialisez le réseau et définissez la valeur K (c'est-à-dire le nombre de voisins les plus proches sélectionnés).
fonction de construction : calculez la distance euclidienne entre l'échantillon d'entrée x et chaque échantillon de l'ensemble d'apprentissage X_train, et renvoyez l'indice des k échantillons (c'est-à-dire le voisin le plus proche) avec la plus petite distance.
2. Définissez la fonction KNN : knn
Reçoit knn_net (instance de réseau KNN), l'échantillon de test x, l'échantillon de formation X_train et l'étiquette de formation Y_train en entrée.
Utilisez knn_net pour trouver les k échantillons voisins les plus proches de x, classez-les en fonction des étiquettes de ces échantillons et renvoyez le résultat de la classification (c'est-à-dire la catégorie prédite).
在验证集上验证KNN算法的有效性,取𝑘=5,验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
- acc = 0
- knn_net = KnnNet(5)
- for x, y in zip(X_test, Y_test):
- pred = knn(knn_net, x, X_train, Y_train)
- acc += (pred == y)
- print('label: %d, prediction: %s' % (y, pred))
- print('Validation accuracy is %f' % (acc/len(Y_test)))
Calculer et imprimer la précision de l'ensemble de test
Parcourez chaque échantillon dans l'ensemble de tests X_test et Y_test et utilisez la fonction knn pour classer chaque échantillon.
Les statistiques prédisent le nombre d'échantillons corrects, calculent et génèrent la précision de la classification.
label: 1, prediction: 1 label: 2, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 2 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 Validation accuracy is 0.660000
Il n'est pas possible d'atteindre 80 % à chaque fois. Après plusieurs essais, la précision a finalement atteint 80 % :
label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 3 label: 3, prediction: 3 label: 1, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 Validation accuracy is 0.820000
Cette expérience utilise MindSpore pour implémenter l'algorithme KNN afin de résoudre le problème de 3 classifications. Prenez les 3 types d'échantillons sur l'ensemble de données sur le vin et divisez-les en échantillons de catégorie connue et en échantillons à vérifier. À partir des résultats de la vérification, nous pouvons voir que l'algorithme KNN est efficace dans cette tâche et peut déterminer la variété de vin sur la base de laquelle. 13 attributs du vin.
Préparation des données : téléchargez les données depuis le site officiel de l'ensemble de données Wine ou Huawei Cloud OBS, lisez-les et traitez-les.
Traitement des données : divisez l'ensemble de données en variables indépendantes (13 attributs) et variables dépendantes (3 catégories) et visualisez-les pour observer la distribution de l'échantillon.
Construction du modèle : définissez la structure du réseau KNN, utilisez l'opérateur fourni par MindSpore pour calculer la distance entre l'échantillon d'entrée et l'échantillon d'apprentissage et trouvez les k voisins les plus proches.
Prédiction du modèle : effectuez des prédictions sur l'ensemble de validation et calculez la précision de la prédiction.
Les résultats expérimentaux montrent que la précision de classification de l'algorithme KNN sur l'ensemble de données Wine est proche de 80 % (66 %).

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.

