2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
本文全面回顾了深度学习中激活函数的发展历程,从早期的Sigmoid和Tanh函数,到广泛应用的ReLU系列,再到近期提出的Swish、Mish和GeLU等新型激活函数。深入分析了各类激活函数的数学表达、特点优势、局限性以及在典型模型中的应用情况。通过系统的对比分析,本文探讨了激活函数的设计原则、性能评估标准以及未来可能的发展方向,为深度学习模型的优化和设计提供理论指导。
激活函数是神经网络中的关键组件,它在神经元的输出端引入非线性特性,使得神经网络能够学习和表示复杂的非线性映射。没有激活函数,无论多么深的神经网络本质上都只能表示线性变换,这大大限制了网络的表达能力。
随着深度学习的快速发展,激活函数的设计和选择已成为影响模型性能的重要因素。不同的激活函数具有不同的特性,如梯度流动性、计算复杂度、非线性程度等,这些特性直接影响着神经网络的训练效率、收敛速度和最终性能。
本文旨在全面回顾激活函数的演变历程,深入分析各类激活函数的特性,并探讨其在现代深度学习模型中的应用。我们将从以下几个方面展开讨论:
通过这一系统的回顾和分析,希望能为研究者和实践者提供一个全面的参考,帮助他们在深度学习模型设计中更好地选择和使用激活函数。
Sigmoid函数是最早被广泛使用的激活函数之一,其数学表达式为:
σ ( x ) = 1 1 + e − x sigma(x) = frac{1}{1 + e^{-x}} σ(x)=1+e−x1
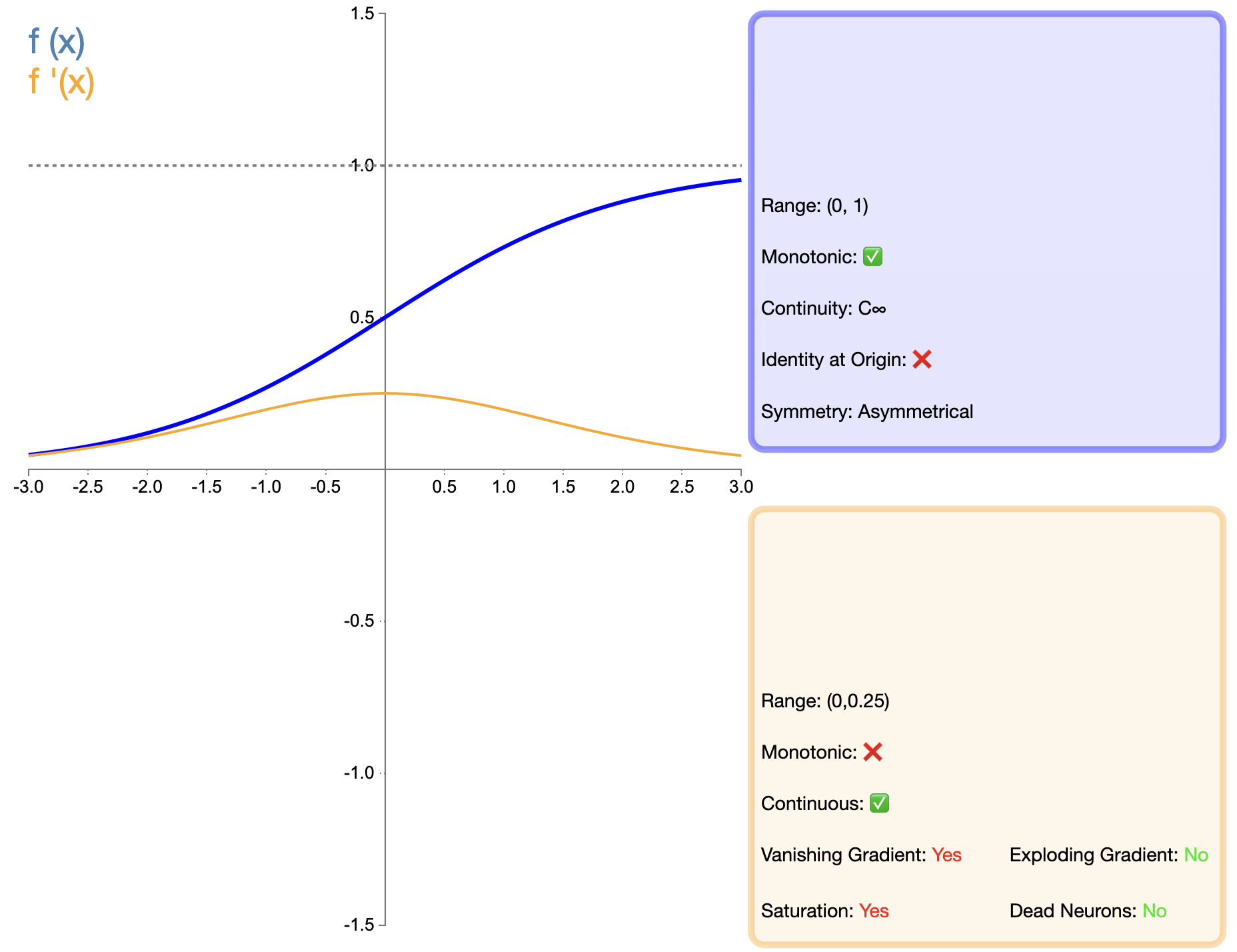
相比于后来出现的ReLU等函数,Sigmoid在深度网络中的应用受到了很大限制,主要是因为其梯度消失问题。然而,在某些特定任务(如二分类)中,Sigmoid仍然是一个有效的选择。
Tanh(双曲正切)函数可视为Sigmoid函数的改进版本,其数学表达式为:
tanh ( x ) = e x − e − x e x + e − x tanh(x) = frac{e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=ex+e−xex−e−x
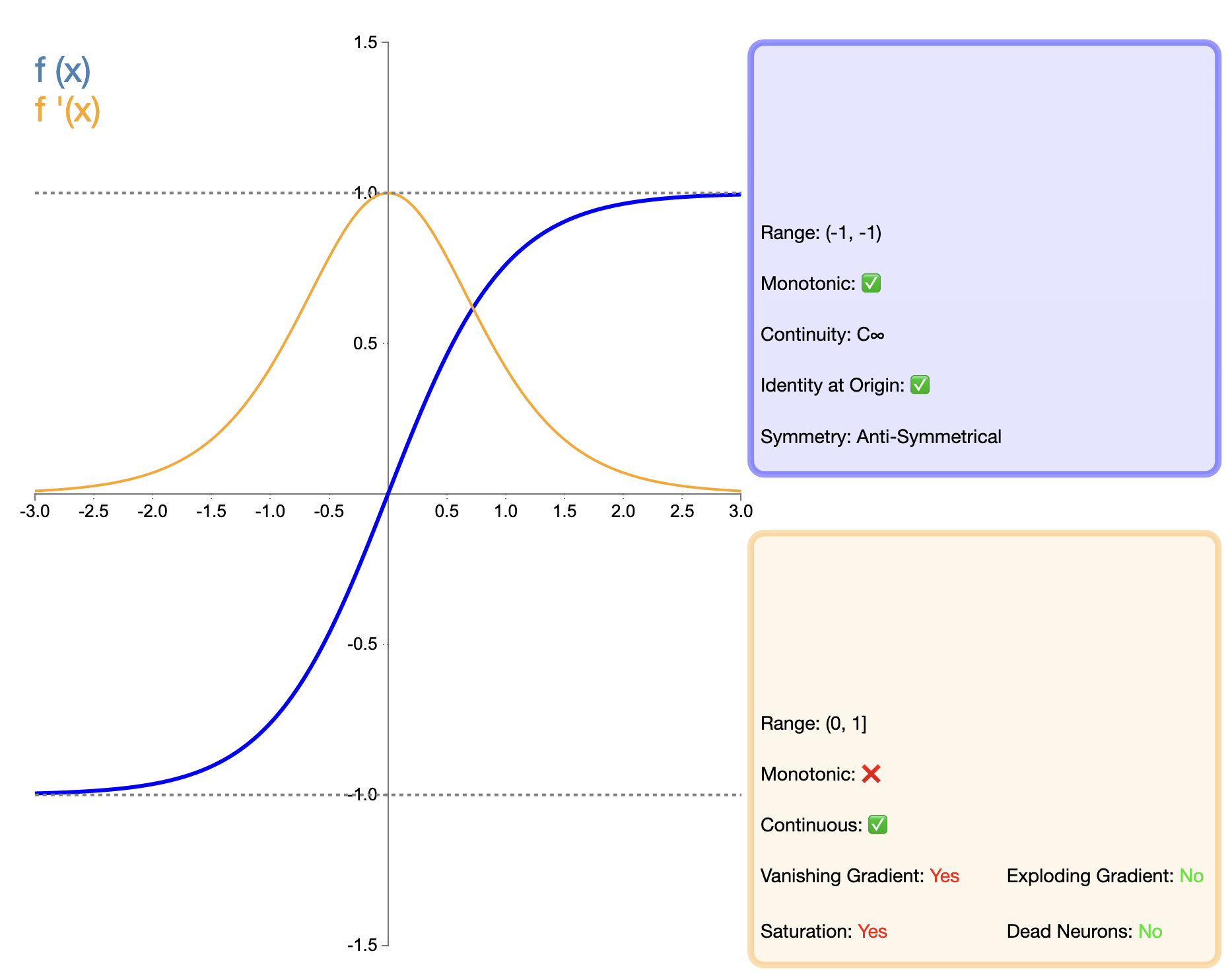
Tanh函数可以看作是Sigmoid函数的改进版本,主要改进在于输出的零中心化。这一特性使得Tanh在许多情况下比Sigmoid表现更好,特别是在深度网络中。然而,与后来出现的ReLU等函数相比,Tanh仍然存在梯度消失的问题,在非常深的网络中可能会影响模型的性能。
Sigmoid和Tanh这两个经典的激活函数在深度学习早期发挥了重要作用,它们的特性和局限性也推动了后续激活函数的发展。虽然在很多场景下已经被更新的激活函数所替代,但在特定的任务和网络结构中,它们仍然有其独特的应用价值。
ReLU函数的提出是激活函数发展的一个重要里程碑。其数学表达式简单:
ReLU ( x ) = max ( 0 , x ) text{ReLU}(x) = max(0, x) ReLU(x)=max(0,x)
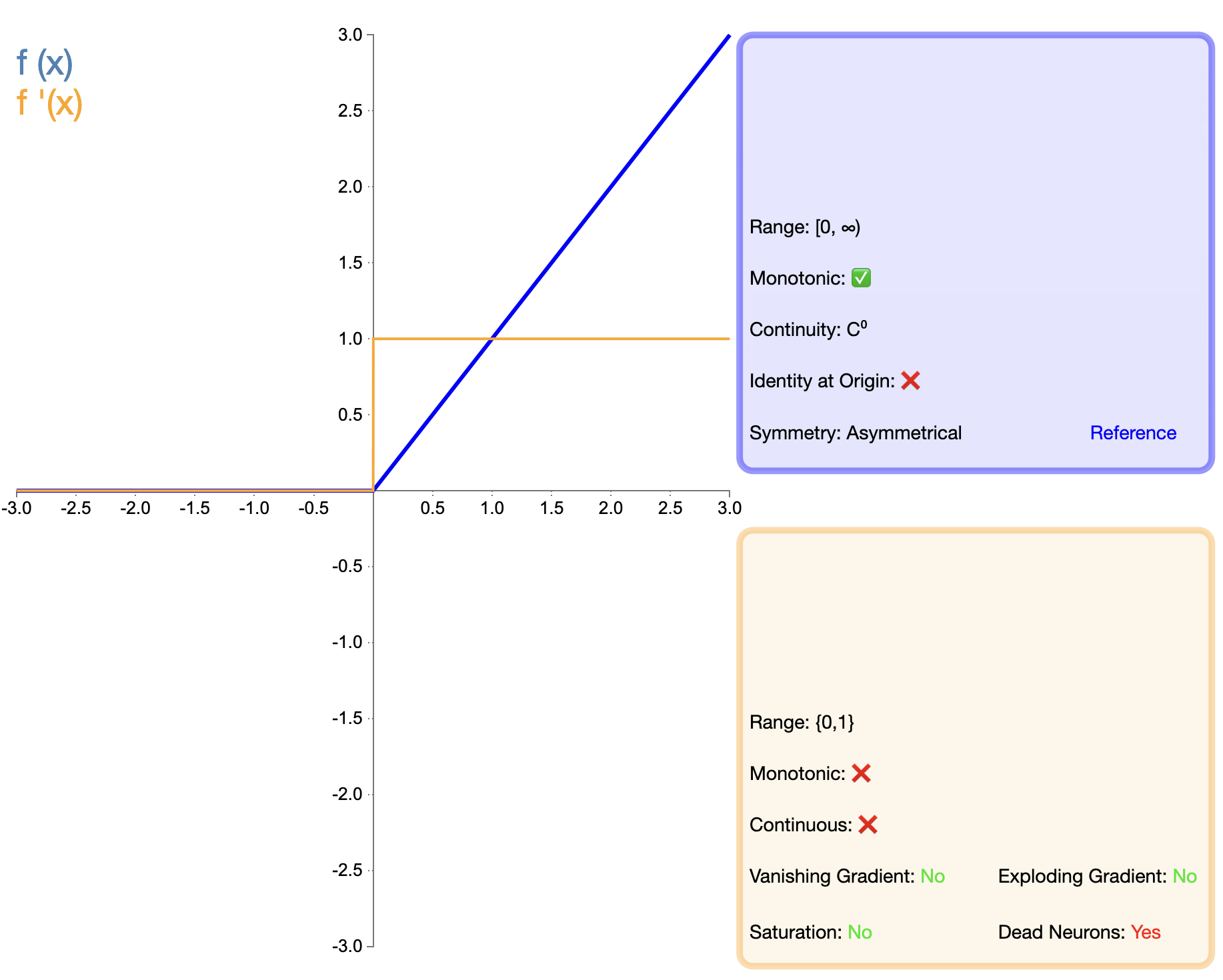
相比Sigmoid和Tanh,ReLU在深度网络中表现出显著优势,主要体现在训练速度和缓解梯度消失方面。然而,"死亡ReLU"问题促使研究者们提出了多种改进版本。
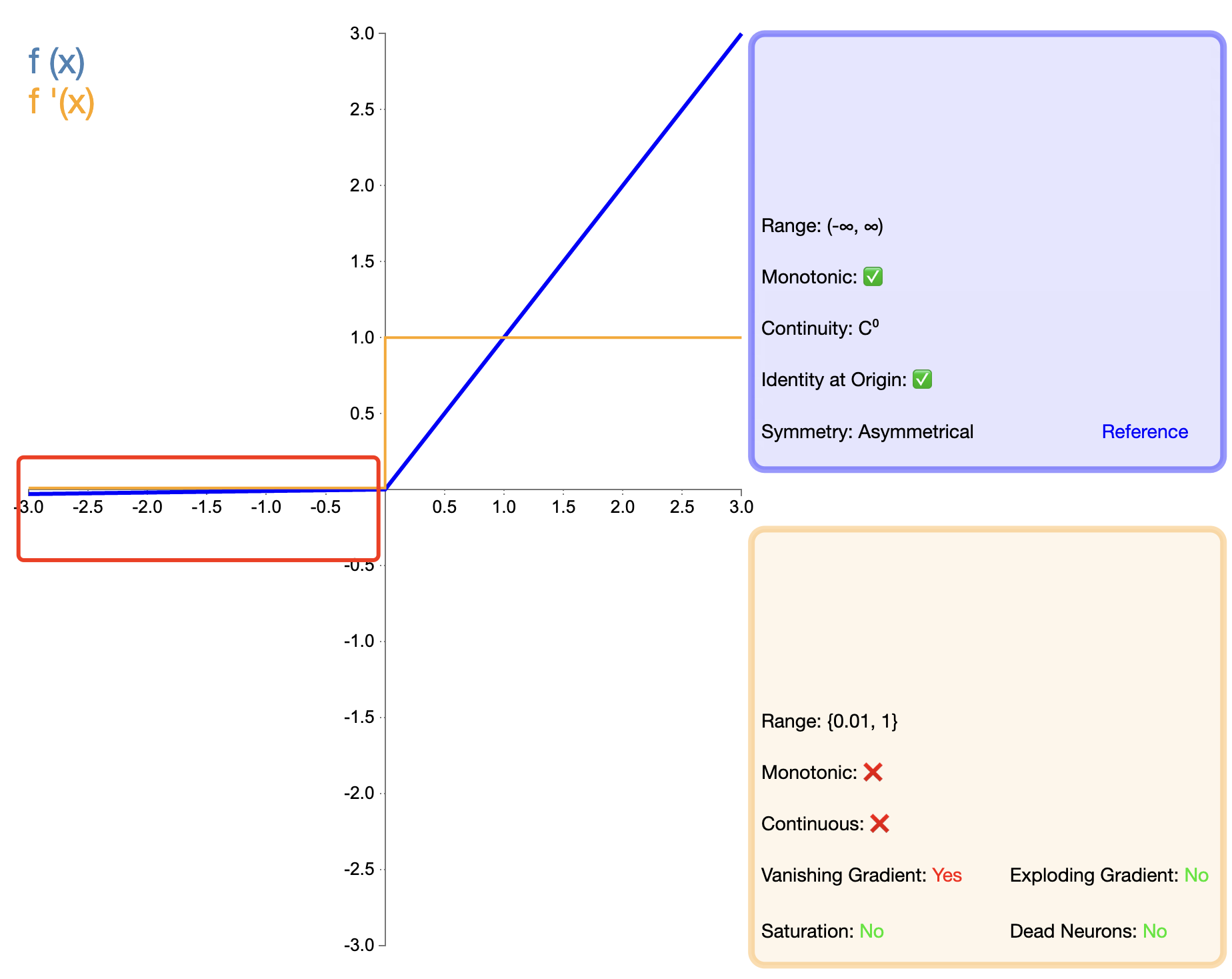
为了解决ReLU的"死亡"问题,Leaky ReLU被提出:
Leaky ReLU ( x ) = { x , if x > 0 α x , if x ≤ 0 text{Leaky ReLU}(x) = {x,if x>0αx,if x≤0 Leaky ReLU(x)={
x,αx,if x>0if x≤0
其中, α alpha α 是一个小的正常数,通常取0.01。
PReLU是Leaky ReLU的一个变体,其中负半轴的斜率是可学习的参数:
PReLU ( x ) = { x , if x > 0 α x , if x ≤ 0 text{PReLU}(x) = {x,if x>0αx,if x≤0 PReLU(x)={
x,αx,if x>0if x≤0
这里的 α alpha α 是通过反向传播学习得到的参数。
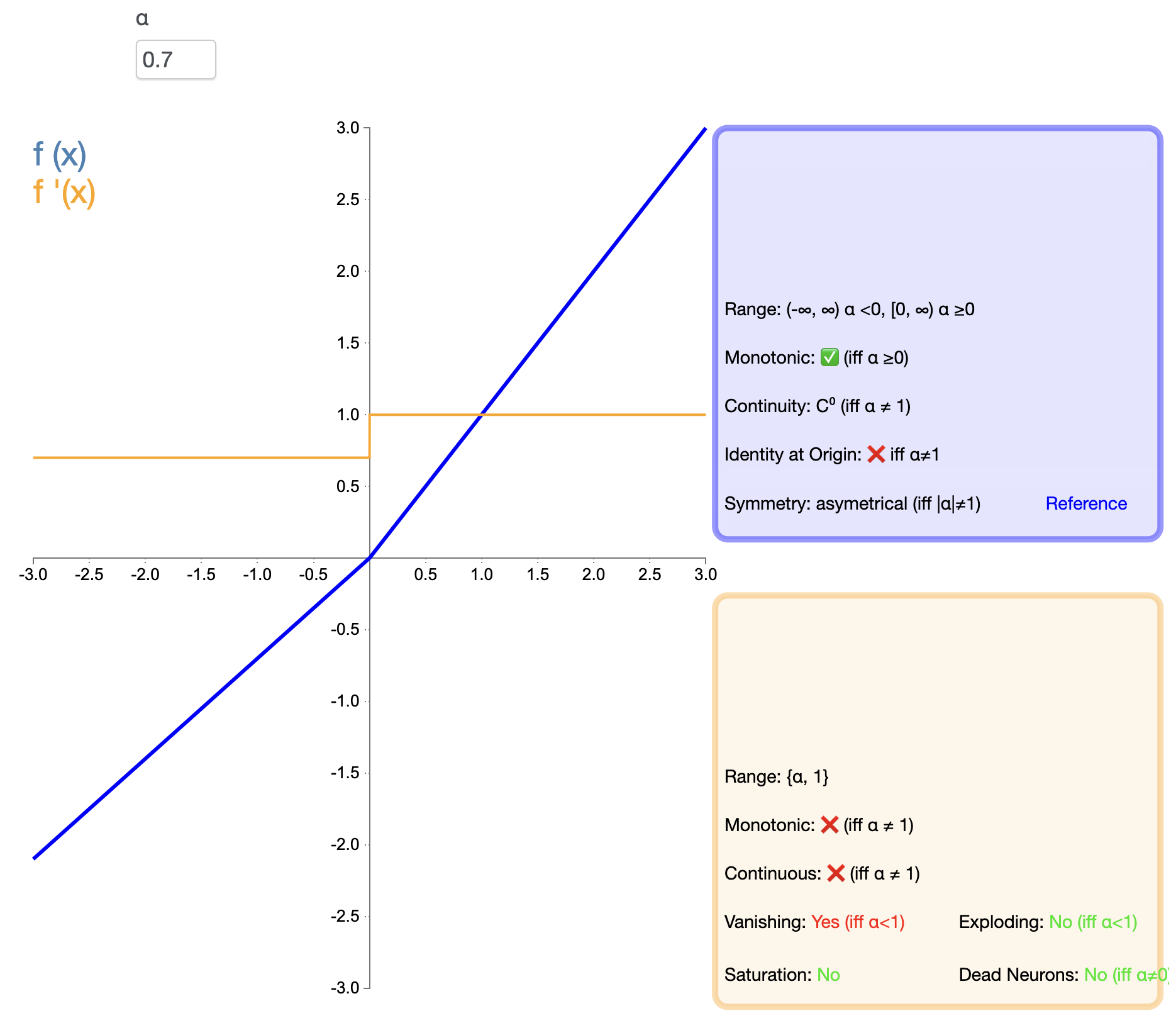
ELU试图结合ReLU的优点和负值输入的处理,其数学表达式为:
ELU ( x ) = { x , if x > 0 α ( e x − 1 ) , if x ≤ 0 text{ELU}(x) = {x,if x>0α(ex−1),if x≤0 ELU(x)=

潜心研究技术三十余年,精通java、linux、javascript、php、css、等等各种语言,在开源领域有诸多贡献,建立开发者文档站,将一些技术开发中的问题分享出来,以供大家查阅
