τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Αυτό το άρθρο εξετάζει διεξοδικά την ανάπτυξη των συναρτήσεων ενεργοποίησης στη βαθιά εκμάθηση, από τις πρώιμες συναρτήσεις Sigmoid και Tanh, έως τις ευρέως χρησιμοποιούμενες σειρές ReLU, έως τις πρόσφατα προτεινόμενες νέες λειτουργίες ενεργοποίησης όπως Swish, Mish και GeLU. Διενεργείται μια εις βάθος ανάλυση των μαθηματικών εκφράσεων, χαρακτηριστικών, πλεονεκτημάτων, περιορισμών και εφαρμογών διαφόρων συναρτήσεων ενεργοποίησης σε τυπικά μοντέλα. Μέσω συστηματικής συγκριτικής ανάλυσης, αυτό το άρθρο συζητά τις αρχές σχεδιασμού, τα πρότυπα αξιολόγησης απόδοσης και πιθανές μελλοντικές κατευθύνσεις ανάπτυξης των συναρτήσεων ενεργοποίησης, παρέχοντας θεωρητική καθοδήγηση για τη βελτιστοποίηση και το σχεδιασμό μοντέλων βαθιάς μάθησης.
Η συνάρτηση ενεργοποίησης είναι ένα βασικό στοιχείο στα νευρωνικά δίκτυα, το οποίο εισάγει μη γραμμικά χαρακτηριστικά στην έξοδο των νευρώνων, επιτρέποντας στα νευρωνικά δίκτυα να μαθαίνουν και να αναπαριστούν πολύπλοκες μη γραμμικές αντιστοιχίσεις. Χωρίς συνάρτηση ενεργοποίησης, ανεξάρτητα από το πόσο βαθύ είναι ένα νευρωνικό δίκτυο, μπορεί ουσιαστικά να αναπαραστήσει μόνο γραμμικούς μετασχηματισμούς, γεγονός που περιορίζει σε μεγάλο βαθμό την εκφραστική ικανότητα του δικτύου.
Με την ταχεία ανάπτυξη της βαθιάς μάθησης, ο σχεδιασμός και η επιλογή των λειτουργιών ενεργοποίησης έχουν γίνει σημαντικοί παράγοντες που επηρεάζουν την απόδοση του μοντέλου. Διαφορετικές συναρτήσεις ενεργοποίησης έχουν διαφορετικά χαρακτηριστικά, όπως ρευστότητα κλίσης, υπολογιστική πολυπλοκότητα, βαθμό μη γραμμικότητας κ.λπ. Αυτά τα χαρακτηριστικά επηρεάζουν άμεσα την αποτελεσματικότητα της εκπαίδευσης, την ταχύτητα σύγκλισης και την τελική απόδοση του νευρωνικού δικτύου.
Αυτό το άρθρο στοχεύει να εξετάσει διεξοδικά την εξέλιξη των συναρτήσεων ενεργοποίησης, να αναλύσει σε βάθος τα χαρακτηριστικά των διαφόρων συναρτήσεων ενεργοποίησης και να διερευνήσει την εφαρμογή τους σε σύγχρονα μοντέλα βαθιάς μάθησης. Θα συζητήσουμε τις ακόλουθες πτυχές:
Μέσω αυτής της συστηματικής ανασκόπησης και ανάλυσης, ελπίζουμε να παρέχουμε μια ολοκληρωμένη αναφορά σε ερευνητές και επαγγελματίες για να τους βοηθήσουμε να επιλέξουν και να χρησιμοποιήσουν καλύτερα τις λειτουργίες ενεργοποίησης στο σχεδιασμό μοντέλων βαθιάς μάθησης.
Η συνάρτηση Sigmoid είναι μια από τις πρώτες ευρέως χρησιμοποιούμενες συναρτήσεις ενεργοποίησης και η μαθηματική έκφρασή της είναι:
σ ( x ) = 1 1 + e − x sigma(x) = frac{1}{1 + e^{-x}}σ(Χ)=1+μι−Χ1
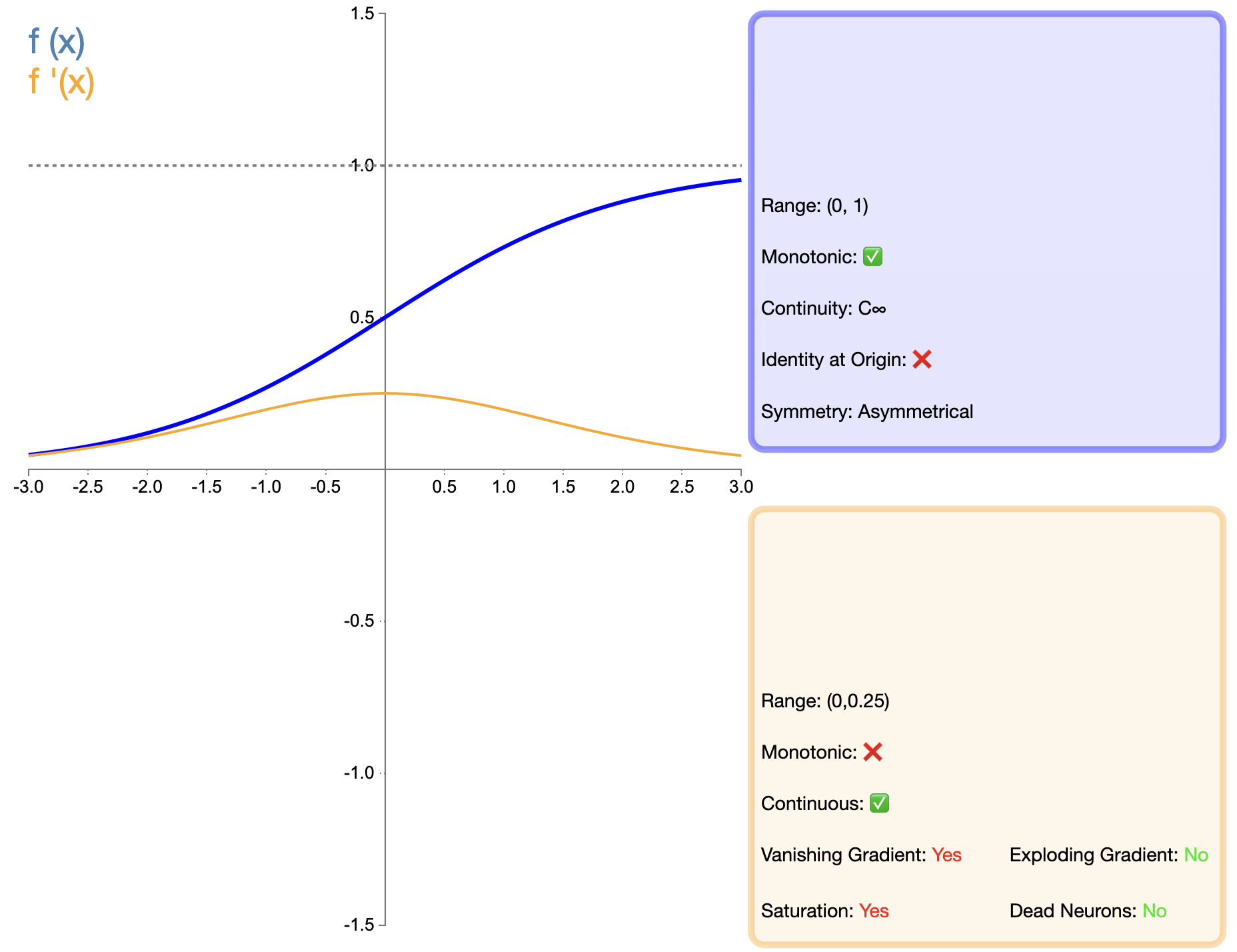
Σε σύγκριση με συναρτήσεις όπως το ReLU που εμφανίστηκαν αργότερα, η εφαρμογή του Sigmoid σε βαθιά δίκτυα έχει περιοριστεί πολύ, κυρίως λόγω του προβλήματος της εξαφάνισης της κλίσης. Ωστόσο, σε ορισμένες συγκεκριμένες εργασίες (όπως η δυαδική ταξινόμηση), το σιγμοειδές εξακολουθεί να είναι μια αποτελεσματική επιλογή.
Η συνάρτηση Tanh (υπερβολική εφαπτομένη) μπορεί να θεωρηθεί ως μια βελτιωμένη έκδοση της συνάρτησης Sigmoid και η μαθηματική της έκφρασή είναι:
tanh ( x ) = ex − e − xex + e − x tanh(x) = frac{e^x - e^{-x}}{e^x + e^{-x}}tanh(Χ)=μιΧ+μι−ΧμιΧ−μι−Χ
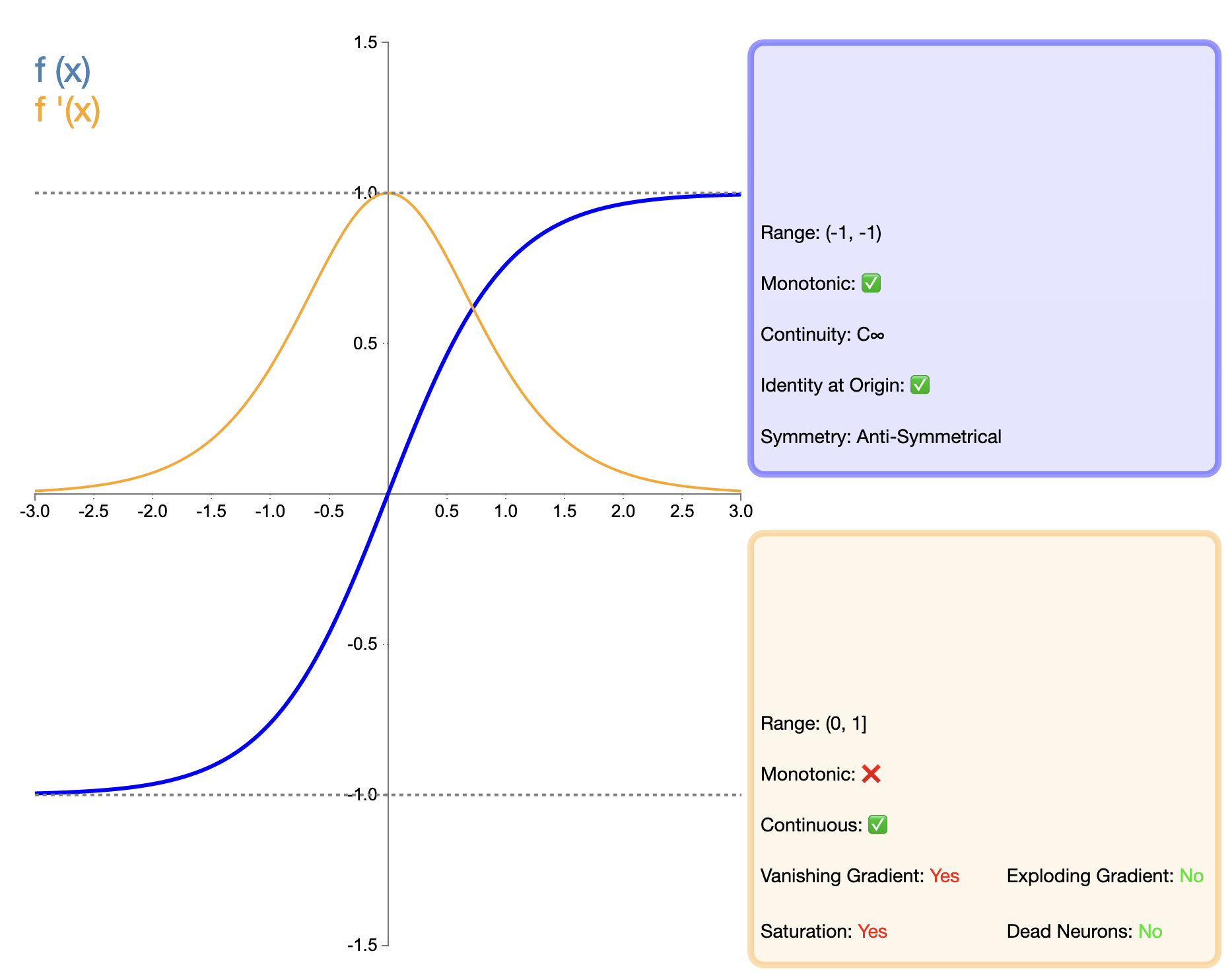
Η συνάρτηση Tanh μπορεί να θεωρηθεί ως μια βελτιωμένη έκδοση της συνάρτησης Sigmoid Η κύρια βελτίωση βρίσκεται στο μηδενικό κεντράρισμα της εξόδου. Αυτή η δυνατότητα κάνει το Tanh να αποδίδει καλύτερα από το Sigmoid σε πολλές περιπτώσεις, ειδικά σε βαθιά δίκτυα. Ωστόσο, σε σύγκριση με λειτουργίες όπως το ReLU που εμφανίστηκαν αργότερα, το Tanh εξακολουθεί να έχει το πρόβλημα της εξαφάνισης της κλίσης, το οποίο μπορεί να επηρεάσει την απόδοση του μοντέλου σε πολύ βαθιά δίκτυα.
Οι δύο κλασικές λειτουργίες ενεργοποίησης, το Sigmoid και το Tanh, έπαιξαν σημαντικό ρόλο στις πρώτες μέρες της βαθιάς μάθησης και τα χαρακτηριστικά και οι περιορισμοί τους προώθησαν επίσης την ανάπτυξη επακόλουθων λειτουργιών ενεργοποίησης. Αν και έχουν αντικατασταθεί από ενημερωμένες λειτουργίες ενεργοποίησης σε πολλά σενάρια, εξακολουθούν να έχουν τη μοναδική τους αξία εφαρμογής σε συγκεκριμένες εργασίες και δομές δικτύου.
Η πρόταση της λειτουργίας ReLU είναι ένα σημαντικό ορόσημο στην ανάπτυξη των λειτουργιών ενεργοποίησης. Η μαθηματική του έκφραση είναι απλή:
ReLU ( x ) = max ( 0 , x ) text{ReLU}(x) = max(0, x)ReLU(Χ)=Μέγιστη(0,Χ)
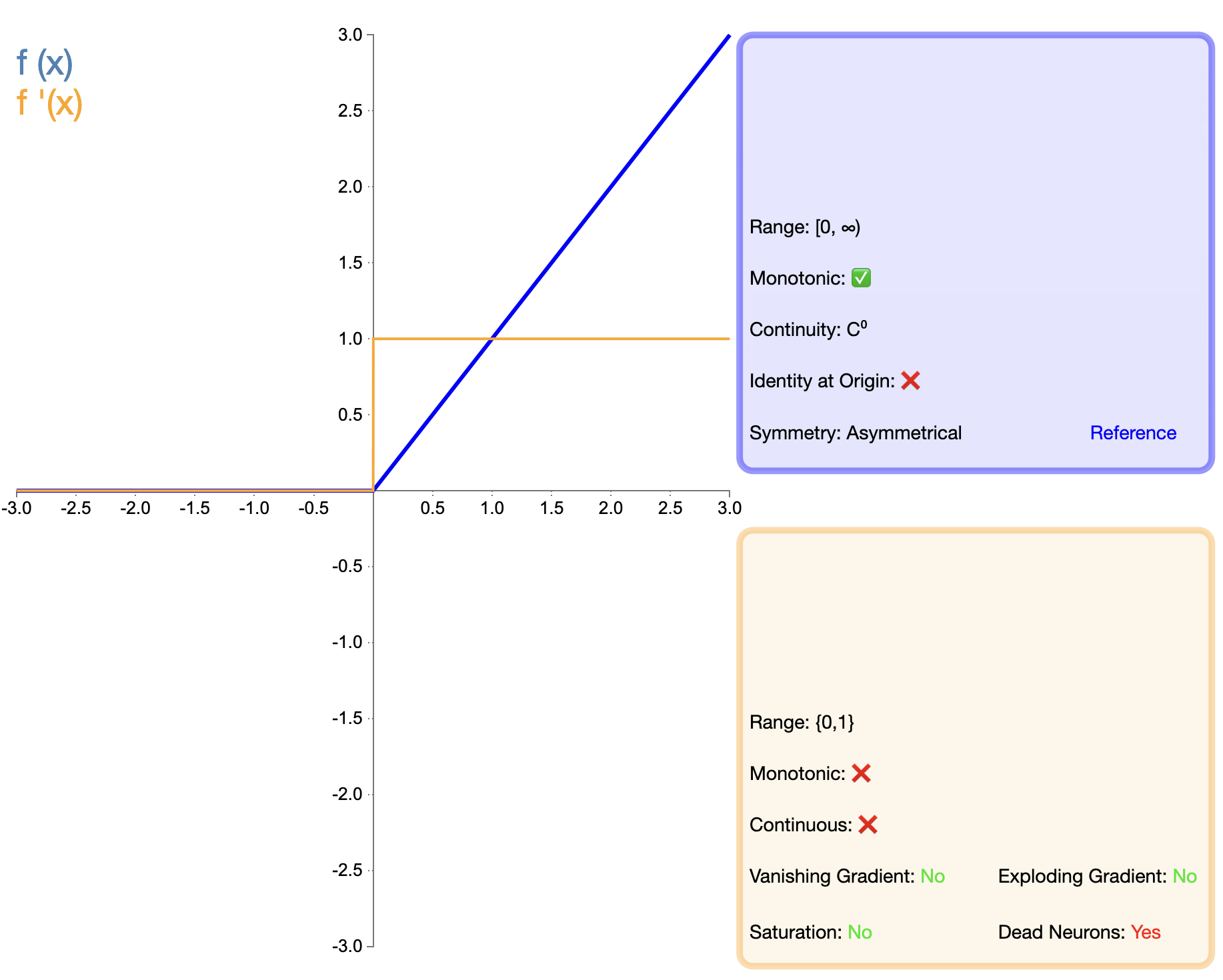
Σε σύγκριση με το Sigmoid και το Tanh, το ReLU παρουσιάζει σημαντικά πλεονεκτήματα στα βαθιά δίκτυα, κυρίως όσον αφορά την ταχύτητα εκπαίδευσης και τον μετριασμό της εξαφάνισης της κλίσης. Ωστόσο, το πρόβλημα του «νεκρού ReLU» ώθησε τους ερευνητές να προτείνουν διάφορες βελτιωμένες εκδόσεις.
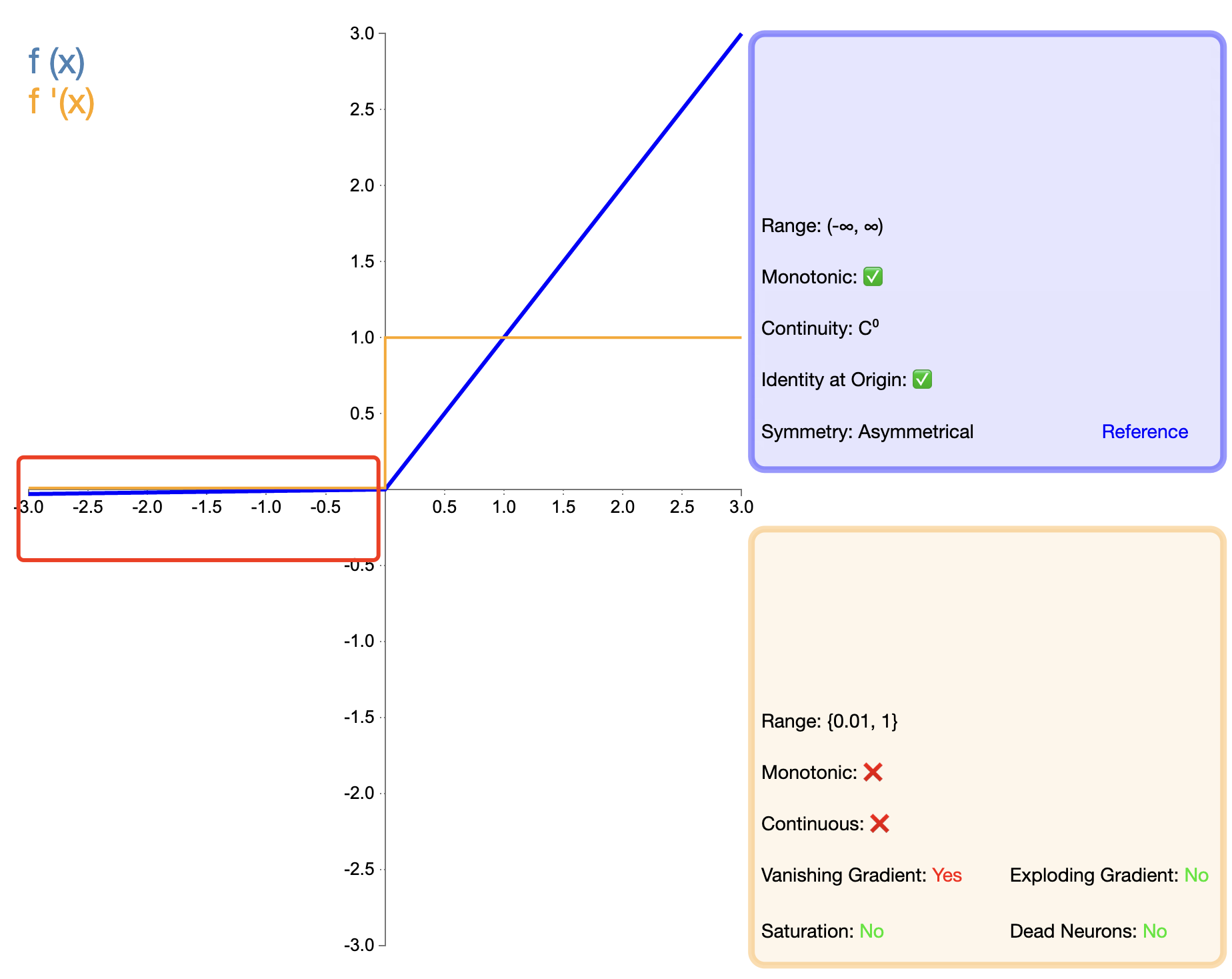
Προκειμένου να λυθεί το πρόβλημα «θανάτου» του ReLU, προτάθηκε το Leaky ReLU:
Διαρροή ReLU ( x ) = { x , αν x > 0 α x , εάν x ≤ 0 κείμενο{Leaky ReLU}(x) ={Χ,ανΧ>0αΧ,ανΧ≤0 Διαρροή ReLU(Χ)={
Χ,αx,ανΧ>0ανΧ≤0
σε, α άλφαα είναι μια μικρή θετική σταθερά, συνήθως 0,01.
Το PReLU είναι μια παραλλαγή του Leaky ReLU, όπου η κλίση του αρνητικού ημιάξονα είναι μια μαθησιακή παράμετρος:
PReLU ( x ) = { x , αν x > 0 α x , αν x ≤ 0 κείμενο{PReLU}(x) ={Χ,ανΧ>0αΧ,ανΧ≤0 PReLU(Χ)={
Χ,αx,ανΧ>0ανΧ≤0
εδώ α άλφαα είναι παράμετροι που μαθαίνονται μέσω της αντίστροφης διάδοσης.
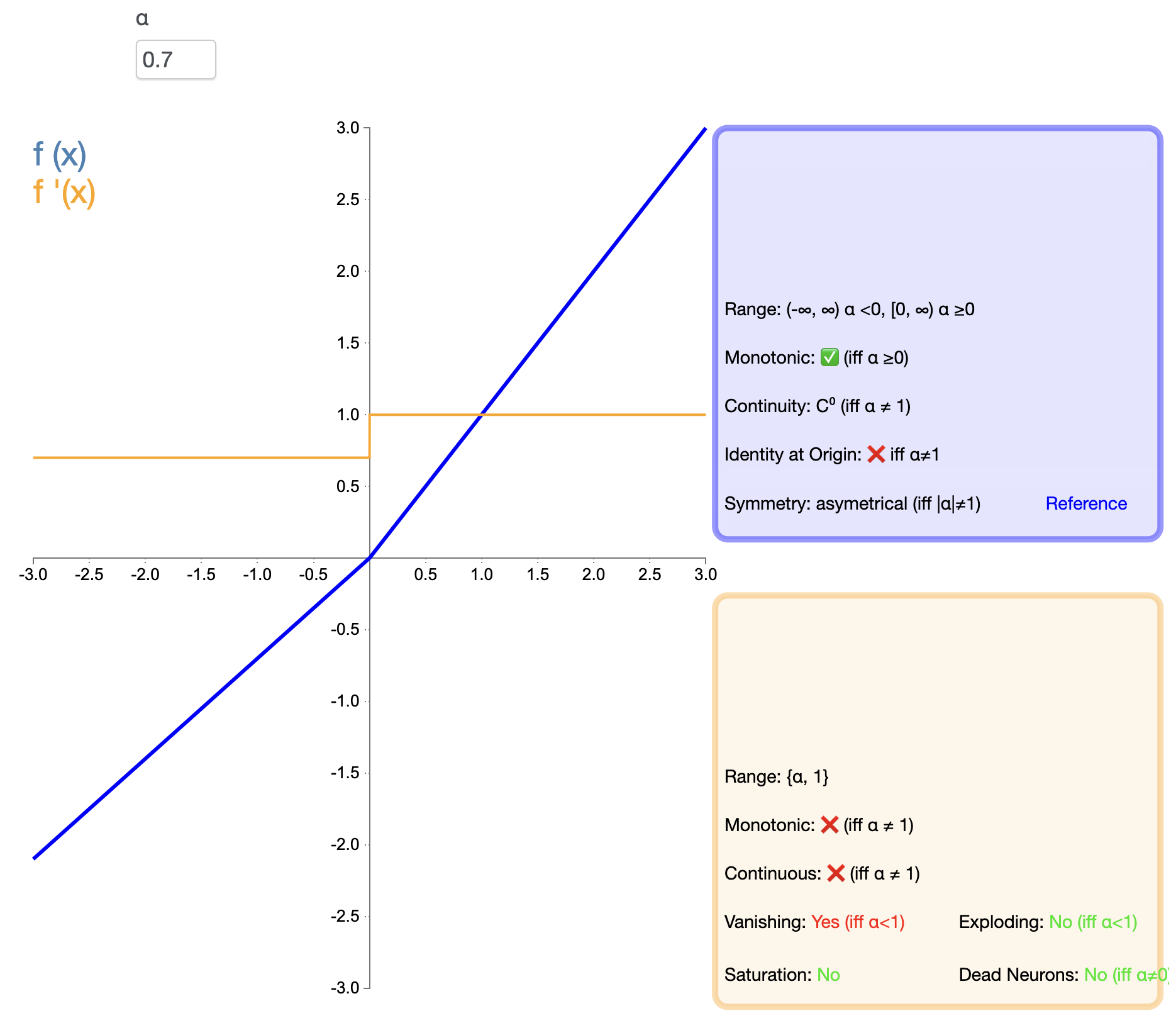
Η ELU επιχειρεί να συνδυάσει τα πλεονεκτήματα του ReLU και την επεξεργασία των αρνητικών εισροών Η μαθηματική έκφρασή του είναι:
ELU ( x ) = { x , if x > 0 α ( ex − 1 ) , if x ≤ 0 text{ELU}(x) ={Χ,ανΧ>0α(μιΧ−1),ανΧ≤0 ELU(Χ)=

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα τεκμηρίωσης προγραμματιστή για να μοιραστείτε τα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]