
τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

Αυτό το πείραμα εισάγει κυρίως τη χρήση του MindSpore για τη διεξαγωγή πειραμάτων KNN σε ορισμένα σύνολα δεδομένων κρασιού.
Το K-Nearest-Neighbor (KNN) είναι μια μη παραμετρική στατιστική μέθοδος ταξινόμησης και παλινδρόμησης, που προτάθηκε αρχικά από τους Cover και Hart το 1968 (Cover et al., 1967 ), είναι ένας από τους πιο βασικούς αλγόριθμους στη μηχανική μάθηση. Βασίζεται στην παραπάνω ιδέα: για να προσδιορίσετε την κατηγορία ενός δείγματος, μπορείτε να υπολογίσετε την απόστασή του από όλα τα δείγματα εκπαίδευσης, στη συνέχεια να βρείτε τα k δείγματα που βρίσκονται πιο κοντά στο δείγμα, να μετρήσετε τις κατηγορίες αυτών των δειγμάτων και να ψηφίσετε περισσότερες ψήφοι Αυτή η κατηγορία είναι το αποτέλεσμα της ταξινόμησης. Τρία βασικά στοιχεία του KNN:
Τιμή Κ, η ταξινόμηση ενός δείγματος καθορίζεται από την «πλειοψηφική ψήφο» των γειτόνων Κ. Όσο μικρότερη είναι η τιμή K, τόσο πιο εύκολο είναι να επηρεαστείτε από τον θόρυβο. Αντίθετα, τα όρια μεταξύ των κατηγοριών θα γίνουν ασαφή.
Το μέτρο απόστασης αντανακλά την ομοιότητα μεταξύ δύο δειγμάτων στο χώρο χαρακτηριστικών, τόσο πιο όμοια είναι τα δείγματα. Τα κοινά χρησιμοποιούμενα περιλαμβάνουν την απόσταση Lp (όταν p=2, είναι Ευκλείδεια απόσταση), η απόσταση Μανχάταν, η απόσταση Hamming κ.λπ.
Κανόνες απόφασης κατάταξης, συνήθως η πλειοψηφία ή η πλειοψηφία με βάση τη στάθμιση της απόστασης (τα βάρη είναι αντιστρόφως ανάλογα με την απόσταση).
Οι μη παραμετρικές στατιστικές μέθοδοι αναφέρονται σε στατιστικές μεθόδους που δεν βασίζονται σε παραμετρικές μορφές (όπως η υπόθεση κανονικής κατανομής στις παραδοσιακές στατιστικές κ.λπ.), δηλαδή δεν κάνουν αυστηρές υποθέσεις σχετικά με τη διανομή δεδομένων. Σε σύγκριση με τις παραμετρικές στατιστικές μεθόδους (όπως γραμμική παλινδρόμηση, t-test, κ.λπ.), οι μη παραμετρικές στατιστικές μέθοδοι είναι πιο ευέλικτες επειδή δεν υποθέτουν ότι τα δεδομένα ακολουθούν ένα συγκεκριμένο πρότυπο κατανομής.
Οι παραμετρικές στατιστικές μέθοδοι βασίζονται στη δημιουργία συγκεκριμένων υποθέσεων και απαιτήσεων για τη διανομή δεδομένων και χρησιμοποιούν ορισμένες παραμέτρους για να περιγράψουν το σχήμα διανομής των δεδομένων. Αυτές οι παραμετρικές μορφές μπορούν να απλοποιήσουν σημαντικά τα μοντέλα και τις αναλύσεις, αλλά απαιτούν επίσης αυτές οι παραδοχές και οι παράμετροι να είναι συνεπείς με τα πραγματικά δεδομένα, γεγονός που μπορεί να οδηγήσει σε παραπλανητικά συμπεράσματα όταν δεν πληρούνται οι παραδοχές.
1. Γραμμική παλινδρόμηση:
Υπόθεση: Υπάρχει μια γραμμική σχέση μεταξύ της εξαρτημένης μεταβλητής (μεταβλητή απόκρισης) και της ανεξάρτητης μεταβλητής (επεξηγηματική μεταβλητή).
Παράμετροι: Συντελεστές παλινδρόμησης (κλίση και τομή), συνήθως υποθέτοντας ότι ο όρος σφάλματος έχει μηδενικό μέσο όρο, σταθερή διακύμανση (ομοσκεδαστικότητα) και κανονική κατανομή.
2. Logistic Regression:
Υπόθεση: Η εξαρτημένη μεταβλητή (κατηγορική μεταβλητή) ικανοποιεί το μοντέλο λογιστικής παλινδρόμησης και ο συντελεστής παλινδρόμησης είναι μια σταθερή τιμή.
Παράμετρος: Συντελεστής παλινδρόμησης, που χρησιμοποιείται για να περιγράψει την επίδραση ανεξάρτητων μεταβλητών σε εξαρτημένες μεταβλητές, που εκτιμάται μέσω της εκτίμησης μέγιστης πιθανότητας.
3. t-test:
Υπόθεση: Τα δεδομένα του δείγματος προέρχονται από έναν κανονικά κατανεμημένο πληθυσμό.
Παράμετροι: μέσος όρος και διακύμανση, το τεστ t ενός δείγματος υποθέτει τη μέση τιμή πληθυσμού, το τεστ t δύο δειγμάτων υποθέτει τη διαφορά μεταξύ των μέσων τιμών δύο πληθυσμών.
Η διαδικασία του αλγορίθμου πρόβλεψης (ταξινόμηση) έχει ως εξής:
(1) Βρείτε τα k δείγματα που βρίσκονται πιο κοντά στο δείγμα δοκιμής x_test στο σύνολο δειγμάτων εκπαίδευσης και αποθηκεύστε τα στο σύνολο N.
(2)统计集合N中每一类样本的个数𝐶𝑖,𝑖=1,2,3,...,𝑐;
(3)最终的分类结果为argmax𝐶𝑖 (最大的对应的𝐶𝑖)那个类。
Στην παραπάνω διαδικασία υλοποίησης, η τιμή του k είναι ιδιαίτερα σημαντική. Μπορεί να προσδιοριστεί με βάση τα χαρακτηριστικά του προβλήματος και των δεδομένων. Στη συγκεκριμένη υλοποίηση, το βάρος του δείγματος μπορεί να ληφθεί υπόψη, δηλαδή, κάθε δείγμα έχει διαφορετικό βάρος ψήφου Αυτή η μέθοδος ονομάζεται αλγόριθμος σταθμισμένου k-πλησιέστερου γείτονα, ο οποίος είναι μια παραλλαγή του αλγόριθμου k-πλησιέστερου γείτονα.
假设离测试样本最近的k个训练样本的标签值为𝑦𝑖,则对样本的回归预测输出值为:

Αυτή είναι η μέση τιμή ετικέτας όλων των γειτόνων.
Η συνάρτηση πρόβλεψης παλινδρόμησης με βάρη δειγμάτων είναι:

其中𝑤𝑖为第个𝑖样本的权重。
KNN算法的实现依赖于样本之间的距离,其中最常用的距离函数就是欧氏距离(欧几里得距离)。ℝ𝑛空间中的两点𝑥和𝑦,它们之间的欧氏距离定义为:
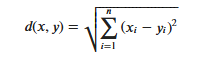
Θα πρέπει να σημειωθεί ότι κατά τη χρήση της Ευκλείδειας απόστασης, κάθε στοιχείο του διανύσματος χαρακτηριστικών θα πρέπει να κανονικοποιηθεί για να μειωθούν οι παρεμβολές που προκαλούνται από τα διαφορετικά εύρη κλίμακας των τιμών των χαρακτηριστικών Τα χαρακτηριστικά στοιχεία είναι βυθισμένα.
Άλλες μέθοδοι υπολογισμού απόστασης περιλαμβάνουν την απόσταση Mahalanobis, την απόσταση Bhattacharyya κ.λπ.
Προκαταρκτικές γνώσεις:
εργαστηριακό περιβάλλον:
Το σύνολο δεδομένων Wine είναι ένα από τα πιο διάσημα σύνολα δεδομένων για την αναγνώριση προτύπων Ο επίσημος ιστότοπος του συνόλου δεδομένων Wine:Σύνολο δεδομένων κρασιού . Τα δεδομένα είναι αποτέλεσμα χημικής ανάλυσης κρασιών από την ίδια περιοχή της Ιταλίας αλλά από τρεις διαφορετικές ποικιλίες. Το σύνολο δεδομένων αναλύει τις ποσότητες 13 συστατικών που περιέχονται σε καθένα από τα τρία κρασιά.Αυτά τα 13 χαρακτηριστικά είναι
| Κλειδί | αξία | Κλειδί | αξία |
|---|---|---|---|
| Χαρακτηριστικά συνόλου δεδομένων: | Πολυμεταβλητή | Αριθμός περιπτώσεων: | 178 |
| Χαρακτηριστικά Ιδιότητας: | Ακέραιος, Πραγματικός | Αριθμός Ιδιοτήτων: | 13 |
| Συναφείς εργασίες: | Ταξινόμηση | Λείπουν Αξίες; | Οχι |
- %%capture captured_output
- # 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
- !pip uninstall mindspore -y
- !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
- # 查看当前 mindspore 版本
- !pip show mindspore
Name: mindspore Version: 2.2.14 Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Home-page: https://www.mindspore.cn Author: The MindSpore Authors Author-email: [email protected] License: Apache 2.0 Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy Required-by:
- from download import download
-
- # 下载红酒数据集
- url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
- path = download(url, "./", kind="zip", replace=True)
Downloading data from https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip (4 kB) file_sizes: 100%|██████████████████████████| 4.09k/4.09k [00:00<00:00, 2.51MB/s] Extracting zip file... Successfully downloaded / unzipped to ./
Πριν δημιουργήσετε δεδομένα, εισαγάγετε τις απαιτούμενες βιβλιοθήκες Python.
Η βιβλιοθήκη os χρησιμοποιείται αυτήν τη στιγμή Για να διευκολυνθεί η κατανόηση, θα εξηγήσουμε άλλες απαιτούμενες βιβλιοθήκες όταν χρησιμοποιούνται ειδικά.
Μπορείτε να αναζητήσετε λεπτομερείς περιγραφές λειτουργικών μονάδων MindSpore στη σελίδα API MindSpore.
Μπορείτε να διαμορφώσετε τις πληροφορίες που απαιτούνται για τη λειτουργία μέσω του context.set_context, όπως ο τρόπος λειτουργίας, οι πληροφορίες υποστήριξης, το υλικό και άλλες πληροφορίες.
Εισαγάγετε τη μονάδα περιβάλλοντος και διαμορφώστε τις πληροφορίες που απαιτούνται για τη λειτουργία.
- %matplotlib inline
- import os
- import csv
- import numpy as np
- import matplotlib.pyplot as plt
-
- import mindspore as ms
- from mindspore import nn, ops
-
- ms.set_context(device_target="CPU")

wine.dataκαι προβάλετε ορισμένα δεδομένα.- with open('wine.data') as csv_file:
- data = list(csv.reader(csv_file, delimiter=','))
- print(data[56:62]+data[130:133])
[['1', '14.22', '1.7', '2.3', '16.3', '118', '3.2', '3', '.26', '2.03', '6.38', '.94', '3.31', '970'], ['1', '13.29', '1.97', '2.68', '16.8', '102', '3', '3.23', '.31', '1.66', '6', '1.07', '2.84', '1270'], ['1', '13.72', '1.43', '2.5', '16.7', '108', '3.4', '3.67', '.19', '2.04', '6.8', '.89', '2.87', '1285'], ['2', '12.37', '.94', '1.36', '10.6', '88', '1.98', '.57', '.28', '.42', '1.95', '1.05', '1.82', '520'], ['2', '12.33', '1.1', '2.28', '16', '101', '2.05', '1.09', '.63', '.41', '3.27', '1.25', '1.67', '680'], ['2', '12.64', '1.36', '2.02', '16.8', '100', '2.02', '1.41', '.53', '.62', '5.75', '.98', '1.59', '450'], ['3', '12.86', '1.35', '2.32', '18', '122', '1.51', '1.25', '.21', '.94', '4.1', '.76', '1.29', '630'], ['3', '12.88', '2.99', '2.4', '20', '104', '1.3', '1.22', '.24', '.83', '5.4', '.74', '1.42', '530'], ['3', '12.81', '2.31', '2.4', '24', '98', '1.15', '1.09', '.27', '.83', '5.7', '.66', '1.36', '560']]
- X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
- Y = np.array([s[0] for s in data[:178]], np.int32)
- attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
- 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
- 'OD280/OD315 of diluted wines', 'Proline']
- plt.figure(figsize=(10, 8))
- for i in range(0, 4):
- plt.subplot(2, 2, i+1)
- a1, a2 = 2 * i, 2 * i + 1
- plt.scatter(X[:59, a1], X[:59, a2], label='1')
- plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
- plt.scatter(X[130:, a1], X[130:, a2], label='3')
- plt.xlabel(attrs[a1])
- plt.ylabel(attrs[a2])
- plt.legend()
- plt.show()
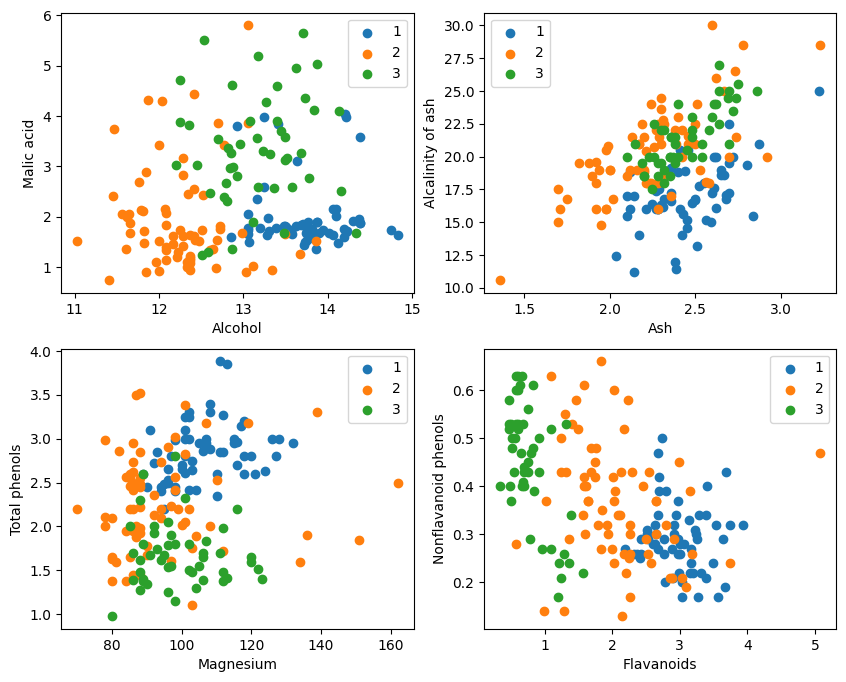
Από τη γραφική απεικόνιση, τα δύο εφέ ταξινόμησης χαρακτηριστικών στην επάνω αριστερή γωνία και στην κάτω δεξιά γωνία του γραφήματος είναι σχετικά καλά, ειδικά τα όρια μεταξύ των κατηγοριών 1 και 2 είναι σχετικά εμφανή.
- train_idx = np.random.choice(178, 128, replace=False)
- test_idx = np.array(list(set(range(178)) - set(train_idx)))
- X_train, Y_train = X[train_idx], Y[train_idx]
- X_test, Y_test = X[test_idx], Y[test_idx]
分解test_idx = np.array(list(set(range(178)) - set(train_idx)))
1. Το range(178) δημιουργεί μια ακολουθία ακεραίων από το 0 έως το 177.
2. Το set(range(178)) μετατρέπει αυτήν την ακολουθία ακεραίων σε σύνολο. Ένα σύνολο είναι μια δομή δεδομένων που δεν επιτρέπει επαναλαμβανόμενα στοιχεία και υποστηρίζει αποτελεσματικές λειτουργίες συνόλου (όπως ένωση, τομή, διαφορά κ.λπ.).
3. set(train_idx) μετατρέπει την τυχαία επιλεγμένη λίστα ευρετηρίου συνόλων εκπαίδευσης train_idx σε σύνολο.
4. set(range(178)) - set(train_idx) υπολογίζει τη λειτουργία συνόλου διαφοράς του συνόλου και λαμβάνει τα στοιχεία που βρίσκονται στο set(range(178)) αλλά όχι στο set(train_idx), τα οποία είναι οι δείκτες του σετ δοκιμής. Αυτή είναι μια λειτουργία συνόλου που μπορεί γρήγορα και αποτελεσματικά να υπολογίσει τα στοιχεία διαφοράς.
5. list(...) μετατρέπει το αποτέλεσμα της λειτουργίας διαφοράς ξανά σε λίστα.
6. np.array(...) μετατρέπει αυτήν τη λίστα σε numpy πίνακα για ευρετηρίαση με numpy πίνακες X και Y。
Επωφεληθείτε από αυτά που προσφέρει το MindSporetile, square, ReduceSum, sqrt, TopKκαι άλλους τελεστές, υπολογίζουν ταυτόχρονα την απόσταση μεταξύ του εισερχόμενου δείγματος x και άλλων σαφώς ταξινομημένων δειγμάτων X_train μέσω λειτουργιών μήτρας και υπολογίζουν τους επάνω k πλησιέστερους γείτονες
- class KnnNet(nn.Cell):
- def __init__(self, k):
- super(KnnNet, self).__init__()
- self.k = k
-
- def construct(self, x, X_train):
- #平铺输入x以匹配X_train中的样本数
- x_tile = ops.tile(x, (128, 1))
- square_diff = ops.square(x_tile - X_train)
- square_dist = ops.sum(square_diff, 1)
- dist = ops.sqrt(square_dist)
- #-dist表示值越大,样本就越接近
- values, indices = ops.topk(-dist, self.k)
- return indices
-
- def knn(knn_net, x, X_train, Y_train):
- x, X_train = ms.Tensor(x), ms.Tensor(X_train)
- indices = knn_net(x, X_train)
- topk_cls = [0]*len(indices.asnumpy())
- for idx in indices.asnumpy():
- topk_cls[Y_train[idx]] += 1
- cls = np.argmax(topk_cls)
- return cls
1. Ορίστε την κλάση δικτύου KNN: KnnNet
Συνάρτηση __init__: Αρχικοποιήστε το δίκτυο και ορίστε την τιμή K (δηλαδή τον αριθμό των πλησιέστερων γειτόνων που έχουν επιλεγεί).
συνάρτηση κατασκευής: Υπολογίστε την Ευκλείδεια απόσταση μεταξύ του εισερχόμενου δείγματος x και κάθε δείγματος στο σύνολο εκπαίδευσης X_train και επιστρέψτε τον δείκτη των δειγμάτων k (δηλαδή του πλησιέστερου γείτονα) με τη μικρότερη απόσταση.
2. Ορίστε τη συνάρτηση KNN: knn
Λαμβάνει knn_net (στιγμιότυπο δικτύου KNN), δείγμα δοκιμής x, δείγμα εκπαίδευσης X_train και εκπαιδευτική ετικέτα Y_train ως είσοδο.
Χρησιμοποιήστε το knn_net για να βρείτε τα k δείγματα του πλησιέστερου γείτονα του x, να τα ταξινομήσετε σύμφωνα με τις ετικέτες αυτών των δειγμάτων και να επιστρέψετε το αποτέλεσμα ταξινόμησης (δηλαδή, την προβλεπόμενη κατηγορία).
在验证集上验证KNN算法的有效性,取𝑘=5,验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
- acc = 0
- knn_net = KnnNet(5)
- for x, y in zip(X_test, Y_test):
- pred = knn(knn_net, x, X_train, Y_train)
- acc += (pred == y)
- print('label: %d, prediction: %s' % (y, pred))
- print('Validation accuracy is %f' % (acc/len(Y_test)))
Υπολογίστε και εκτυπώστε την ακρίβεια του συνόλου δοκιμής
Πραγματοποιήστε βρόχο σε κάθε δείγμα στο σύνολο δοκιμής X_test και Y_test και χρησιμοποιήστε τη συνάρτηση knn για να ταξινομήσετε κάθε δείγμα.
Οι στατιστικές προβλέπουν τον αριθμό των σωστών δειγμάτων, υπολογίζουν και εξάγουν την ακρίβεια της ταξινόμησης.
label: 1, prediction: 1 label: 2, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 2 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 Validation accuracy is 0.660000
Δεν είναι δυνατό να πετύχετε το 80% κάθε φορά Μετά από πολλές φορές προσπάθεια, η ακρίβεια έφτασε τελικά στο 80%.
label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 3 label: 3, prediction: 3 label: 1, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 Validation accuracy is 0.820000
Αυτό το πείραμα χρησιμοποιεί το MindSpore για να εφαρμόσει τον αλγόριθμο KNN για να λύσει το πρόβλημα της 3-ταξινόμησης. Πάρτε τους 3 τύπους δειγμάτων στο σύνολο δεδομένων κρασιού και χωρίστε τα σε δείγματα γνωστών κατηγοριών και δείγματα προς επαλήθευση Από τα αποτελέσματα της επαλήθευσης, μπορούμε να δούμε ότι ο αλγόριθμος KNN είναι αποτελεσματικός σε αυτήν την εργασία και μπορεί να προσδιορίσει την ποικιλία του κρασιού. 13 ιδιότητες του κρασιού.
Προετοιμασία δεδομένων: Πραγματοποιήστε λήψη δεδομένων από τον επίσημο ιστότοπο δεδομένων Wine ή το Huawei Cloud OBS, διαβάστε και επεξεργαστείτε τα.
Επεξεργασία δεδομένων: Διαχωρίστε το σύνολο δεδομένων σε ανεξάρτητες μεταβλητές (13 χαρακτηριστικά) και εξαρτημένες μεταβλητές (3 κατηγορίες) και οπτικοποιήστε τις για να παρατηρήσετε την κατανομή του δείγματος.
Κατασκευή μοντέλου: Ορίστε τη δομή του δικτύου KNN, χρησιμοποιήστε τον τελεστή που παρέχεται από το MindSpore για να υπολογίσετε την απόσταση μεταξύ του δείγματος εισόδου και του δείγματος εκπαίδευσης και βρείτε τους πλησιέστερους k γείτονες.
Πρόβλεψη μοντέλου: Κάντε προβλέψεις για το σύνολο επικύρωσης και υπολογίστε την ακρίβεια της πρόβλεψης.
Τα πειραματικά αποτελέσματα δείχνουν ότι η ακρίβεια ταξινόμησης του αλγόριθμου KNN στο σύνολο δεδομένων Wine είναι κοντά στο 80% (66%).

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα τεκμηρίωσης προγραμματιστή για να μοιραστείτε τα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]