2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Dieser Artikel gibt einen umfassenden Überblick über die Entwicklung von Aktivierungsfunktionen im Deep Learning, von den frühen Sigmoid- und Tanh-Funktionen über die weit verbreitete ReLU-Reihe bis hin zu den kürzlich vorgeschlagenen neuen Aktivierungsfunktionen wie Swish, Mish und GeLU. Es wird eine eingehende Analyse der mathematischen Ausdrücke, Eigenschaften, Vorteile, Einschränkungen und Anwendungen verschiedener Aktivierungsfunktionen in typischen Modellen durchgeführt. Durch eine systematische vergleichende Analyse werden in diesem Artikel die Entwurfsprinzipien, Leistungsbewertungsstandards und mögliche zukünftige Entwicklungsrichtungen von Aktivierungsfunktionen erörtert und theoretische Leitlinien für die Optimierung und Gestaltung von Deep-Learning-Modellen bereitgestellt.
Die Aktivierungsfunktion ist eine Schlüsselkomponente in neuronalen Netzen, die nichtlineare Eigenschaften am Ausgang von Neuronen einführt und es neuronalen Netzen ermöglicht, komplexe nichtlineare Abbildungen zu lernen und darzustellen. Ohne Aktivierungsfunktion kann ein neuronales Netzwerk, egal wie tief es ist, im Wesentlichen nur lineare Transformationen darstellen, was die Ausdrucksfähigkeit des Netzwerks stark einschränkt.
Mit der rasanten Entwicklung des Deep Learning sind das Design und die Auswahl von Aktivierungsfunktionen zu wichtigen Faktoren geworden, die die Modellleistung beeinflussen. Verschiedene Aktivierungsfunktionen weisen unterschiedliche Eigenschaften auf, z. B. Gradientenflüssigkeit, Rechenkomplexität, Grad der Nichtlinearität usw. Diese Eigenschaften wirken sich direkt auf die Trainingseffizienz, die Konvergenzgeschwindigkeit und die endgültige Leistung des neuronalen Netzwerks aus.
Ziel dieses Artikels ist es, die Entwicklung von Aktivierungsfunktionen umfassend zu überprüfen, die Eigenschaften verschiedener Aktivierungsfunktionen eingehend zu analysieren und ihre Anwendung in modernen Deep-Learning-Modellen zu untersuchen. Wir werden folgende Aspekte besprechen:
Wir hoffen, durch diese systematische Überprüfung und Analyse eine umfassende Referenz für Forscher und Praktiker bereitzustellen, die ihnen dabei hilft, Aktivierungsfunktionen im Deep-Learning-Modelldesign besser auszuwählen und zu nutzen.
Die Sigmoidfunktion ist eine der frühesten weit verbreiteten Aktivierungsfunktionen und ihr mathematischer Ausdruck lautet:
σ ( x ) = 1 1 + e − x sigma(x) = frac{1}{1 + e^{-x}}σ(X)=1+t−X1
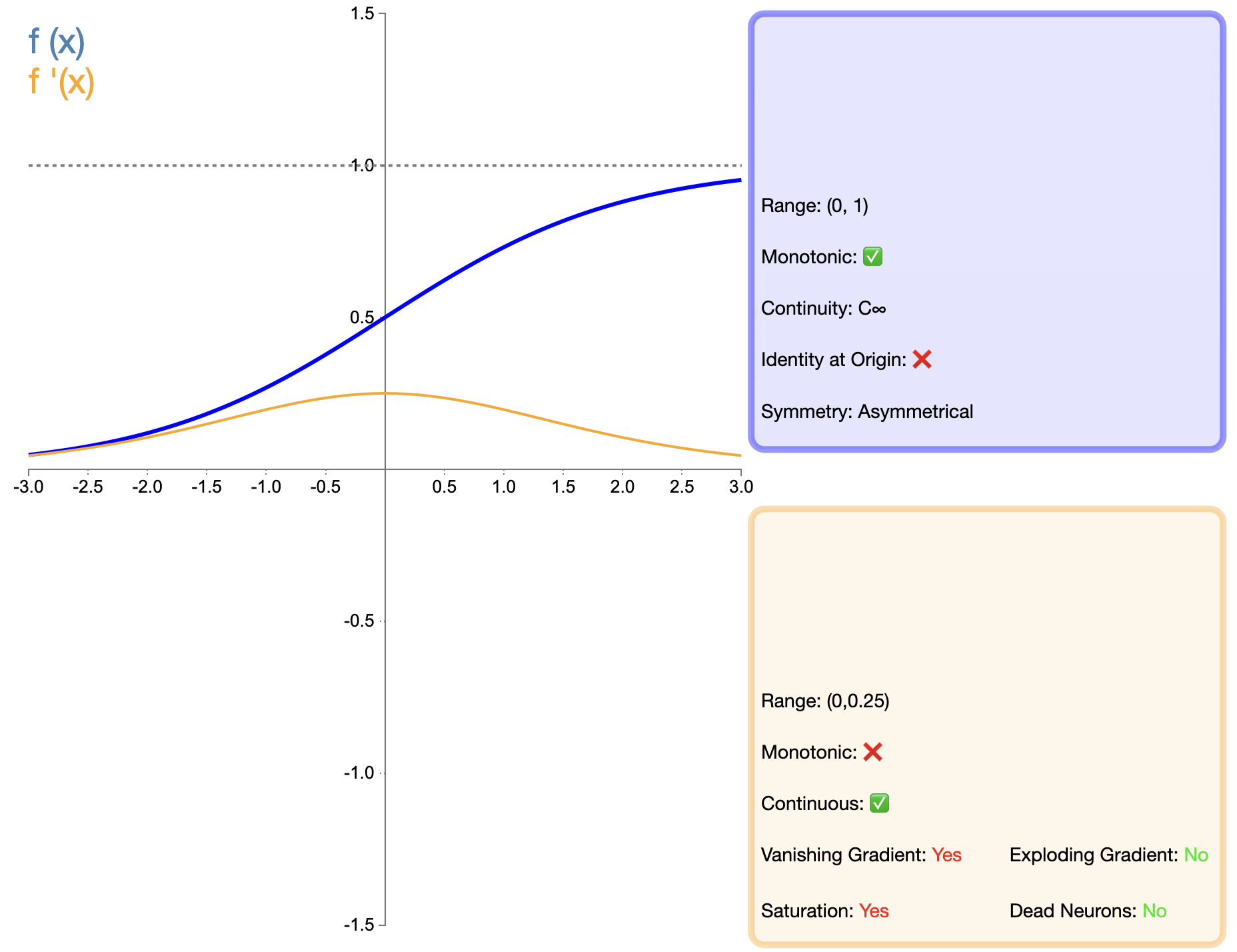
Im Vergleich zu Funktionen wie ReLU, die später erschienen, war die Anwendung von Sigmoid in tiefen Netzwerken stark eingeschränkt, hauptsächlich aufgrund des Problems des verschwindenden Gradienten. Bei einigen spezifischen Aufgaben (z. B. der binären Klassifizierung) ist Sigmoid jedoch immer noch eine effektive Wahl.
Die Tanh-Funktion (Tangens hyperbolicus) kann als verbesserte Version der Sigmoid-Funktion betrachtet werden und ihr mathematischer Ausdruck lautet:
tanh ( x ) = ex − e − xex + e − x tanh(x) = frac{e^x - e^{-x}}{e^x + e^{-x}}tanh(X)=tX+t−XtX−t−X
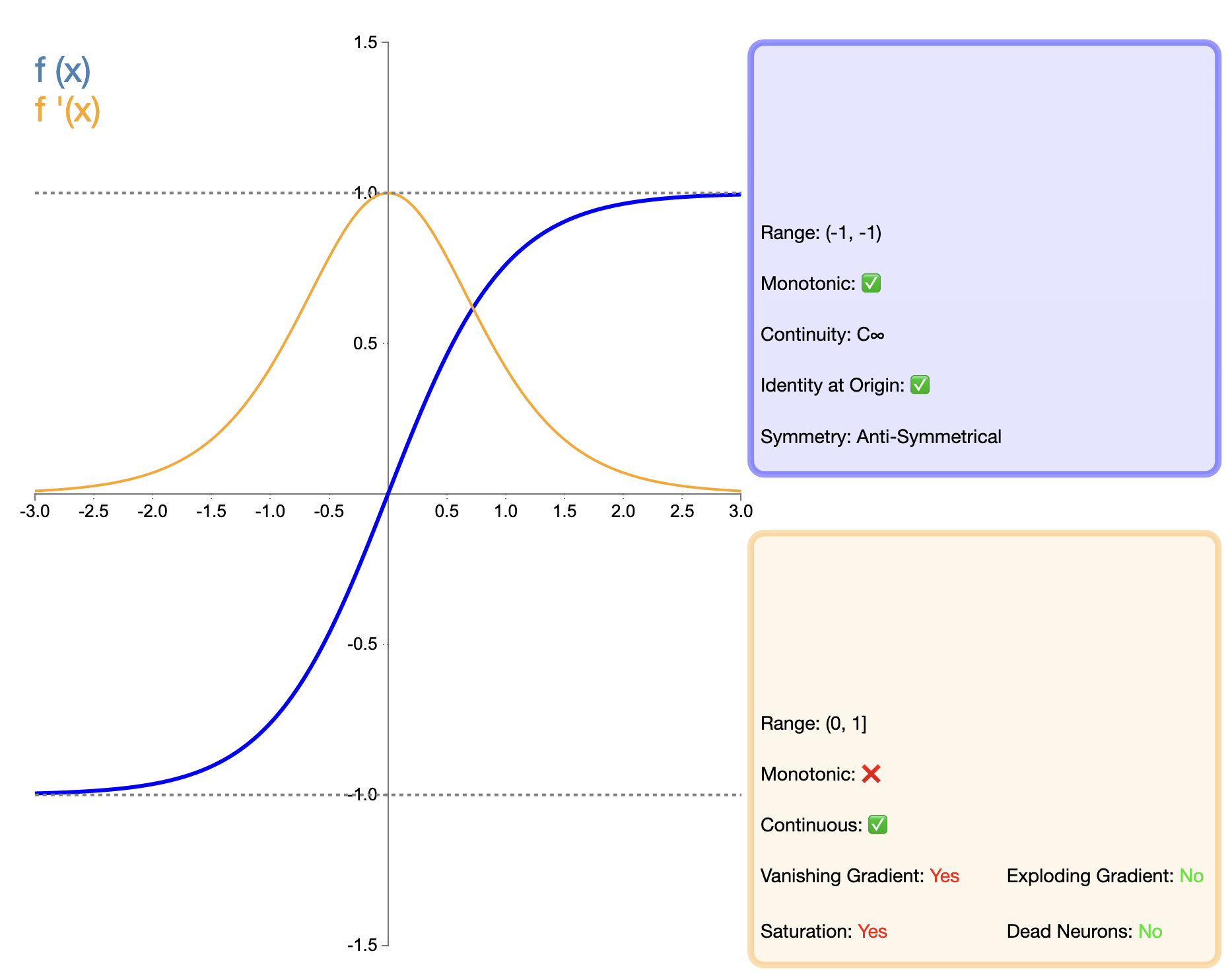
Die Tanh-Funktion kann als verbesserte Version der Sigmoid-Funktion angesehen werden. Die Hauptverbesserung liegt in der Nullzentrierung der Ausgabe. Durch diese Funktion ist Tanh in vielen Situationen leistungsfähiger als Sigmoid, insbesondere in tiefen Netzwerken. Im Vergleich zu Funktionen wie ReLU, die später erschienen, besteht bei Tanh jedoch immer noch das Problem des Verschwindens des Gradienten, was die Leistung des Modells in sehr tiefen Netzwerken beeinträchtigen kann.
Die beiden klassischen Aktivierungsfunktionen Sigmoid und Tanh spielten in den Anfängen des Deep Learning eine wichtige Rolle, und ihre Eigenschaften und Einschränkungen förderten auch die Entwicklung nachfolgender Aktivierungsfunktionen. Obwohl sie in vielen Szenarien durch aktualisierte Aktivierungsfunktionen ersetzt wurden, haben sie immer noch ihren einzigartigen Anwendungswert bei bestimmten Aufgaben und Netzwerkstrukturen.
Der Vorschlag der ReLU-Funktion ist ein wichtiger Meilenstein in der Entwicklung von Aktivierungsfunktionen. Sein mathematischer Ausdruck ist einfach:
ReLU ( x ) = max ( 0 , x ) text{ReLU}(x) = max(0, x)ReLU(X)=max(0,X)
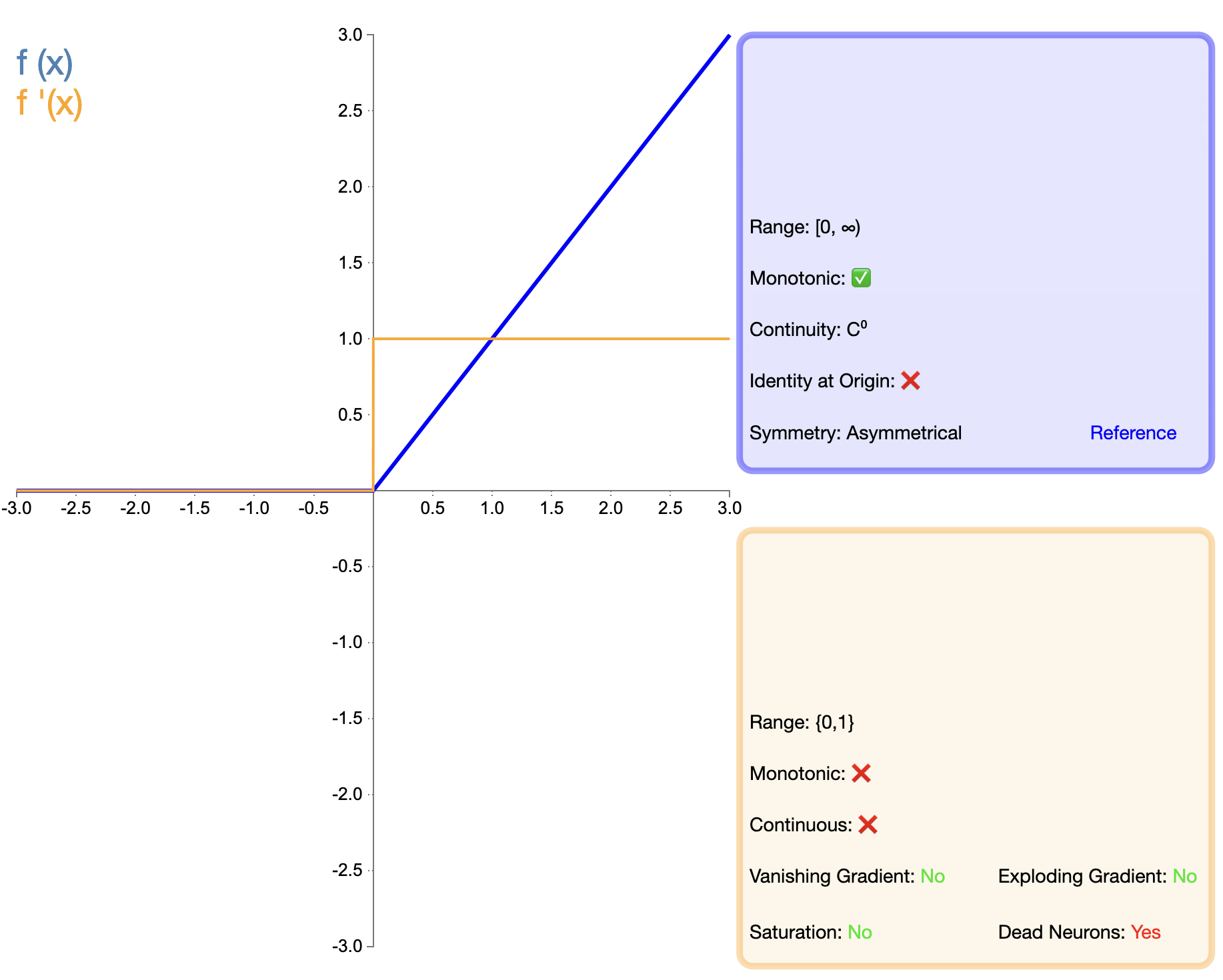
Im Vergleich zu Sigmoid und Tanh weist ReLU in tiefen Netzwerken erhebliche Vorteile auf, hauptsächlich im Hinblick auf die Trainingsgeschwindigkeit und die Abschwächung des Verschwindens des Gradienten. Das Problem des „toten ReLU“ hat Forscher jedoch dazu veranlasst, verschiedene verbesserte Versionen vorzuschlagen.
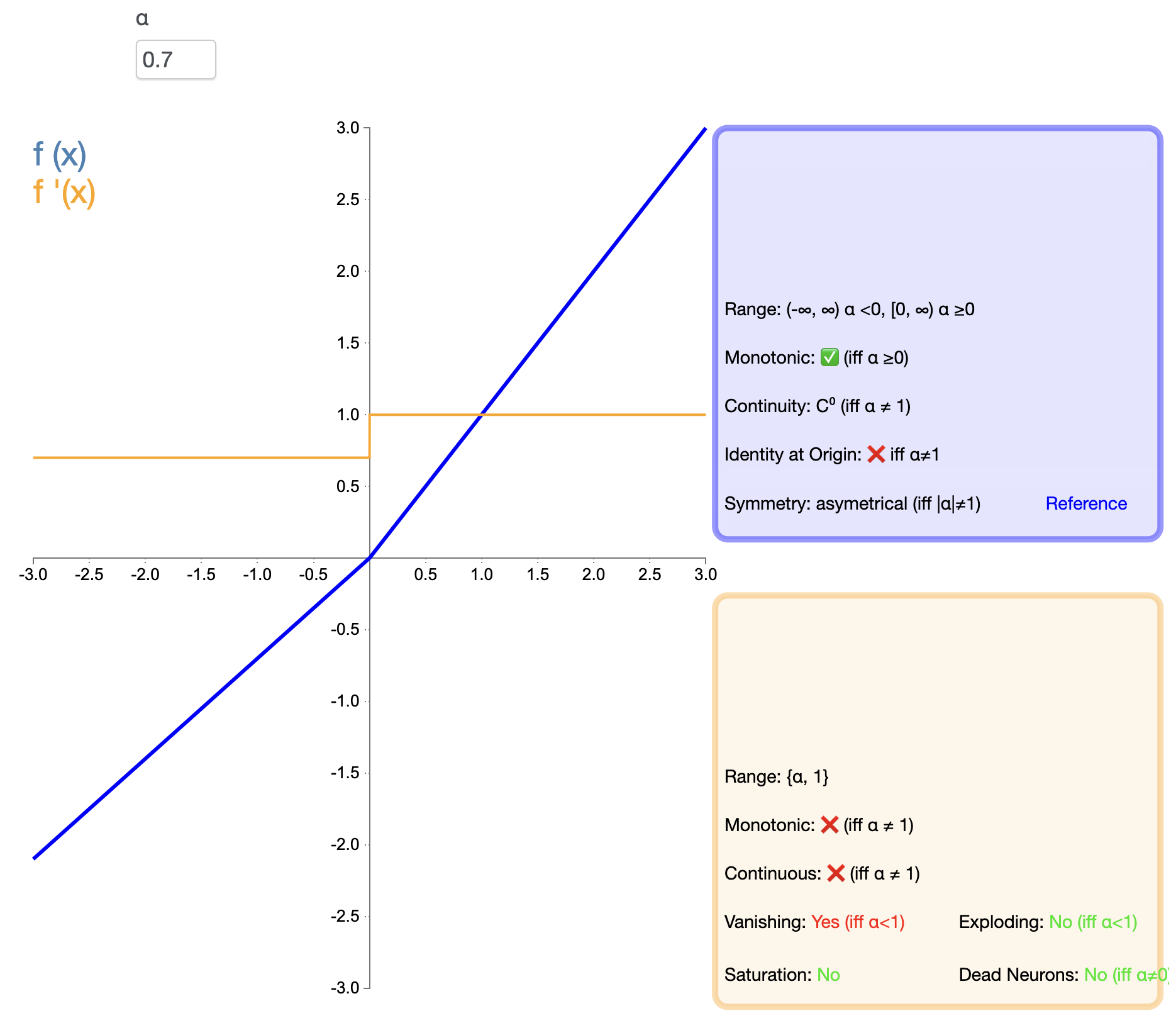
Um das „Tod“-Problem von ReLU zu lösen, wurde Leaky ReLU vorgeschlagen:
Leaky ReLU ( x ) = { x , wenn x > 0 α x , wenn x ≤ 0 text{Leaky ReLU}(x) ={X,WennX>0αX,WennX≤0 Undichtes ReLU(X)={
X,αx,WennX>0WennX≤0
In, α alphaα ist eine kleine positive Konstante, normalerweise 0,01.
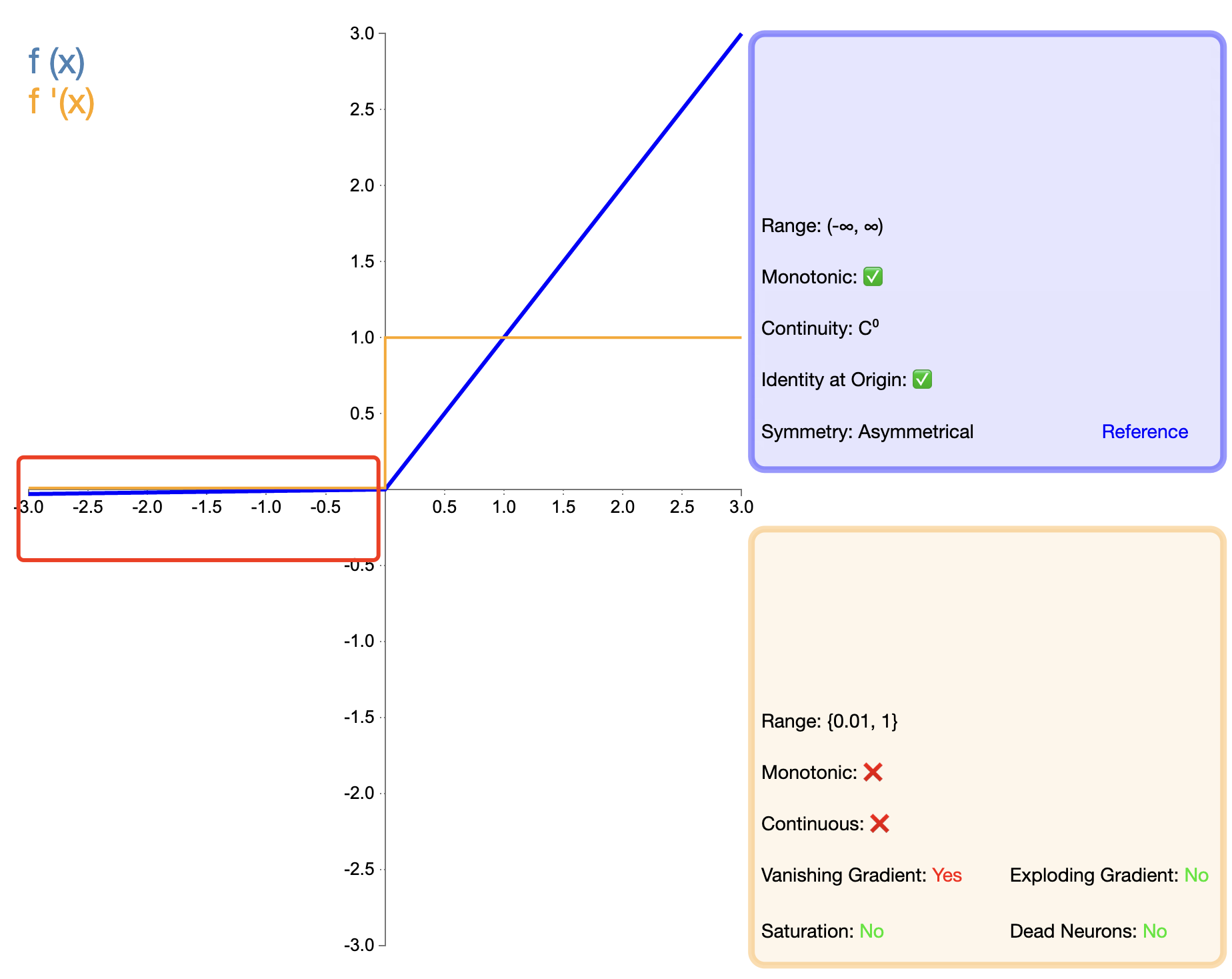
PReLU ist eine Variante von Leaky ReLU, bei der die Steigung der negativen Halbachse ein lernbarer Parameter ist:
PReLU ( x ) = { x , wenn x > 0 α x , wenn x ≤ 0 text{PReLU}(x) ={X,WennX>0αX,WennX≤0 PRELU(X)={
X,αx,WennX>0WennX≤0
Hier α alphaα sind Parameter, die durch Backpropagation gelernt werden.
ELU versucht, die Vorteile von ReLU und der Verarbeitung negativer Eingaben zu kombinieren. Sein mathematischer Ausdruck ist:
ELU ( x ) = { x , wenn x > 0 α ( ex − 1 ) , wenn x ≤ 0 text{ELU}(x) ={X,WennX>0α(tX−1),WennX≤0 ELU(X)=

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen
