
Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

Este experimento presenta principalmente el uso de MindSpore para realizar experimentos KNN en algunos conjuntos de datos de vino.
K-Nearest-Neighbor (KNN) es un método estadístico no paramétrico para clasificación y regresión, propuesto originalmente por Cover y Hart en 1968 (Cubierta y otros, 1967 ), es uno de los algoritmos más básicos del aprendizaje automático. Se basa en la idea anterior: para determinar la categoría de una muestra, puede calcular su distancia de todas las muestras de entrenamiento, luego encontrar las k muestras más cercanas a la muestra, contar las categorías de estas muestras y votar la que tiene. más votos Esa clase es el resultado de la clasificación. Tres elementos básicos de KNN:
Valor K, la clasificación de una muestra está determinada por el "voto mayoritario" de K vecinos. Cuanto menor sea el valor de K, más fácil será verse afectado por el ruido. Por el contrario, los límites entre categorías se volverán borrosos.
La medida de distancia refleja la similitud entre dos muestras en el espacio de características. Cuanto menor es la distancia, más similares son las muestras. Las más utilizadas incluyen la distancia Lp (cuando p = 2, es la distancia euclidiana), la distancia de Manhattan, la distancia de Hamming, etc.
Reglas de decisión de clasificación, generalmente votación por mayoría o votación por mayoría basada en la ponderación de la distancia (las ponderaciones son inversamente proporcionales a la distancia).
Los métodos estadísticos no paramétricos se refieren a métodos estadísticos que no se basan en formas paramétricas (como el supuesto de distribución normal en las estadísticas tradicionales, etc.), es decir, no hacen supuestos estrictos sobre la distribución de datos. En comparación con los métodos estadísticos paramétricos (como la regresión lineal, la prueba t, etc.), los métodos estadísticos no paramétricos son más flexibles porque no suponen que los datos sigan un patrón de distribución específico.
Los métodos estadísticos paramétricos se basan en hacer suposiciones y requisitos específicos para la distribución de datos y utilizan ciertos parámetros para describir la forma de distribución de los datos. Estas formas paramétricas pueden simplificar significativamente los modelos y análisis, pero también requieren que estos supuestos y parámetros sean consistentes con los datos reales, lo que puede llevar a conclusiones engañosas cuando no se cumplen los supuestos.
1. Regresión lineal:
Supuesto: Existe una relación lineal entre la variable dependiente (variable de respuesta) y la variable independiente (variable explicativa).
Parámetros: Coeficientes de regresión (pendiente e intercepto), generalmente asumiendo que el término de error tiene media cero, varianza constante (homoscedasticidad) y una distribución normal.
2. Regresión logística:
Supuesto: la variable dependiente (variable categórica) satisface el modelo de regresión logística y el coeficiente de regresión es un valor fijo.
Parámetro: Coeficiente de regresión, utilizado para describir la influencia de las variables independientes sobre las variables dependientes, estimado mediante estimación de máxima verosimilitud.
3. prueba t:
Supuesto: Los datos de la muestra provienen de una población distribuida normalmente.
Parámetros: media y varianza, la prueba t de una muestra asume la media de la población, la prueba t de dos muestras asume la diferencia entre las medias de dos poblaciones.
El proceso del algoritmo de predicción (clasificación) es el siguiente:
(1) Encuentre las k muestras más cercanas a la muestra de prueba x_test en el conjunto de muestras de entrenamiento y guárdelas en el conjunto N;
(2)统计集合N中每一类样本的个数𝐶𝑖,𝑖=1,2,3,...,𝑐;
(3)最终的分类结果为argmax𝐶𝑖 (最大的对应的𝐶𝑖)那个类。
En el proceso de implementación anterior, el valor de k es particularmente importante. Se puede determinar en función de las características del problema y de los datos. En la implementación específica, se puede considerar el peso de la muestra, es decir, cada muestra tiene un peso de votación diferente. Este método se denomina algoritmo de k vecino más cercano ponderado, que es una variante del algoritmo de k vecino más cercano.
假设离测试样本最近的k个训练样本的标签值为𝑦𝑖,则对样本的回归预测输出值为:

Ese es el valor medio de la etiqueta de todos los vecinos.
La función de predicción de regresión con ponderaciones muestrales es:

其中𝑤𝑖为第个𝑖样本的权重。
KNN算法的实现依赖于样本之间的距离,其中最常用的距离函数就是欧氏距离(欧几里得距离)。ℝ𝑛空间中的两点𝑥和𝑦,它们之间的欧氏距离定义为:
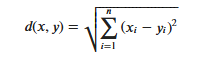
Cabe señalar que cuando se utiliza la distancia euclidiana, cada componente del vector de características debe normalizarse para reducir la interferencia causada por los diferentes rangos de escala de los valores de las características. De lo contrario, los componentes de características con valores pequeños serán reemplazados por características con valores grandes. Los valores característicos están sumergidos.
Otros métodos de cálculo de distancia incluyen la distancia de Mahalanobis, la distancia de Bhattacharyya, etc.
Conocimientos preliminares:
ambiente de laboratorio:
El conjunto de datos de Wine es uno de los conjuntos de datos más famosos para el reconocimiento de patrones. El sitio web oficial del conjunto de datos de Wine:Conjunto de datos sobre el vino . Los datos son el resultado de un análisis químico de vinos de la misma región de Italia pero de tres variedades diferentes. El conjunto de datos analiza las cantidades de 13 ingredientes contenidos en cada uno de tres vinos.Estos 13 atributos son
| Llave | Valor | Llave | Valor |
|---|---|---|---|
| Características del conjunto de datos: | Multivariante | Número de instancias: | 178 |
| Características del atributo: | Entero, real | Número de atributos: | 13 |
| Tareas asociadas: | Clasificación | ¿Valores faltantes? | No |
- %%capture captured_output
- # 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
- !pip uninstall mindspore -y
- !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
- # 查看当前 mindspore 版本
- !pip show mindspore
Name: mindspore Version: 2.2.14 Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Home-page: https://www.mindspore.cn Author: The MindSpore Authors Author-email: [email protected] License: Apache 2.0 Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy Required-by:
- from download import download
-
- # 下载红酒数据集
- url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
- path = download(url, "./", kind="zip", replace=True)
Downloading data from https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip (4 kB) file_sizes: 100%|██████████████████████████| 4.09k/4.09k [00:00<00:00, 2.51MB/s] Extracting zip file... Successfully downloaded / unzipped to ./
Antes de generar datos, importe las bibliotecas de Python necesarias.
La biblioteca del sistema operativo se utiliza actualmente. Para facilitar la comprensión, explicaremos otras bibliotecas requeridas cuando se utilicen específicamente.
Se pueden buscar descripciones detalladas del módulo MindSpore en la página API de MindSpore.
Puede configurar la información requerida para la operación a través de context.set_context, como el modo de operación, información de backend, hardware y otra información.
Importe el módulo de contexto y configure la información necesaria para su funcionamiento.
- %matplotlib inline
- import os
- import csv
- import numpy as np
- import matplotlib.pyplot as plt
-
- import mindspore as ms
- from mindspore import nn, ops
-
- ms.set_context(device_target="CPU")

wine.datay ver algunos datos.- with open('wine.data') as csv_file:
- data = list(csv.reader(csv_file, delimiter=','))
- print(data[56:62]+data[130:133])
[['1', '14.22', '1.7', '2.3', '16.3', '118', '3.2', '3', '.26', '2.03', '6.38', '.94', '3.31', '970'], ['1', '13.29', '1.97', '2.68', '16.8', '102', '3', '3.23', '.31', '1.66', '6', '1.07', '2.84', '1270'], ['1', '13.72', '1.43', '2.5', '16.7', '108', '3.4', '3.67', '.19', '2.04', '6.8', '.89', '2.87', '1285'], ['2', '12.37', '.94', '1.36', '10.6', '88', '1.98', '.57', '.28', '.42', '1.95', '1.05', '1.82', '520'], ['2', '12.33', '1.1', '2.28', '16', '101', '2.05', '1.09', '.63', '.41', '3.27', '1.25', '1.67', '680'], ['2', '12.64', '1.36', '2.02', '16.8', '100', '2.02', '1.41', '.53', '.62', '5.75', '.98', '1.59', '450'], ['3', '12.86', '1.35', '2.32', '18', '122', '1.51', '1.25', '.21', '.94', '4.1', '.76', '1.29', '630'], ['3', '12.88', '2.99', '2.4', '20', '104', '1.3', '1.22', '.24', '.83', '5.4', '.74', '1.42', '530'], ['3', '12.81', '2.31', '2.4', '24', '98', '1.15', '1.09', '.27', '.83', '5.7', '.66', '1.36', '560']]
- X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
- Y = np.array([s[0] for s in data[:178]], np.int32)
- attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
- 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
- 'OD280/OD315 of diluted wines', 'Proline']
- plt.figure(figsize=(10, 8))
- for i in range(0, 4):
- plt.subplot(2, 2, i+1)
- a1, a2 = 2 * i, 2 * i + 1
- plt.scatter(X[:59, a1], X[:59, a2], label='1')
- plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
- plt.scatter(X[130:, a1], X[130:, a2], label='3')
- plt.xlabel(attrs[a1])
- plt.ylabel(attrs[a2])
- plt.legend()
- plt.show()
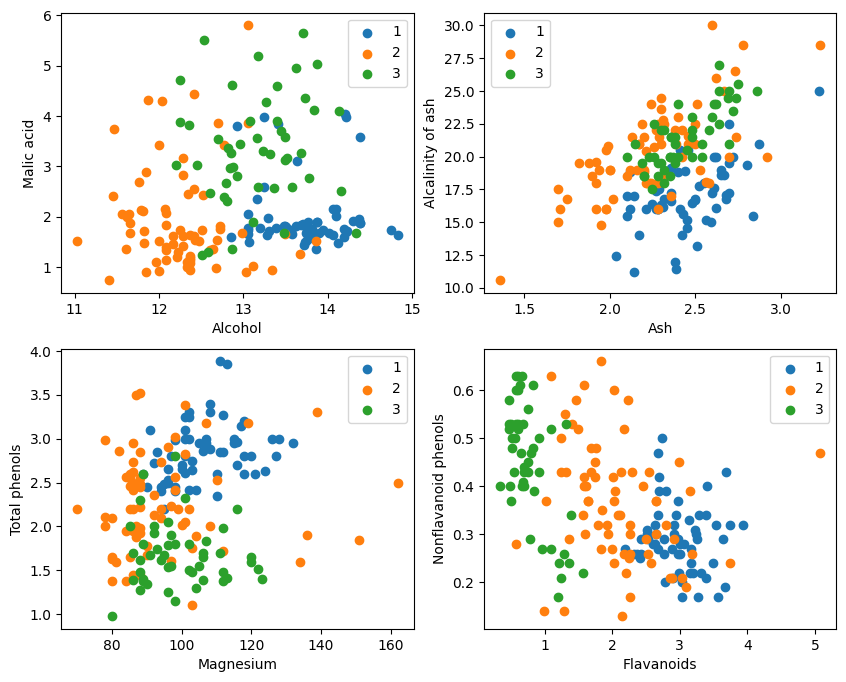
Desde la visualización gráfica, los dos efectos de clasificación de atributos en la esquina superior izquierda y la esquina inferior derecha del gráfico son relativamente buenos, especialmente los límites entre las categorías 1 y 2 son relativamente obvios.
- train_idx = np.random.choice(178, 128, replace=False)
- test_idx = np.array(list(set(range(178)) - set(train_idx)))
- X_train, Y_train = X[train_idx], Y[train_idx]
- X_test, Y_test = X[test_idx], Y[test_idx]
Obtener test_idx = np.array(list(set(range(178)) - set(train_idx)))
1. range(178) genera una secuencia de números enteros del 0 al 177.
2. set(range(178)) convierte esta secuencia de números enteros en un conjunto. Un conjunto es una estructura de datos que no permite elementos repetidos y admite operaciones de conjuntos eficientes (como unión, intersección, diferencia, etc.).
3. set(train_idx) convierte la lista de índice del conjunto de entrenamiento train_idx seleccionada aleatoriamente en un conjunto.
4. set(range(178)) - set(train_idx) calcula la operación de conjunto de diferencias del conjunto y obtiene los elementos que están en set(range(178)) pero no en set(train_idx), que son los índices del equipo de prueba. Esta es una operación establecida que puede calcular rápida y eficientemente los elementos de diferencia.
5. list(...) convierte el resultado de la operación de diferencia nuevamente en una lista.
6. np.array(...) convierte esta lista en una matriz numpy para indexar con matrices numpy X e Y。
Aprovecha lo que ofrece MindSporetile, square, ReduceSum, sqrt, TopKy otros operadores, calculan simultáneamente la distancia entre la muestra de entrada x y otras muestras claramente clasificadas X_train mediante operaciones matriciales, y calculan los k vecinos más cercanos superiores
- class KnnNet(nn.Cell):
- def __init__(self, k):
- super(KnnNet, self).__init__()
- self.k = k
-
- def construct(self, x, X_train):
- #平铺输入x以匹配X_train中的样本数
- x_tile = ops.tile(x, (128, 1))
- square_diff = ops.square(x_tile - X_train)
- square_dist = ops.sum(square_diff, 1)
- dist = ops.sqrt(square_dist)
- #-dist表示值越大,样本就越接近
- values, indices = ops.topk(-dist, self.k)
- return indices
-
- def knn(knn_net, x, X_train, Y_train):
- x, X_train = ms.Tensor(x), ms.Tensor(X_train)
- indices = knn_net(x, X_train)
- topk_cls = [0]*len(indices.asnumpy())
- for idx in indices.asnumpy():
- topk_cls[Y_train[idx]] += 1
- cls = np.argmax(topk_cls)
- return cls
1. Defina la clase de red KNN: KnnNet
Función __init__: inicializa la red y establece el valor K (es decir, el número de vecinos más cercanos seleccionados).
Función de construcción: calcula la distancia euclidiana entre la muestra de entrada x y cada muestra en el conjunto de entrenamiento X_train, y devuelve el índice de las k muestras (es decir, el vecino más cercano) con la distancia más pequeña.
2. Defina la función KNN: knn
Recibe knn_net (instancia de red KNN), muestra de prueba x, muestra de entrenamiento X_train y etiqueta de entrenamiento Y_train como entrada.
Utilice knn_net para encontrar las k muestras vecinas más cercanas de x, clasificarlas según las etiquetas de estas muestras y devolver el resultado de la clasificación (es decir, la categoría predicha).
在验证集上验证KNN算法的有效性,取𝑘=5,验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
- acc = 0
- knn_net = KnnNet(5)
- for x, y in zip(X_test, Y_test):
- pred = knn(knn_net, x, X_train, Y_train)
- acc += (pred == y)
- print('label: %d, prediction: %s' % (y, pred))
- print('Validation accuracy is %f' % (acc/len(Y_test)))
Calcule e imprima la precisión del conjunto de prueba.
Recorra cada muestra en el conjunto de pruebas X_test e Y_test, y use la función knn para clasificar cada muestra.
Las estadísticas predicen la cantidad de muestras correctas, calculan y generan la precisión de la clasificación.
label: 1, prediction: 1 label: 2, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 2 label: 3, prediction: 2 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 2 label: 1, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 1 label: 3, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 Validation accuracy is 0.660000
No es posible alcanzar el 80% cada vez. Después de intentarlo muchas veces, la precisión finalmente alcanzó el 80%:
label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 3 label: 3, prediction: 3 label: 1, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 3, prediction: 3 label: 3, prediction: 3 label: 3, prediction: 2 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 3, prediction: 3 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 1, prediction: 1 label: 2, prediction: 3 label: 2, prediction: 1 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 2 label: 2, prediction: 3 label: 2, prediction: 2 Validation accuracy is 0.820000
Este experimento utiliza MindSpore para implementar el algoritmo KNN para resolver el problema de 3 clasificaciones. Tome los 3 tipos de muestras en el conjunto de datos de vino y divídalos en muestras de categorías conocidas y muestras para verificar. A partir de los resultados de la verificación, podemos ver que el algoritmo KNN es efectivo en esta tarea y puede determinar la variedad de vino en función de. 13 atributos del vino.
Preparación de datos: descargue datos del sitio web oficial del conjunto de datos de Wine o de Huawei Cloud OBS, léalos y procéselos.
Procesamiento de datos: divida el conjunto de datos en variables independientes (13 atributos) y variables dependientes (3 categorías) y visualícelas para observar la distribución de la muestra.
Construcción del modelo: defina la estructura de la red KNN, utilice el operador proporcionado por MindSpore para calcular la distancia entre la muestra de entrada y la muestra de entrenamiento y encuentre los k vecinos más cercanos.
Predicción del modelo: haga predicciones sobre el conjunto de validación y calcule la precisión de la predicción.
Los resultados experimentales muestran que la precisión de clasificación del algoritmo KNN en el conjunto de datos de Wine es cercana al 80% (66%).

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]