プライベートな連絡先の最初の情報
送料メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
この記事では、初期の Sigmoid 関数や Tanh 関数から、広く使用されている ReLU シリーズ、そして最近提案された Swish、Mish、GeLU などの新しい活性化関数に至るまで、深層学習における活性化関数の開発を包括的にレビューします。典型的なモデルにおけるさまざまな活性化関数の数式、特性、利点、制限、および応用についての詳細な分析が行われます。この記事では、体系的な比較分析を通じて、活性化関数の設計原則、パフォーマンス評価基準、将来の開発の可能性について議論し、深層学習モデルの最適化と設計のための理論的なガイダンスを提供します。
活性化関数はニューラル ネットワークの重要なコンポーネントであり、ニューロンの出力に非線形特性を導入し、ニューラル ネットワークが複雑な非線形マッピングを学習して表現できるようにします。活性化関数がなければ、ニューラル ネットワークがどれほど深くても、基本的には線形変換しか表現できず、ネットワークの表現能力が大幅に制限されます。
深層学習の急速な発展に伴い、活性化関数の設計と選択がモデルのパフォーマンスに影響を与える重要な要素となっています。活性化関数が異なれば、勾配の流動性、計算の複雑さ、非線形性の程度など、異なる特性があります。これらの特性は、ニューラル ネットワークのトレーニング効率、収束速度、および最終的なパフォーマンスに直接影響します。
この記事の目的は、活性化関数の進化を包括的にレビューし、さまざまな活性化関数の特性を深く分析し、最新の深層学習モデルでのそれらのアプリケーションを探ることです。以下の点について説明します。
この系統的なレビューと分析を通じて、研究者や実践者が深層学習モデルの設計において活性化関数をより適切に選択して使用できるようにするための包括的な参考資料を提供したいと考えています。
シグモイド関数は、最も初期に広く使用された活性化関数の 1 つであり、その数式は次のとおりです。
σ ( x ) = 1 1 + e − x シグマ(x) = frac{1}{1 + e^{-x}}σ(バツ)=1+e−バツ1
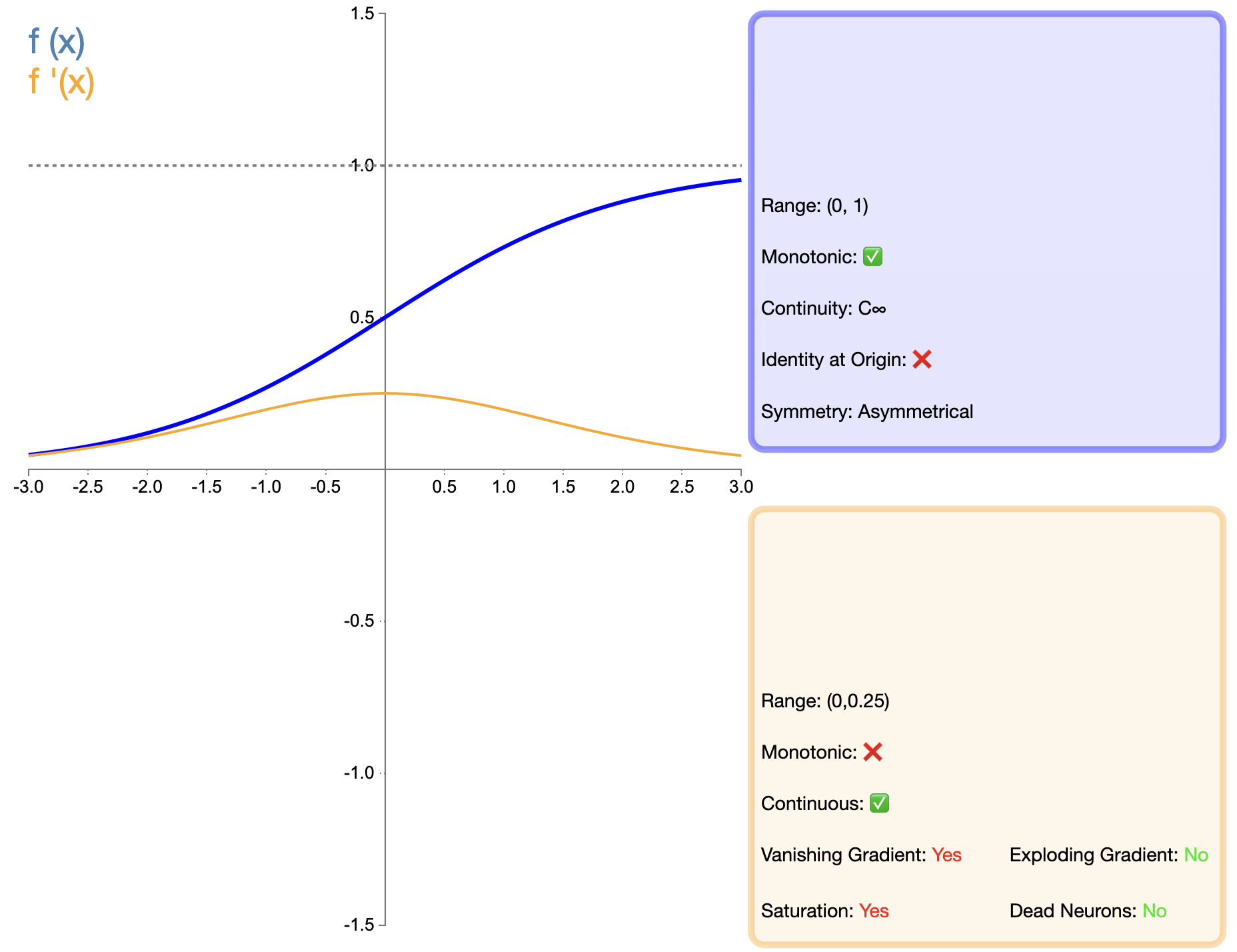
後に登場した ReLU などの関数と比較すると、主に勾配消失問題により、深層ネットワークでのシグモイドの適用は大きく制限されてきました。ただし、一部の特定のタスク (バイナリ分類など) では、シグモイドが依然として効果的な選択肢です。
Tanh (双曲線正接) 関数は、シグモイド関数の改良版とみなすことができ、その数式は次のとおりです。
tanh ( x ) = ex − e − xex + e − x tanh(x) = frac{e^x - e^{-x}}{e^x + e^{-x}}タン(バツ)=eバツ+e−バツeバツ−e−バツ
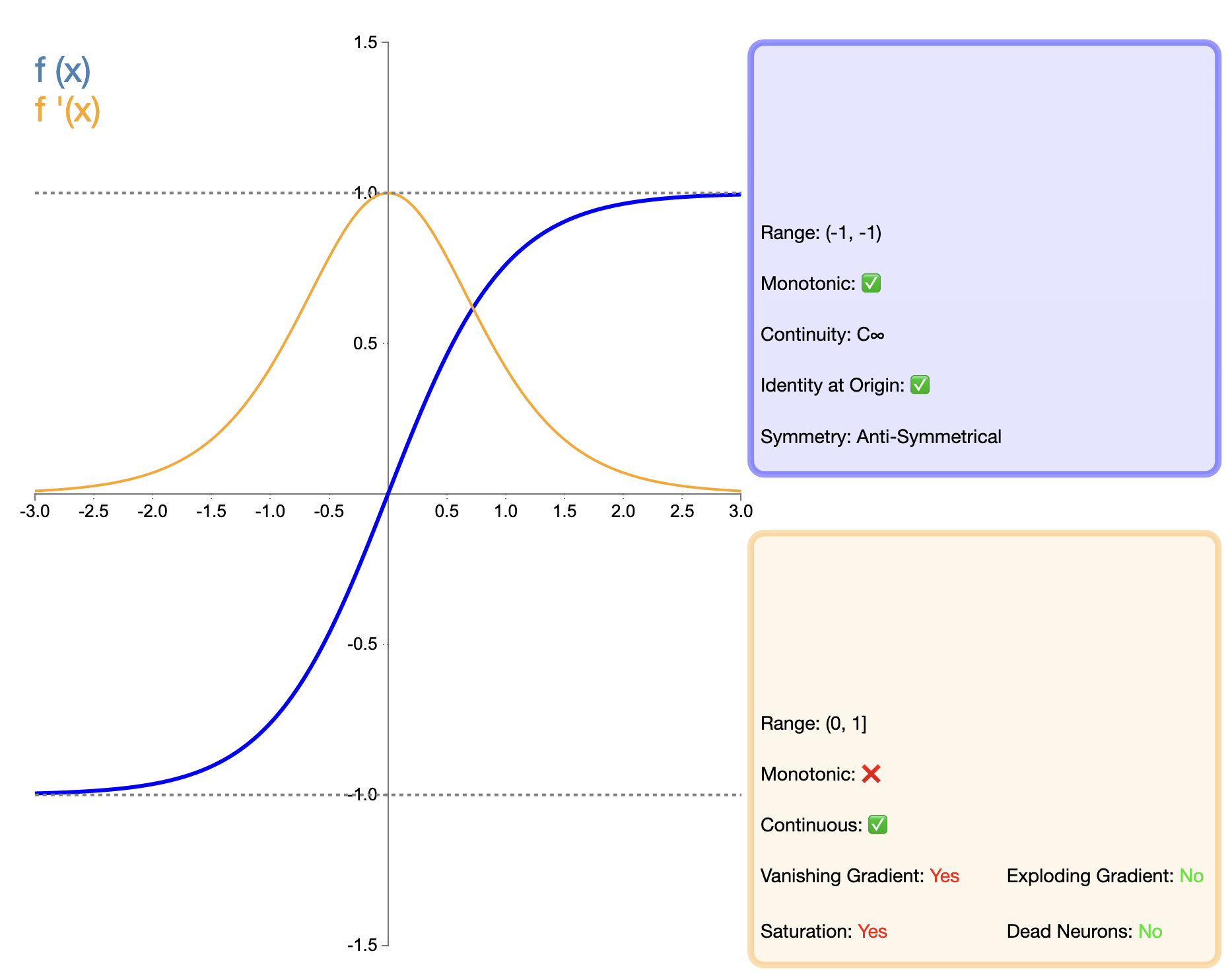
Tanh 関数は、シグモイド関数の改良版とみなすことができます。主な改良点は、出力のゼロセンタリングにあります。この機能により、Tanh は多くの状況、特にディープ ネットワークで Sigmoid よりも優れたパフォーマンスを発揮します。ただし、後に登場した ReLU などの関数と比較すると、Tanh には依然として勾配消失の問題があり、非常に深いネットワークではモデルのパフォーマンスに影響を与える可能性があります。
Sigmoid と Tanh という 2 つの古典的な活性化関数は、深層学習の初期に重要な役割を果たしました。また、その特性と制限により、その後の活性化関数の開発も促進されました。これらは多くのシナリオで更新されたアクティベーション関数に置き換えられていますが、特定のタスクやネットワーク構造では依然として独自のアプリケーション価値を持っています。
ReLU 関数の提案は、活性化関数の開発における重要なマイルストーンです。その数式は次のように簡単です。
ReLU ( x ) = max ( 0 , x ) テキスト{ReLU}(x) = max(0, x)再LU(バツ)=最大(0,バツ)
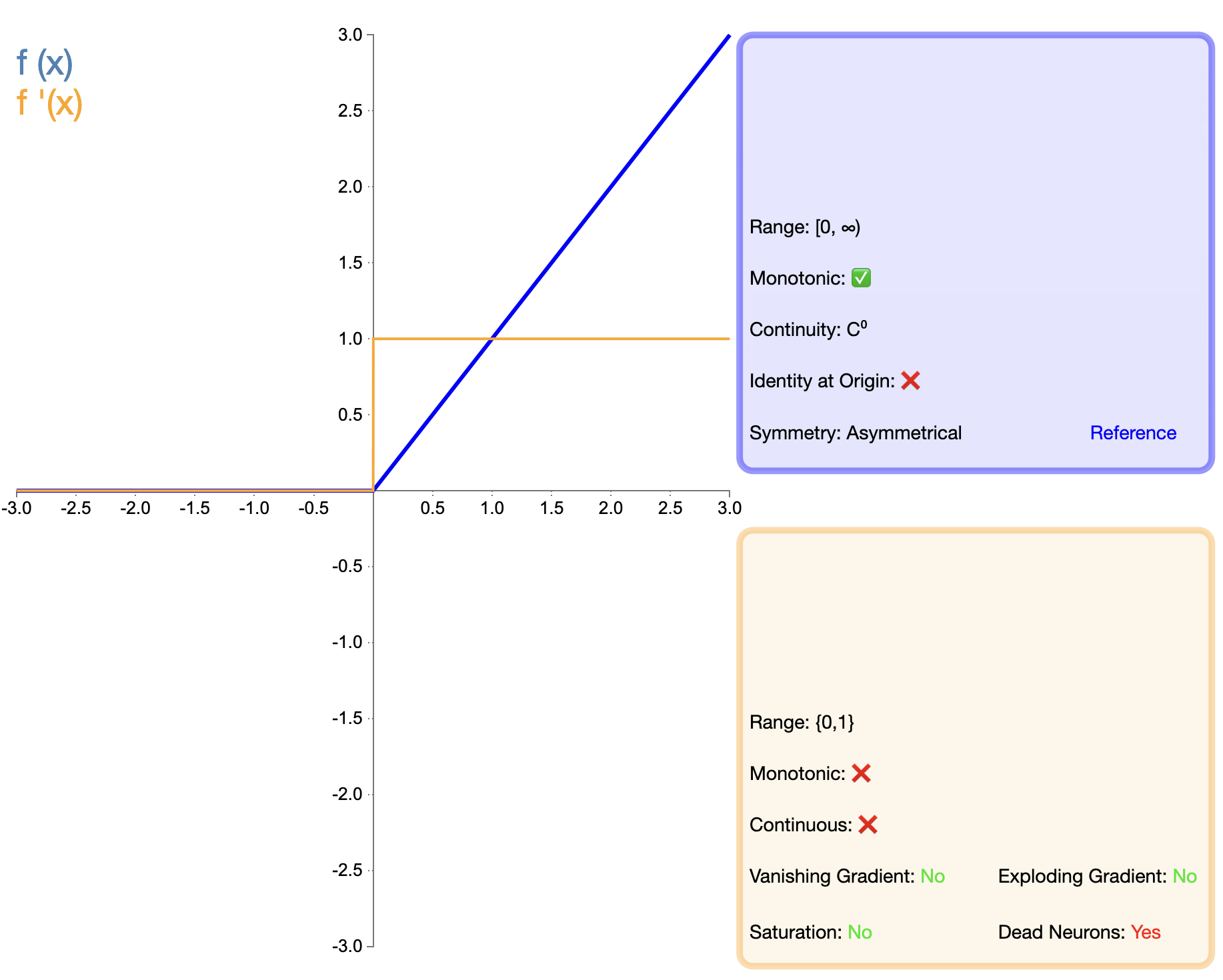
Sigmoid や Tanh と比較して、ReLU は深いネットワークにおいて、主にトレーニング速度と勾配消失の軽減の点で大きな利点を示します。しかし、「dead ReLU」問題により、研究者はさまざまな改良版を提案するようになりました。
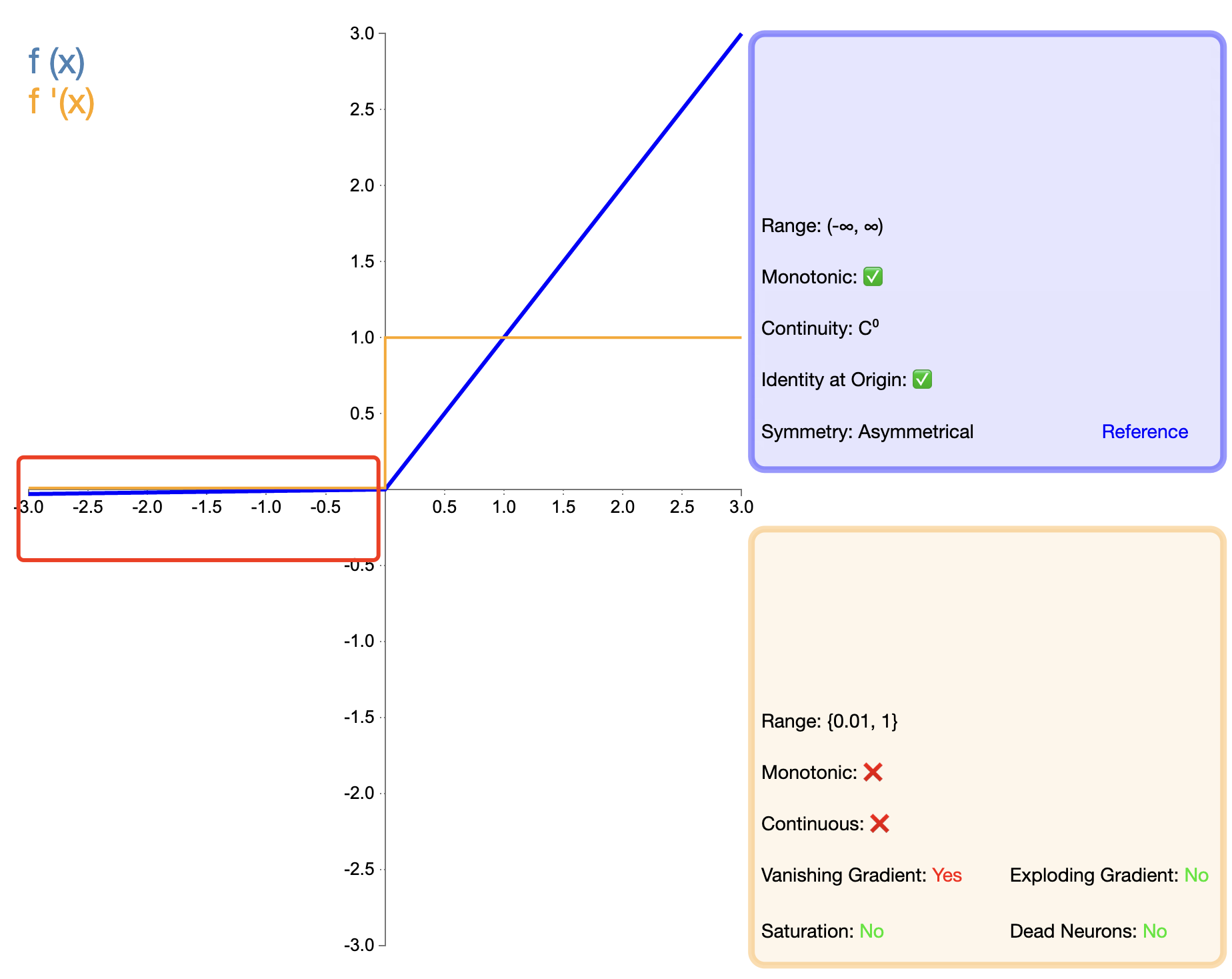
ReLU の「死」問題を解決するために、Leaky ReLU が提案されました。
リーキーReLU ( x ) = { x 、 x > 0の場合 α x 、 x ≤ 0の場合 text{リーキーReLU}(x) ={バツ,もしバツ>0αバツ,もしバツ≤0 リーキーReLU(バツ)={
バツ,αx,もしバツ>0もしバツ≤0
で、 α アルファα は小さな正の定数で、通常は 0.01 です。
PReLU は Leaky ReLU の変形であり、負の半軸の傾きが学習可能なパラメータです。
PReLU ( x ) = { x 、 x > 0 の場合 α x 、 x ≤ 0 の場合 text{PReLU}(x) ={バツ,もしバツ>0αバツ,もしバツ≤0 プレル(バツ)={
バツ,αx,もしバツ>0もしバツ≤0
ここ α アルファα バックプロパゲーションを通じて学習されたパラメータです。
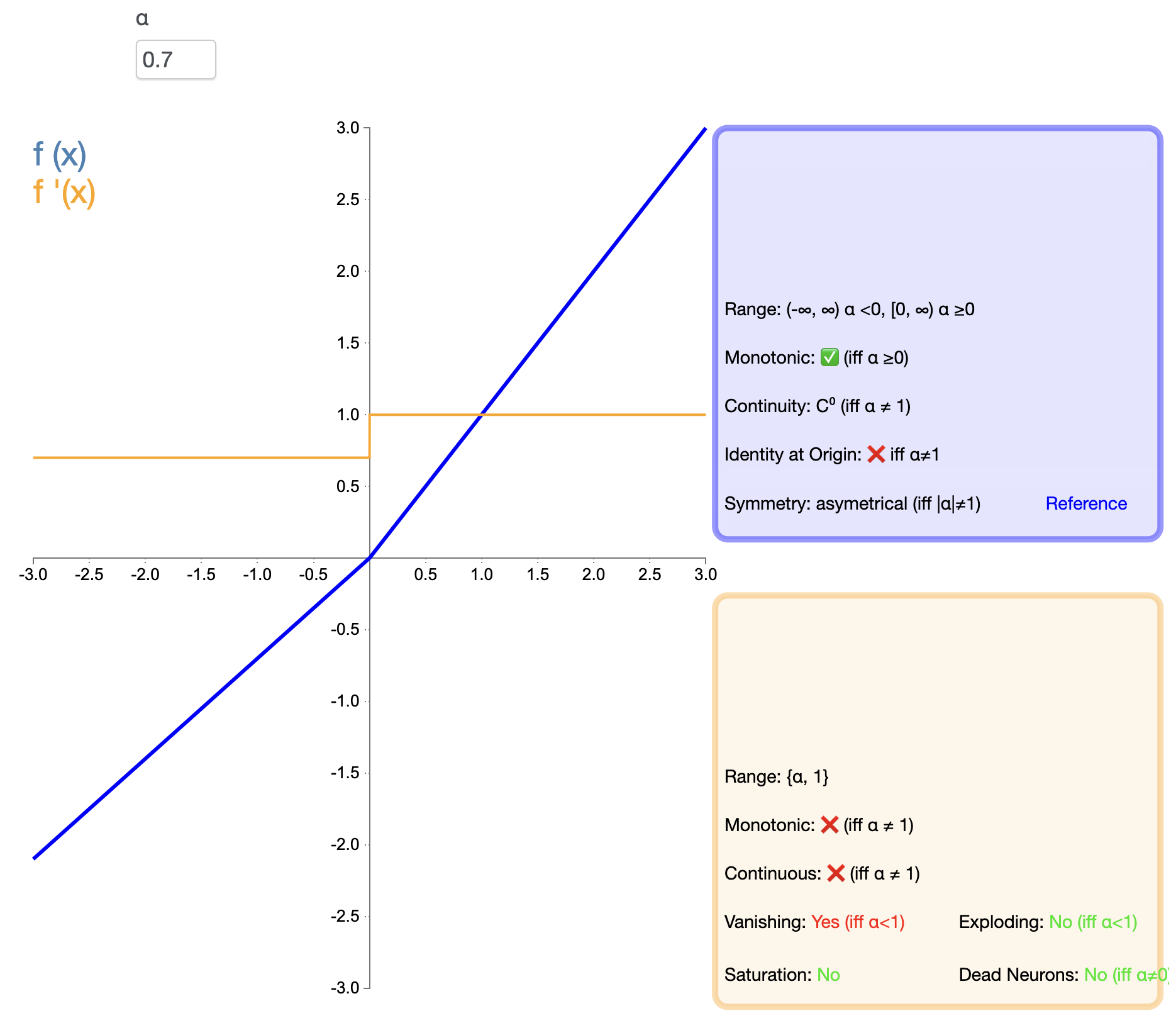
ELU は、ReLU の利点と負の入力の処理を組み合わせようとしています。その数式は次のとおりです。
ELU ( x ) = { x 、 x > 0の場合 α ( ex − 1 ) 、 x ≤ 0の場合 text{ELU}(x) ={バツ,もしバツ>0α(eバツ−1),もしバツ≤0 エル(バツ)=

彼は 30 年以上テクノロジーの研究に専念しており、Java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

送料メール: