
minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

Este experimento introduz principalmente o uso do MindSpore para conduzir experimentos KNN em alguns conjuntos de dados de vinhos.
K-Nearest-Neighbor (KNN) é um método estatístico não paramétrico para classificação e regressão, originalmente proposto por Cover e Hart em 1968 (Capa et al., 1967 ), é um dos algoritmos mais básicos em aprendizado de máquina. Baseia-se na ideia acima: para determinar a categoria de uma amostra, você pode calcular sua distância de todas as amostras de treinamento, então encontrar as k amostras mais próximas da amostra, contar as categorias dessas amostras e votar aquela com a. maioria dos votos Essa classe é o resultado da classificação. Três elementos básicos do KNN:
Valor K, a classificação de uma amostra é determinada pela “votação majoritária” de K vizinhos. Quanto menor o valor K, mais fácil será ser afetado pelo ruído. Pelo contrário, as fronteiras entre as categorias ficarão confusas.
A medida de distância reflete a semelhança entre duas amostras no espaço de características. Quanto menor a distância, mais semelhantes são as amostras. Os comumente usados incluem distância Lp (quando p = 2, é a distância euclidiana), distância de Manhattan, distância de Hamming, etc.
Regras de decisão de classificação, geralmente votação majoritária ou votação majoritária baseada na ponderação da distância (os pesos são inversamente proporcionais à distância).
Os métodos estatísticos não paramétricos referem-se a métodos estatísticos que não dependem de formas paramétricas (como a suposição de distribuição normal nas estatísticas tradicionais, etc.), ou seja, não fazem suposições estritas sobre a distribuição de dados. Em comparação com métodos estatísticos paramétricos (como regressão linear, teste t, etc.), os métodos estatísticos não paramétricos são mais flexíveis porque não assumem que os dados seguem um padrão de distribuição específico.
Os métodos estatísticos paramétricos baseiam-se em suposições e requisitos específicos para distribuição de dados e usam certos parâmetros para descrever a forma de distribuição dos dados. Estas formas paramétricas podem simplificar significativamente os modelos e as análises, mas também exigem que estes pressupostos e parâmetros sejam consistentes com os dados reais, o que pode levar a conclusões enganosas quando os pressupostos não são cumpridos.
1. Regressão Linear:
Suposição: Existe uma relação linear entre a variável dependente (variável resposta) e a variável independente (variável explicativa).
Parâmetros: Coeficientes de regressão (inclinação e intercepto), geralmente assumindo que o termo de erro tem média zero, variância constante (homoscedasticidade) e distribuição normal.
2. Regressão Logística:
Suposição: A variável dependente (variável categórica) satisfaz o modelo de regressão logística e o coeficiente de regressão é um valor fixo.
Parâmetro: Coeficiente de regressão, utilizado para descrever a influência das variáveis independentes sobre as variáveis dependentes, estimado através da estimação de máxima verossimilhança.
3. teste t:
Suposição: Os dados da amostra vêm de uma população normalmente distribuída.
Parâmetros: média e variância, o teste t de uma amostra assume a média da população, o teste t de duas amostras assume a diferença entre as médias de duas populações.
O processo de algoritmo de previsão (classificação) é o seguinte:
(1) Encontre as k amostras mais próximas da amostra de teste x_test no conjunto de amostras de treinamento e salve-as no conjunto N;
(2)统计集合N中每一类样本的个数𝐶𝑖,𝑖=1,2,3,...,𝑐;
(3)最终的分类结果为argmax𝐶𝑖 (最大的对应的𝐶𝑖)那个类。
No processo de implementação acima, o valor de k é particularmente importante. Pode ser determinado com base nas características do problema e dos dados. Na implementação específica, o peso da amostra pode ser considerado, ou seja, cada amostra possui um peso de votação diferente. Este método é denominado algoritmo de k-vizinho mais próximo ponderado, que é uma variante do algoritmo de k-vizinho mais próximo.
假设离测试样本最近的k个训练样本的标签值为𝑦𝑖,则对样本的回归预测输出值为:

Esse é o valor médio do rótulo de todos os vizinhos.
A função de previsão de regressão com pesos amostrais é:

其中𝑤𝑖为第个𝑖样本的权重。
KNN算法的实现依赖于样本之间的距离,其中最常用的距离函数就是欧氏距离(欧几里得距离)。ℝ𝑛空间中的两点𝑥和𝑦,它们之间的欧氏距离定义为:
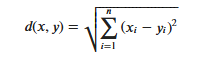
Deve-se notar que ao usar a distância euclidiana, cada componente do vetor de recursos deve ser normalizado para reduzir a interferência causada pelas diferentes faixas de escala dos valores dos recursos. Caso contrário, os componentes dos recursos com valores pequenos serão substituídos por recursos com grandes valores. Os valores característicos estão submersos.
Outros métodos de cálculo de distância incluem distância Mahalanobis, distância Bhattacharyya, etc.
Conhecimento preliminar:
ambiente de laboratório:
O conjunto de dados Wine é um dos conjuntos de dados mais famosos para reconhecimento de padrões. O site oficial do conjunto de dados Wine:Conjunto de dados de vinho . Os dados são o resultado de uma análise química de vinhos da mesma região da Itália, mas de três variedades diferentes. O conjunto de dados analisa as quantidades de 13 ingredientes contidos em cada um dos três vinhos.Esses 13 atributos são
| Chave | Valor | Chave | Valor |
|---|---|---|---|
| Características do conjunto de dados: | Multivariado | Número de Instâncias: | 178 |
| Características do Atributo: | Inteiro, Real | Número de atributos: | 13 |
| Tarefas associadas: | Classificação | Valores ausentes? | Não |
- %%capture captured_output
- # 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
- !pip uninstall mindspore -y
- !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
- # 查看当前 mindspore 版本
- !pip show mindspore
Name: mindspore Version: 2.2.14 Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Home-page: https://www.mindspore.cn Author: The MindSpore Authors Author-email: [email protected] License: Apache 2.0 Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy Required-by:
- from download import download
-
- # 下载红酒数据集
- url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
- path = download(url, "./", kind="zip", replace=True)
Downloading data from https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip (4 kB) file_sizes: 100%|██████████████████████████| 4.09k/4.09k [00:00<00:00, 2.51MB/s] Extracting zip file... Successfully downloaded / unzipped to ./
Antes de gerar dados, importe as bibliotecas Python necessárias.
A biblioteca os é usada atualmente. Para facilitar o entendimento, explicaremos outras bibliotecas necessárias quando forem usadas especificamente.
Descrições detalhadas dos módulos MindSpore podem ser pesquisadas na página da API MindSpore.
Você pode configurar as informações necessárias para operação através de context.set_context, como modo de operação, informações de backend, hardware e outras informações.
Importe o módulo de contexto e configure as informações necessárias para operação.
- %matplotlib inline
- import os
- import csv
- import numpy as np
- import matplotlib.pyplot as plt
-
- import mindspore as ms
- from mindspore import nn, ops
-
- ms.set_context(device_target="CPU")

wine.datae visualize alguns dados.- with open('wine.data') as csv_file:
- data = list(csv.reader(csv_file, delimiter=','))
- print(data[56:62]+data[130:133])
[['1', '14.22', '1.7', '2.3', '16.3', '118', '3.2', '3', '.26', '2.03', '6.38', '.94', '3.31', '970'], ['1', '13.29', '1.97', '2.68', '16.8', '102', '3', '3.23', '.31', '1.66', '6', '1.07', '2.84', '1270'], ['1', '13.72', '1.43', '2.5', '16.7', '108', '3.4', '3.67', '.19', '2.04', '6.8', '.89', '2.87', '1285'], ['2', '12.37', '.94', '1.36', '10.6', '88', '1.98', '.57', '.28', '.42', '1.95', '1.05', '1.82', '520'], ['2', '12.33', '1.1', '2.28', '16', '101', '2.05', '1.09', '.63', '.41', '3.27', '1.25', '1.67', '680'], ['2', '12.64', '1.36', '2.02', '16.8', '100', '2.02', '1.41', '.53', '.62', '5.75', '.98', '1.59', '450'], ['3', '12.86', '1.35', '2.32', '18', '122', '1.51', '1.25', '.21', '.94', '4.1', '.76', '1.29', '630'], ['3', '12.88', '2.99', '2.4', '20', '104', '1.3', '1.22', '.24', '.83', '5.4', '.74', '1.42', '530'], ['3', '12.81', '2.31', '2.4', '24', '98', '1.15', '1.09', '.27', '.83', '5.7', '.66', '1.36', '560']]
- X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
- Y = np.array([s[0] for s in data[:178]], np.int32)
- attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
- 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
- 'OD280/OD315 of diluted wines', 'Proline']
- plt.figure(figsize=(10, 8))
- for i in range(0, 4):
- plt.subplot(2, 2, i+1)
- a1, a2 = 2 * i, 2 * i + 1
- plt.scatter(X[:59, a1], X[:59, a2], label='1')
- plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
- plt.scatter(X[130:, a1], X[130:, a2], label='3')
- plt.xlabel(attrs[a1])
- plt.ylabel(attrs[a2])
- plt.legend()
- plt.show()
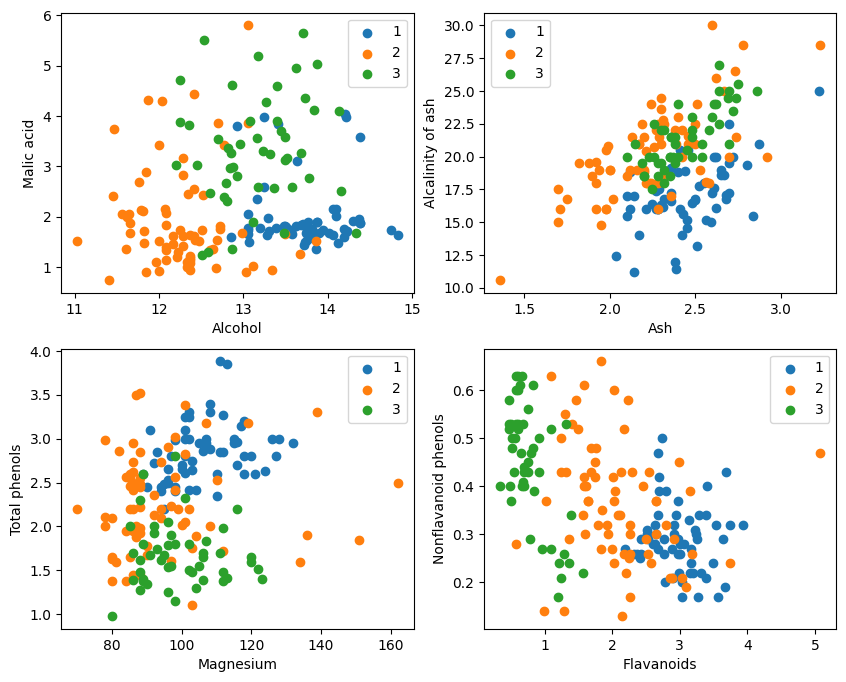
A partir da exibição gráfica, os dois efeitos de classificação de atributos no canto superior esquerdo e no canto inferior direito do gráfico são relativamente bons, especialmente os limites entre as categorias 1 e 2 são relativamente óbvios.
- train_idx = np.random.choice(178, 128, replace=False)
- test_idx = np.array(list(set(range(178)) - set(train_idx)))
- X_train, Y_train = X[train_idx], Y[train_idx]
- X_test, Y_test = X[test_idx], Y[test_idx]
Exemplo test_idx = np.array(list(set(range(178)) - set(train_idx)))
1. range(178) gera uma sequência de números inteiros de 0 a 177.
2. set(range(178)) converte esta sequência de inteiros em um conjunto. Um conjunto é uma estrutura de dados que não permite elementos repetidos e suporta operações eficientes de conjunto (como união, interseção, diferença, etc.).
3. set(train_idx) converte a lista de índices do conjunto de treinamento selecionado aleatoriamente train_idx em um conjunto.
4. set(range(178)) - set(train_idx) calcula a operação de conjunto de diferenças do conjunto e obtém os elementos que estão em set(range(178)) mas não em set(train_idx), que são os índices do Conjunto de teste. Esta é uma operação definida que pode calcular de forma rápida e eficiente os elementos de diferença.
5. list(...) converte o resultado da operação de diferença novamente em uma lista.
6. np.array(...) converte esta lista em um array numpy para indexação com arrays numpy X e Y。
Aproveite o que o MindSpore oferecetile, square, ReduceSum, sqrt, TopKe outros operadores, calculam simultaneamente a distância entre a amostra de entrada x e outras amostras claramente classificadas X_train por meio de operações matriciais e calculam os k vizinhos mais próximos
- class KnnNet(nn.Cell):
- def __init__(self, k):
- super(KnnNet, self).__init__()
- self.k = k
-
- def construct(self, x, X_train):
- #平铺输入x以匹配X_train中的样本数
- x_tile = ops.tile(x, (128, 1))
- square_diff = ops.square(x_tile - X_train)
- square_dist = ops.sum(square_diff, 1)
- dist = ops.sqrt(square_dist)
- #-dist表示值越大,样本就越接近
- values, indices = ops.topk(-dist, self.k)
- return indices
-
- def knn(knn_net, x, X_train, Y_train):
- x, X_train = ms.Tensor(x), ms.Tensor(X_train)
- indices = knn_net(x, X_train)
- topk_cls = [0]*len(indices.asnumpy())
- for idx in indices.asnumpy():
- topk_cls[Y_train[idx]] += 1
- cls = np.argmax(topk_cls)
- return cls
1. Defina a classe de rede KNN: KnnNet
Função __init__: inicializa a rede e define o valor K (ou seja, o número de vizinhos mais próximos selecionados).
função de construção: Calcule a distância euclidiana entre a amostra de entrada x e cada amostra no conjunto de treinamento X_train e retorne o índice das amostras k (ou seja, vizinhas mais próximas) com a menor distância.
2. Defina a função KNN: knn
Recebe knn_net (instância de rede KNN), amostra de teste x, amostra de treinamento X_train e rótulo de treinamento Y_train como entrada.
Use knn_net para encontrar as k amostras vizinhas mais próximas de x, classifique-as de acordo com os rótulos dessas amostras e retorne o resultado da classificação (ou seja, a categoria prevista).
在验证集上验证KNN算法的有效性,取𝑘=5,验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
- acc = 0
- knn_net = KnnNet(5)
- for x, y in zip(X_test, Y_test):
- pred = knn(knn_net, x, X_train, Y_train)
- acc += (pred == y)
- print('label: %d, prediction: %s' % (y, pred))
- print('Validation accuracy is %f' % (acc/len(Y_test)))
Calcule e imprima a precisão do conjunto de teste
Faça um loop em cada amostra no conjunto de testes X_test e Y_test e use a função knn para classificar cada amostra.
As estatísticas prevêem o número de amostras corretas, calculam e geram a precisão da classificação.
label: 1, prediction: 1 label: 2, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 2 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 Validation accuracy is 0.660000
Não é possível atingir 80% todas as vezes. Depois de muitas tentativas, a precisão finalmente atingiu 80%:
label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 3 label: 3, prediction: 3 label: 1, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 Validation accuracy is 0.820000
Este experimento usa MindSpore para implementar o algoritmo KNN para resolver o problema de 3 classificações. Pegue os 3 tipos de amostras no conjunto de dados de vinho e divida-os em amostras de categorias conhecidas e amostras a serem verificadas. A partir dos resultados da verificação, podemos ver que o algoritmo KNN é eficaz nesta tarefa e pode determinar a variedade de vinho com base. 13 atributos do vinho.
Preparação de dados: Baixe os dados do site oficial do conjunto de dados Wine ou Huawei Cloud OBS, leia e processe-os.
Processamento de dados: Divida o conjunto de dados em variáveis independentes (13 atributos) e variáveis dependentes (3 categorias), e visualize-as para observar a distribuição da amostra.
Construção do modelo: Defina a estrutura da rede KNN, use o operador fornecido pela MindSpore para calcular a distância entre a amostra de entrada e a amostra de treinamento e encontre os k vizinhos mais próximos.
Predição do modelo: faça previsões no conjunto de validação e calcule a precisão da previsão.
Os resultados experimentais mostram que a precisão da classificação do algoritmo KNN no conjunto de dados Wine é próxima de 80% (66%).

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]