2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Tässä artikkelissa tarkastellaan kattavasti syväoppimisen aktivointitoimintojen kehitystä varhaisista Sigmoid- ja Tanh-funktioista laajalti käytettyihin ReLU-sarjoihin ja äskettäin ehdotettuihin uusiin aktivointitoimintoihin, kuten Swish, Mish ja GeLU. Suoritetaan syvällinen analyysi erilaisten aktivointifunktioiden matemaattisista lausekkeista, ominaisuuksista, eduista, rajoituksista ja sovelluksista tyypillisissä malleissa. Tämä artikkeli käsittelee systemaattisen vertailevan analyysin avulla suunnittelun periaatteita, suorituskyvyn arviointistandardeja ja aktivointitoimintojen mahdollisia tulevaisuuden kehityssuuntia sekä antaa teoreettista ohjausta syväoppimismallien optimointiin ja suunnitteluun.
Aktivointitoiminto on hermoverkkojen avainkomponentti, joka tuo epälineaarisia ominaisuuksia hermosolujen ulostuloon, jolloin hermoverkot voivat oppia ja edustaa monimutkaisia epälineaarisia kartoituksia. Ilman aktivointifunktiota, riippumatta siitä, kuinka syvä neuroverkko on, se voi olennaisesti edustaa vain lineaarisia muunnoksia, mikä rajoittaa suuresti verkon ilmaisukykyä.
Syväoppimisen nopean kehityksen myötä aktivointitoimintojen suunnittelusta ja valinnasta on tullut tärkeitä mallin suorituskykyyn vaikuttavia tekijöitä. Eri aktivointifunktioilla on erilaiset ominaisuudet, kuten gradientin juoksevuus, laskennallinen monimutkaisuus, epälineaarisuuden aste jne. Nämä ominaisuudet vaikuttavat suoraan hermoverkon koulutustehokkuuteen, konvergenssinopeuteen ja lopulliseen suorituskykyyn.
Tämän artikkelin tavoitteena on tarkastella kattavasti aktivointitoimintojen kehitystä, analysoida syvällisesti eri aktivointitoimintojen ominaisuuksia ja tutkia niiden soveltamista nykyaikaisissa syväoppimismalleissa. Keskustelemme seuraavista näkökohdista:
Tämän systemaattisen katsauksen ja analyysin avulla toivomme tarjoavamme kattavan referenssin tutkijoille ja alan ammattilaisille, jotta he voivat valita ja käyttää aktivointitoimintoja paremmin syvän oppimismallin suunnittelussa.
Sigmoid-funktio on yksi varhaisimmista laajalti käytetyistä aktivointifunktioista, ja sen matemaattinen ilmaisu on:
σ ( x ) = 1 1 + e − x sigma(x) = murtoluku{1}{1 + e^{-x}}σ(x)=1+e−x1
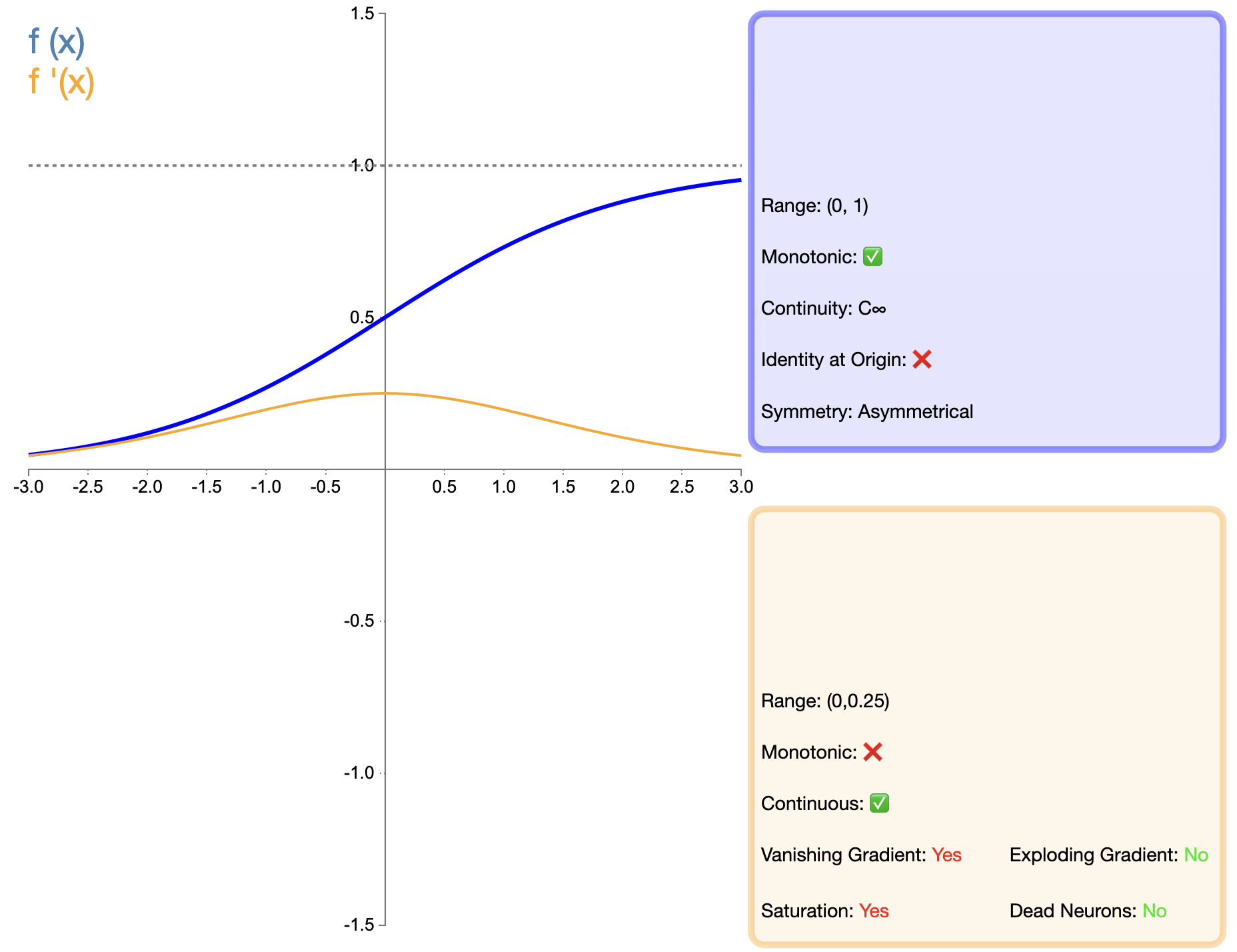
Verrattuna myöhemmin ilmestyneisiin ReLU:n kaltaisiin toimintoihin, Sigmoidin käyttö syväverkoissa on ollut suuresti rajoitettua lähinnä sen katoavan gradienttiongelman vuoksi. Joissakin erityistehtävissä (kuten binääriluokituksessa) sigmoidi on kuitenkin edelleen tehokas valinta.
Tanh-funktiota (hyperbolinen tangentti) voidaan pitää sigmoidifunktion paranneltu versiona, ja sen matemaattinen lauseke on:
tanh ( x ) = ex − e − xex + e − x tanh(x) = frac{e^x - e^{-x}}{e^x + e^{-x}}tanh(x)=ex+e−xex−e−x
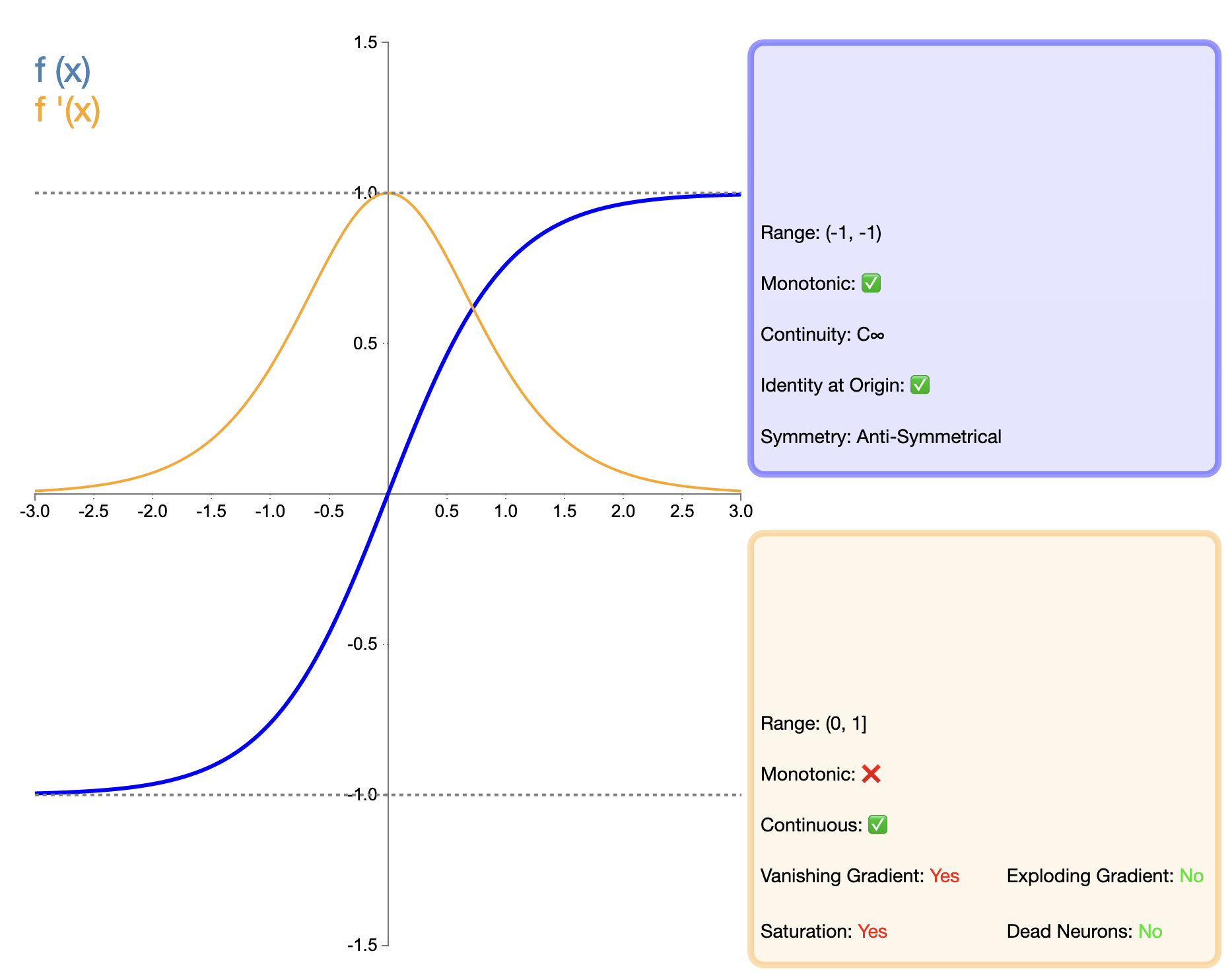
Tanh-toimintoa voidaan pitää Sigmoid-toiminnon paranneltua versiota. Suurin parannus on lähdön nollakeskittäminen. Tämän ominaisuuden ansiosta Tanh toimii paremmin kuin Sigmoid monissa tilanteissa, erityisesti syväverkoissa. Verrattuna myöhemmin ilmestyneisiin ReLU:n kaltaisiin toimintoihin, Tanhilla on kuitenkin edelleen gradientin katoamisongelma, mikä voi vaikuttaa mallin suorituskykyyn erittäin syvissä verkoissa.
Kaksi klassista aktivointitoimintoa, Sigmoid ja Tanh, olivat tärkeässä roolissa syvän oppimisen alkuaikoina, ja niiden ominaisuudet ja rajoitukset edistivät myös myöhempien aktivointitoimintojen kehittymistä. Vaikka ne on korvattu päivitetyillä aktivointitoiminnoilla monissa skenaarioissa, niillä on edelleen ainutlaatuinen sovellusarvo tietyissä tehtävissä ja verkkorakenteissa.
ReLU-toiminnon ehdotus on tärkeä virstanpylväs aktivointitoimintojen kehittämisessä. Sen matemaattinen lauseke on yksinkertainen:
ReLU ( x ) = max ( 0 , x ) teksti{ReLU}(x) = max(0, x)ReLU(x)=max(0,x)
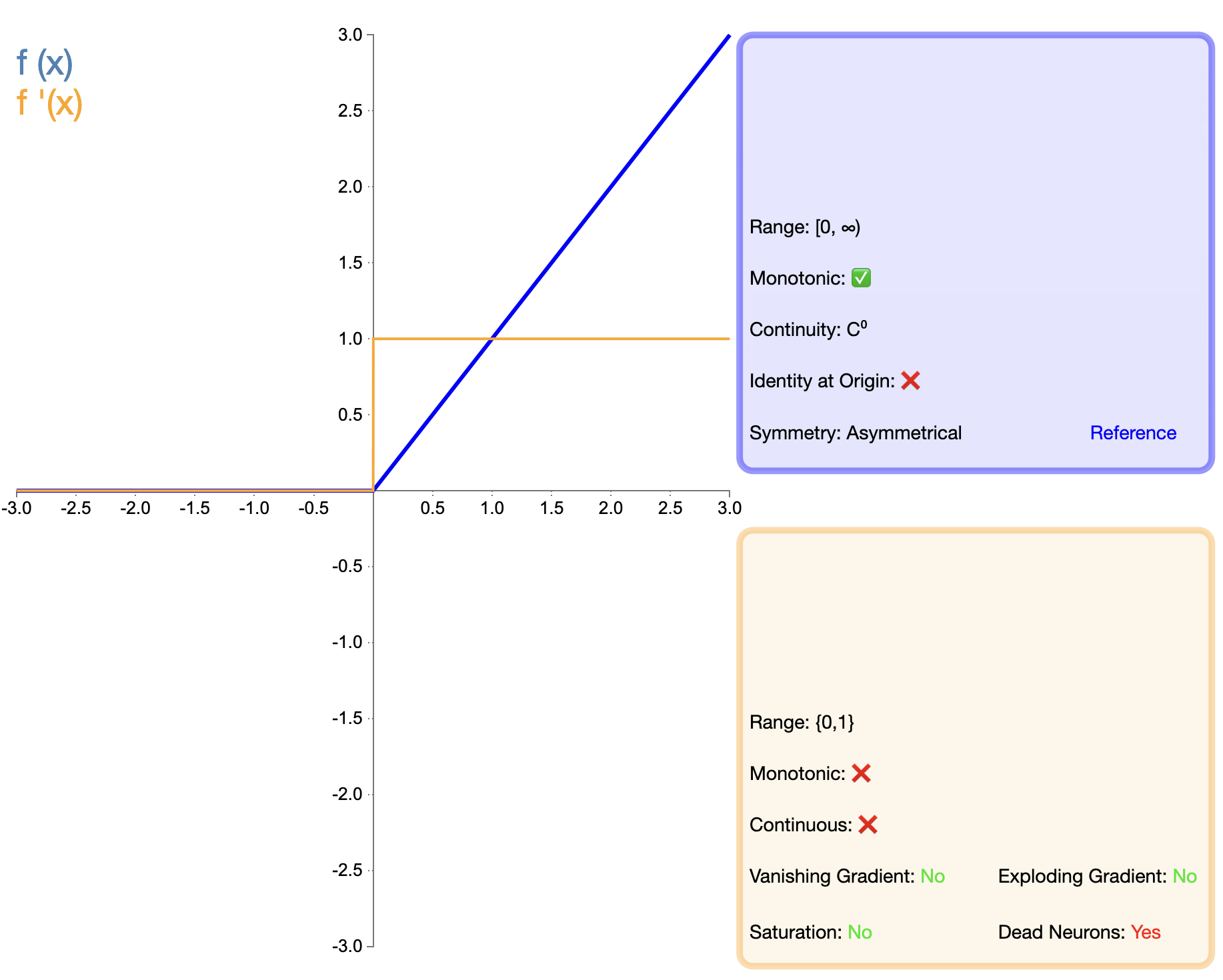
Sigmoidiin ja Tanhiin verrattuna ReLU:lla on merkittäviä etuja syväverkoissa, lähinnä harjoitusnopeuden ja gradientin katoamisen vähentämisen suhteen. Kuitenkin "kuollut ReLU" -ongelma on saanut tutkijat ehdottamaan erilaisia parannettuja versioita.
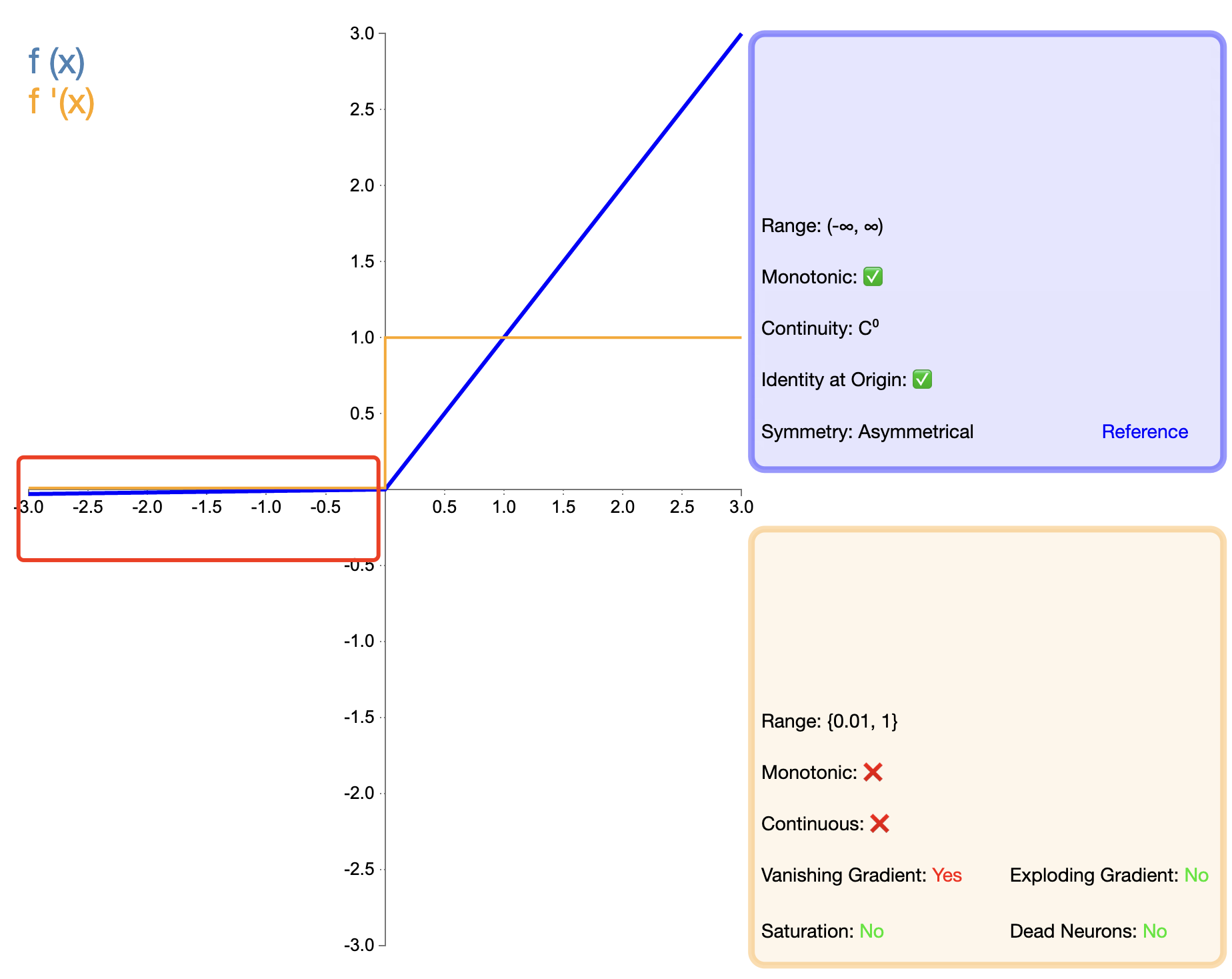
ReLU:n "kuolema"-ongelman ratkaisemiseksi ehdotettiin Leaky ReLU:ta:
Vuotava ReLU ( x ) = { x , jos x > 0 α x , jos x ≤ 0 teksti{Vuotava ReLU}(x) ={x,josx>0αx,josx≤0 Vuotava ReLU(x)={
x,αx,josx>0josx≤0
sisään, α alfaα on pieni positiivinen vakio, yleensä 0,01.
PReLU on muunnos Leaky ReLU:sta, jossa negatiivisen puoliakselin kaltevuus on opittava parametri:
PReLU ( x ) = { x , jos x > 0 α x , jos x ≤ 0 teksti{PReLU}(x) ={x,josx>0αx,josx≤0 PReLU(x)={
x,αx,josx>0josx≤0
tässä α alfaα ovat backpropagation kautta opittuja parametreja.
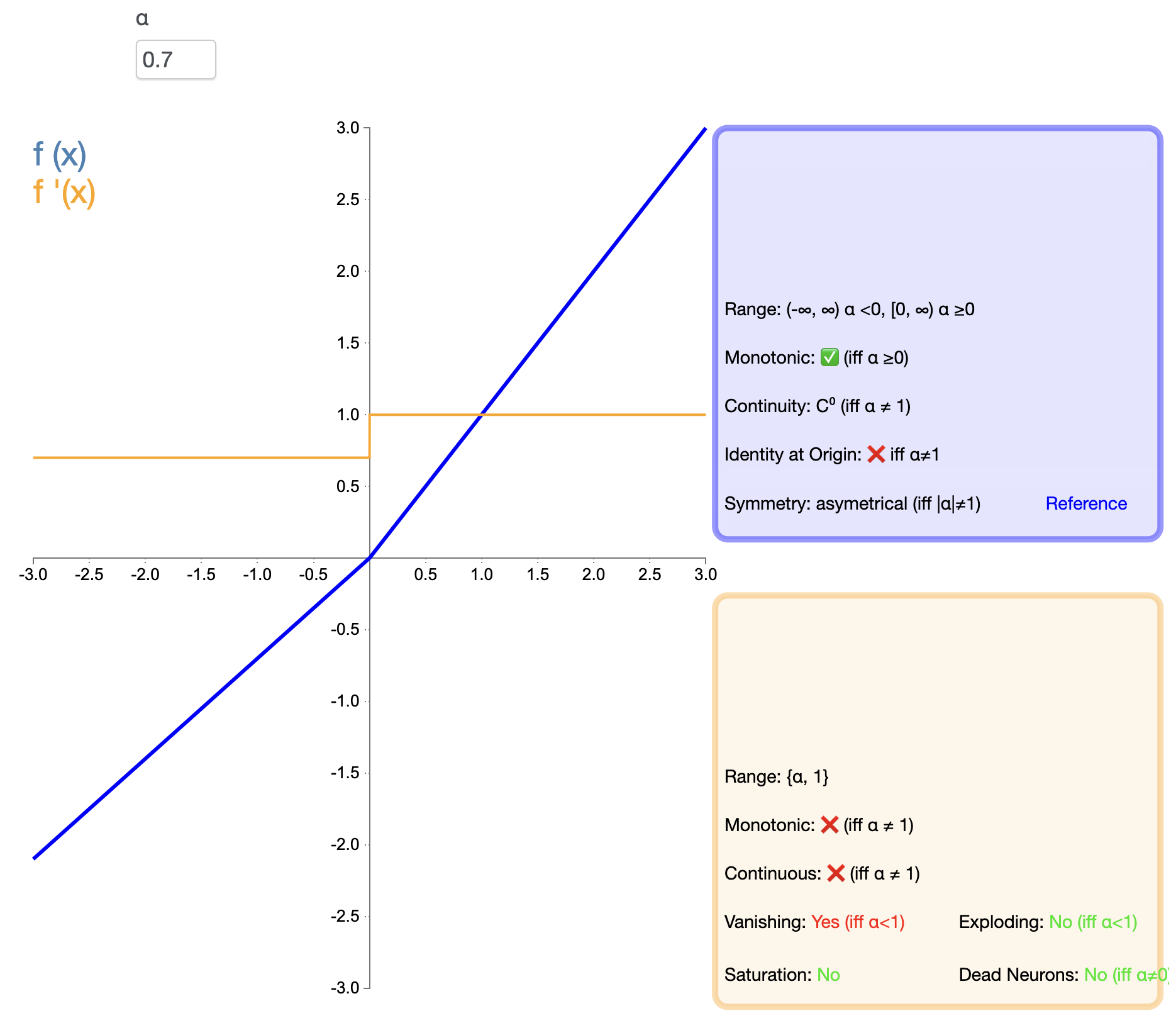
ELU yrittää yhdistää ReLU:n edut negatiivisten syötteiden käsittelyyn. Sen matemaattinen lauseke on:
ELU ( x ) = { x , jos x > 0 α ( ex − 1 ) , jos x ≤ 0 teksti{ELU}(x) ={x,josx>0α(ex−1),josx≤0 ELU(x)=

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema jakaaksesi joitain teknologian kehittämisen ongelmia tulevaa käyttöä varten
