내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
이 글에서는 초기 Sigmoid 및 Tanh 함수부터 널리 사용되는 ReLU 시리즈, 그리고 최근 제안된 Swish, Mish 및 GeLU와 같은 새로운 활성화 함수에 이르기까지 딥러닝에서의 활성화 함수 개발을 종합적으로 검토합니다. 일반적인 모델의 다양한 활성화 함수의 수학적 표현, 특성, 장점, 한계 및 적용에 대한 심층 분석을 수행합니다. 이 기사에서는 체계적인 비교 분석을 통해 활성화 함수의 설계 원리, 성능 평가 표준 및 가능한 향후 개발 방향을 논의하고 딥 러닝 모델의 최적화 및 설계를 위한 이론적 지침을 제공합니다.
활성화 함수는 신경망의 핵심 구성 요소로, 뉴런의 출력에 비선형 특성을 도입하여 신경망이 복잡한 비선형 매핑을 학습하고 표현할 수 있도록 합니다. 활성화 함수가 없으면 신경망의 깊이에 관계없이 본질적으로 선형 변환만 나타낼 수 있으므로 네트워크의 표현 능력이 크게 제한됩니다.
딥러닝의 급속한 발전으로 활성화 함수의 설계와 선택은 모델 성능에 영향을 미치는 중요한 요소가 되었습니다. 다양한 활성화 함수는 기울기 유동성, 계산 복잡성, 비선형성 정도 등과 같은 다양한 특성을 갖습니다. 이러한 특성은 훈련 효율성, 수렴 속도 및 신경망의 최종 성능에 직접적인 영향을 미칩니다.
이 글의 목적은 활성화 함수의 진화를 종합적으로 검토하고, 다양한 활성화 함수의 특성을 심층적으로 분석하며, 최신 딥러닝 모델에서의 적용을 탐색하는 것입니다. 우리는 다음과 같은 측면을 논의할 것입니다:
이러한 체계적인 검토 및 분석을 통해 연구자와 실무자가 딥러닝 모델 설계에서 활성화 함수를 더 잘 선택하고 사용하는 데 도움이 되는 포괄적인 참고 자료를 제공할 수 있기를 바랍니다.
시그모이드 함수는 가장 먼저 널리 사용되는 활성화 함수 중 하나이며 수학적 표현은 다음과 같습니다.
σ(x) = 1 1 + e − x 시그마(x) = frac{1}{1 + e^{-x}}σ(엑스)=1+이자형−엑스1
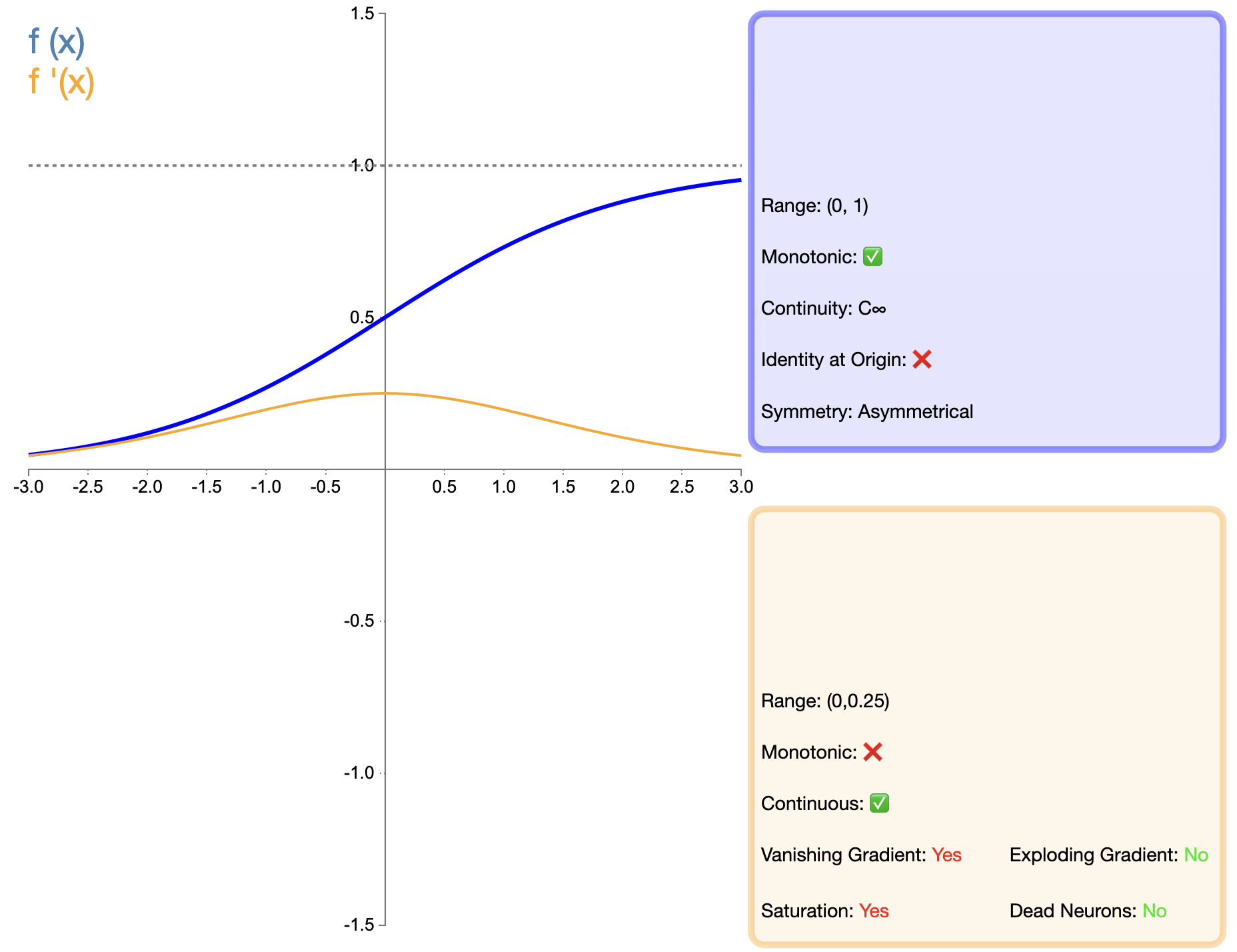
나중에 등장한 ReLU와 같은 기능과 비교할 때 Sigmoid를 딥 네트워크에 적용하는 것은 주로 Vanishing Gradient 문제로 인해 크게 제한되었습니다. 그러나 일부 특정 작업(예: 이진 분류)에서는 시그모이드가 여전히 효과적인 선택입니다.
Tanh(하이퍼볼릭 탄젠트) 함수는 Sigmoid 함수의 향상된 버전으로 간주할 수 있으며 수학적 표현은 다음과 같습니다.
tanh ( x ) = ex − e − xex + e − x tanh(x) = frac{e^x - e^{-x}}{e^x + e^{-x}}탄(엑스)=이자형엑스+이자형−엑스이자형엑스−이자형−엑스
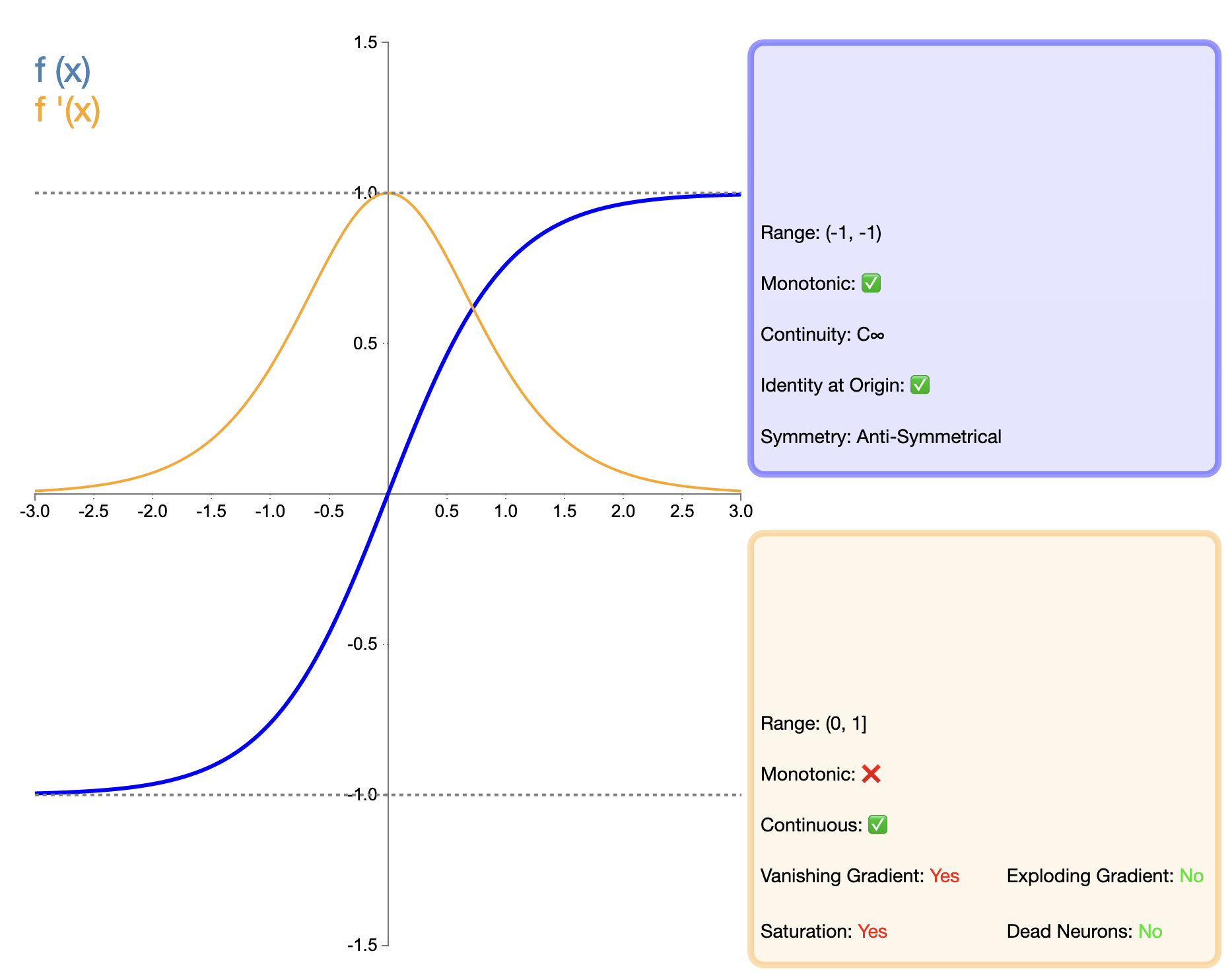
Tanh 함수는 Sigmoid 함수의 개선된 버전으로 간주될 수 있습니다. 주요 개선 사항은 출력의 0 중심화에 있습니다. 이 기능을 사용하면 특히 심층 네트워크에서 Tanh가 Sigmoid보다 더 나은 성능을 발휘할 수 있습니다. 그러나 나중에 등장한 ReLU와 같은 기능과 비교할 때 Tanh는 여전히 그래디언트 소멸 문제가 있으며 이는 매우 깊은 네트워크에서 모델 성능에 영향을 미칠 수 있습니다.
두 가지 고전적인 활성화 함수인 Sigmoid와 Tanh는 딥러닝 초기에 중요한 역할을 했으며, 이들의 특성과 한계로 인해 후속 활성화 함수의 개발도 촉진되었습니다. 많은 시나리오에서 업데이트된 활성화 기능으로 대체되었지만 특정 작업 및 네트워크 구조에서는 여전히 고유한 적용 가치를 가지고 있습니다.
ReLU 함수의 제안은 활성화 함수 개발에 있어서 중요한 이정표입니다. 수학적 표현은 간단합니다.
ReLU(x) = max(0, x) 텍스트{ReLU}(x) = max(0, x)렐루(엑스)=최대(0,엑스)
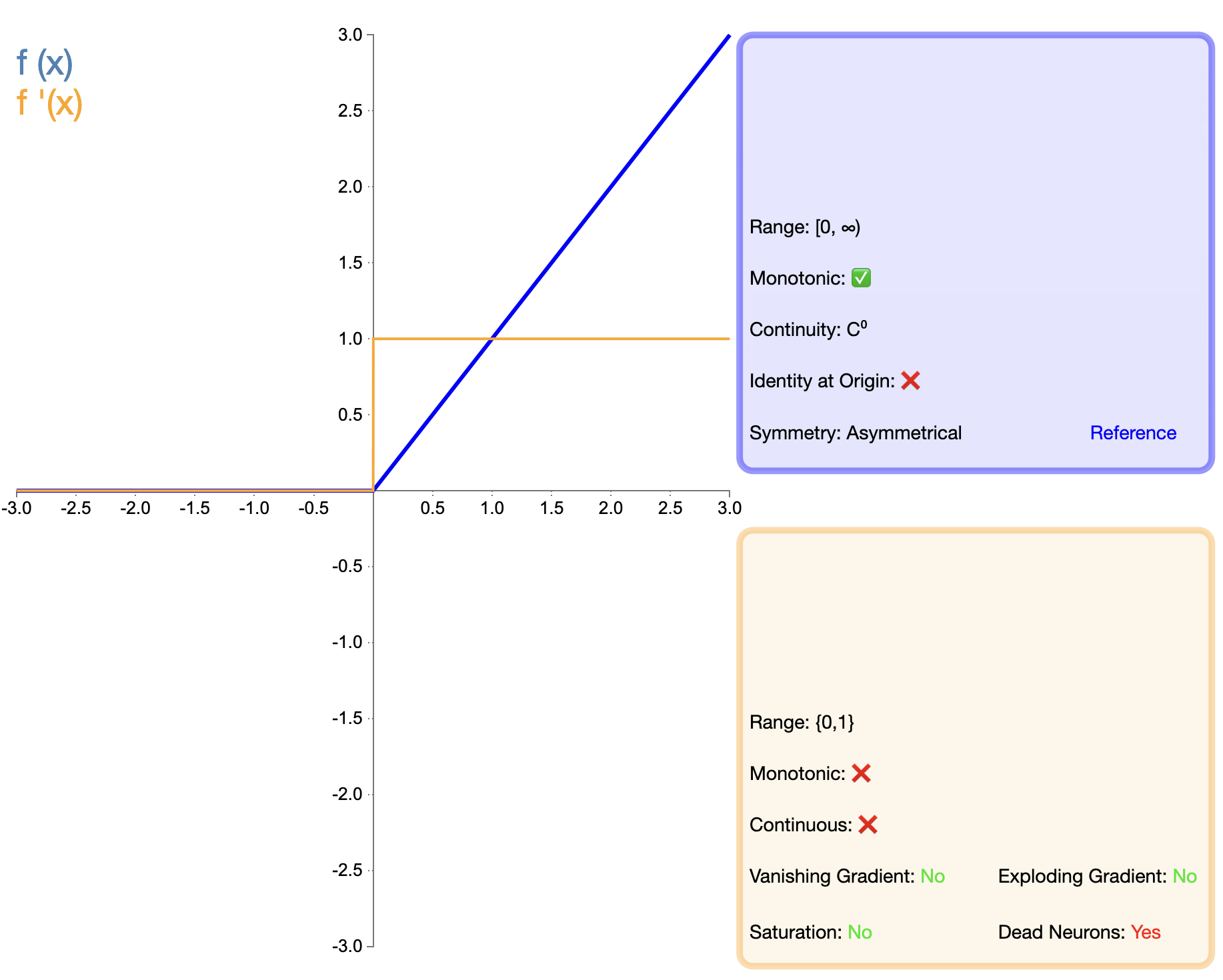
Sigmoid 및 Tanh과 비교하여 ReLU는 주로 훈련 속도 및 기울기 소멸 완화 측면에서 심층 네트워크에서 상당한 이점을 보여줍니다. 그러나 "dead ReLU" 문제로 인해 연구자들은 다양한 개선된 버전을 제안하게 되었습니다.
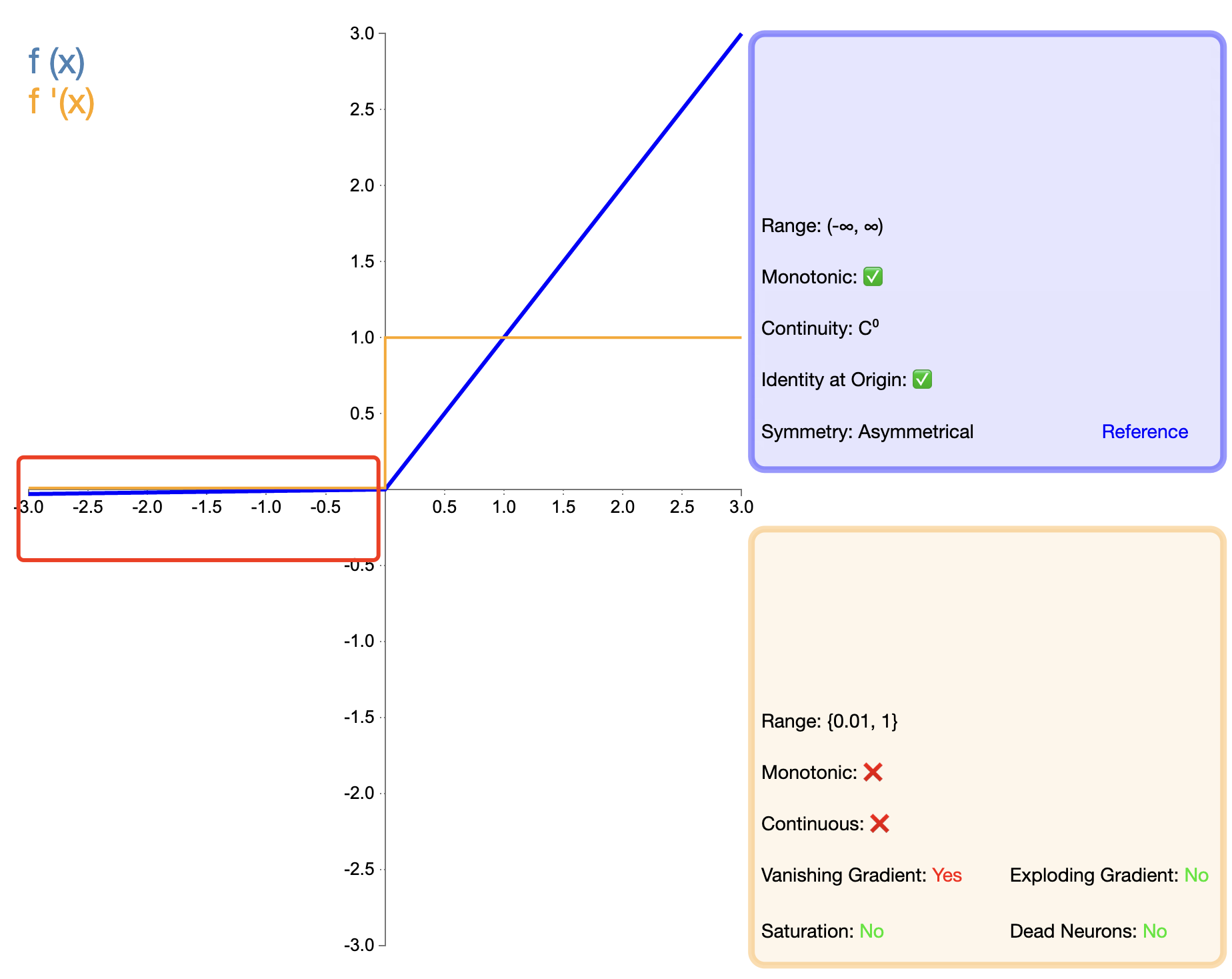
ReLU의 "죽음" 문제를 해결하기 위해 Leaky ReLU가 제안되었습니다.
누설 ReLU(x) = { x , x > 0이면 α x , x ≤ 0이면 text{누설 ReLU}(x) ={엑스,만약에엑스>0α엑스,만약에엑스≤0 누수 ReLU(엑스)={
엑스,알파엑스,만약에엑스>0만약에엑스≤0
안에, 알파 알파α 작은 양의 상수(보통 0.01)입니다.
PReLU는 음의 반축의 기울기가 학습 가능한 매개변수인 Leaky ReLU의 변형입니다.
PReLU(x) = { x , x > 0이면 α x , x ≤ 0이면 text{PReLU}(x) ={엑스,만약에엑스>0α엑스,만약에엑스≤0 프리루(엑스)={
엑스,알파엑스,만약에엑스>0만약에엑스≤0
여기 알파 알파α 역전파를 통해 학습된 매개변수입니다.
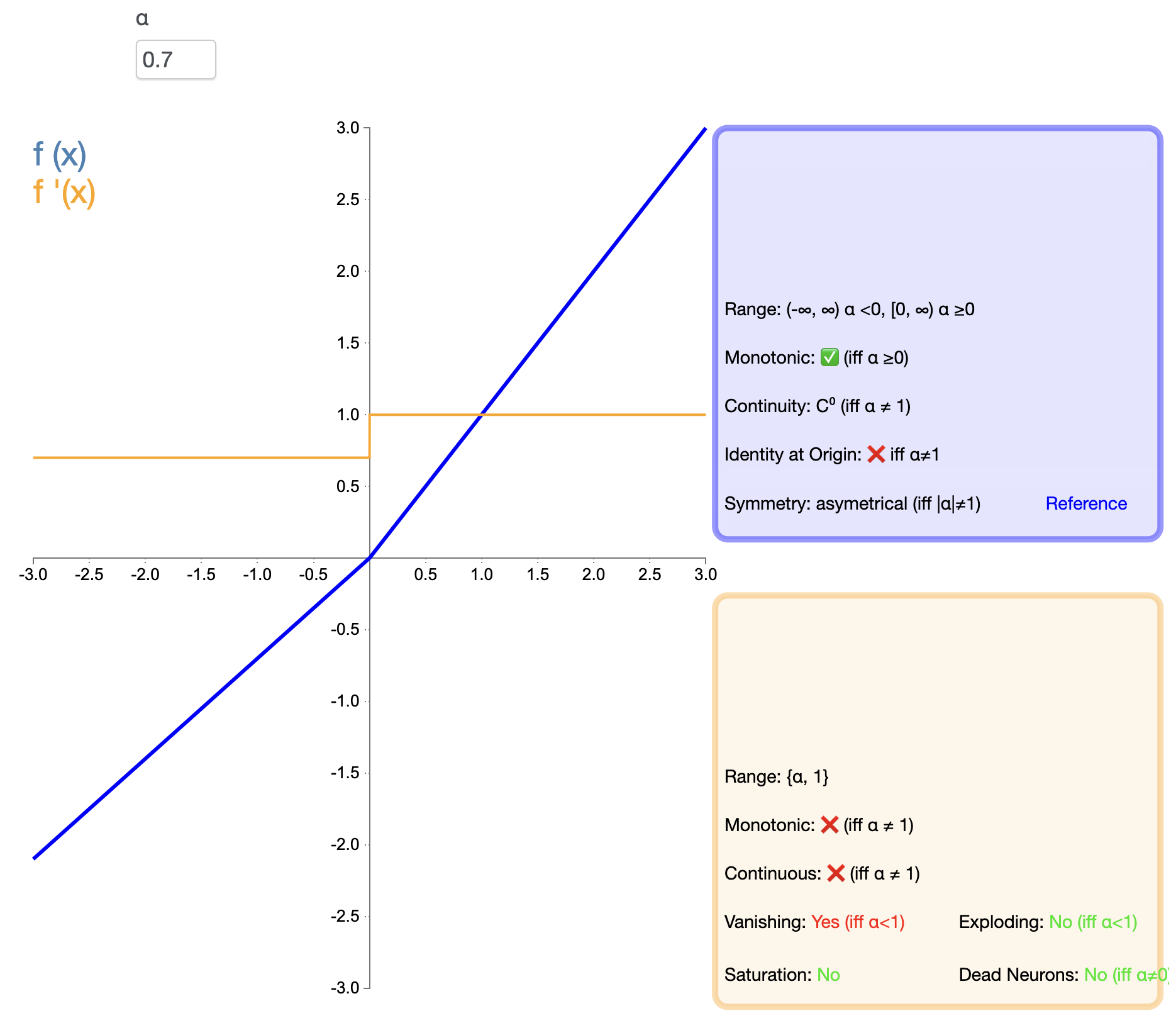
ELU는 ReLU의 장점과 음수 입력 처리를 결합하려고 시도합니다. 수학적 표현은 다음과 같습니다.
ELU(x) = { x , x > 0이면 α(ex−1) , x ≤ 0이면 text{ELU}(x) ={엑스,만약에엑스>0α(이자형엑스−1),만약에엑스≤0 엘루(엑스)=

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com