Mi información de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Este artículo revisa exhaustivamente el desarrollo de funciones de activación en el aprendizaje profundo, desde las primeras funciones Sigmoide y Tanh, hasta la serie ReLU ampliamente utilizada y las nuevas funciones de activación propuestas recientemente como Swish, Mish y GeLU. Se realiza un análisis en profundidad de las expresiones matemáticas, características, ventajas, limitaciones y aplicaciones de diversas funciones de activación en modelos típicos. A través de un análisis comparativo sistemático, este artículo analiza los principios de diseño, los estándares de evaluación del desempeño y las posibles direcciones de desarrollo futuro de las funciones de activación, proporcionando orientación teórica para la optimización y el diseño de modelos de aprendizaje profundo.
La función de activación es un componente clave en las redes neuronales, que introduce características no lineales en la salida de las neuronas, lo que permite que las redes neuronales aprendan y representen mapeos no lineales complejos. Sin una función de activación, no importa cuán profunda sea una red neuronal, esencialmente solo puede representar transformaciones lineales, lo que limita en gran medida la capacidad expresiva de la red.
Con el rápido desarrollo del aprendizaje profundo, el diseño y la selección de funciones de activación se han convertido en factores importantes que afectan el rendimiento del modelo. Las diferentes funciones de activación tienen diferentes características, como fluidez del gradiente, complejidad computacional, grado de no linealidad, etc. Estas características afectan directamente la eficiencia del entrenamiento, la velocidad de convergencia y el rendimiento final de la red neuronal.
Este artículo tiene como objetivo revisar exhaustivamente la evolución de las funciones de activación, analizar en profundidad las características de varias funciones de activación y explorar su aplicación en los modelos modernos de aprendizaje profundo. Discutiremos los siguientes aspectos:
A través de esta revisión y análisis sistemáticos, esperamos proporcionar una referencia integral para investigadores y profesionales para ayudarlos a seleccionar y utilizar mejor las funciones de activación en el diseño de modelos de aprendizaje profundo.
La función sigmoidea es una de las primeras funciones de activación más utilizadas y su expresión matemática es:
σ ( x ) = 1 1 + e − x sigma(x) = frac{1}{1 + e^{-x}}σ(X)=1+mi−X1
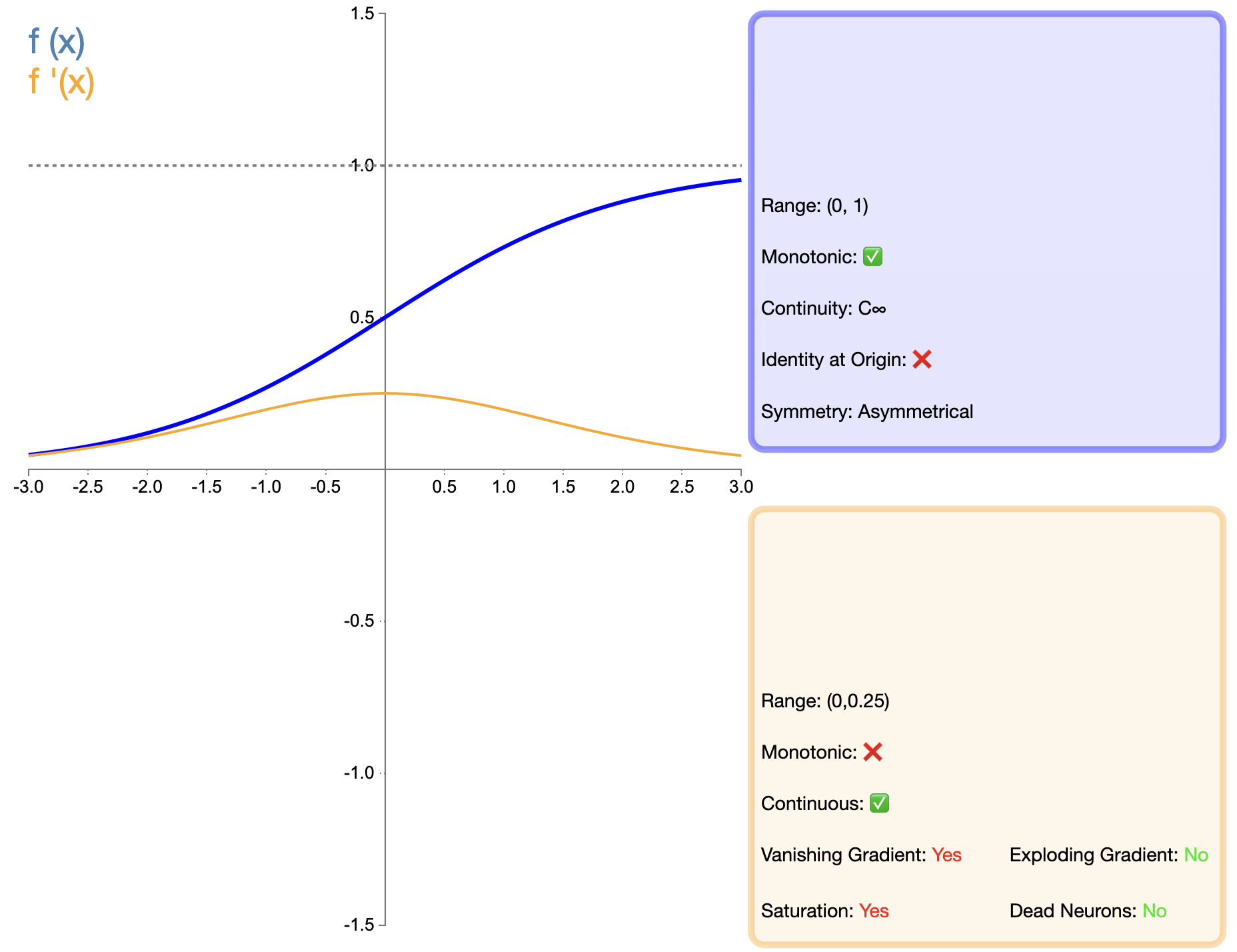
En comparación con funciones como ReLU que aparecieron más tarde, la aplicación de Sigmoid en redes profundas ha sido muy limitada, principalmente debido a su problema de gradiente que desaparece. Sin embargo, en algunas tareas específicas (como la clasificación binaria), sigmoide sigue siendo una opción eficaz.
La función Tanh (tangente hiperbólica) puede considerarse como una versión mejorada de la función Sigmoidea, y su expresión matemática es:
tanh ( x ) = ex − e − xex + e − x tanh(x) = frac{e^x - e^{-x}}{e^x + e^{-x}}Tan(X)=miX+mi−XmiX−mi−X
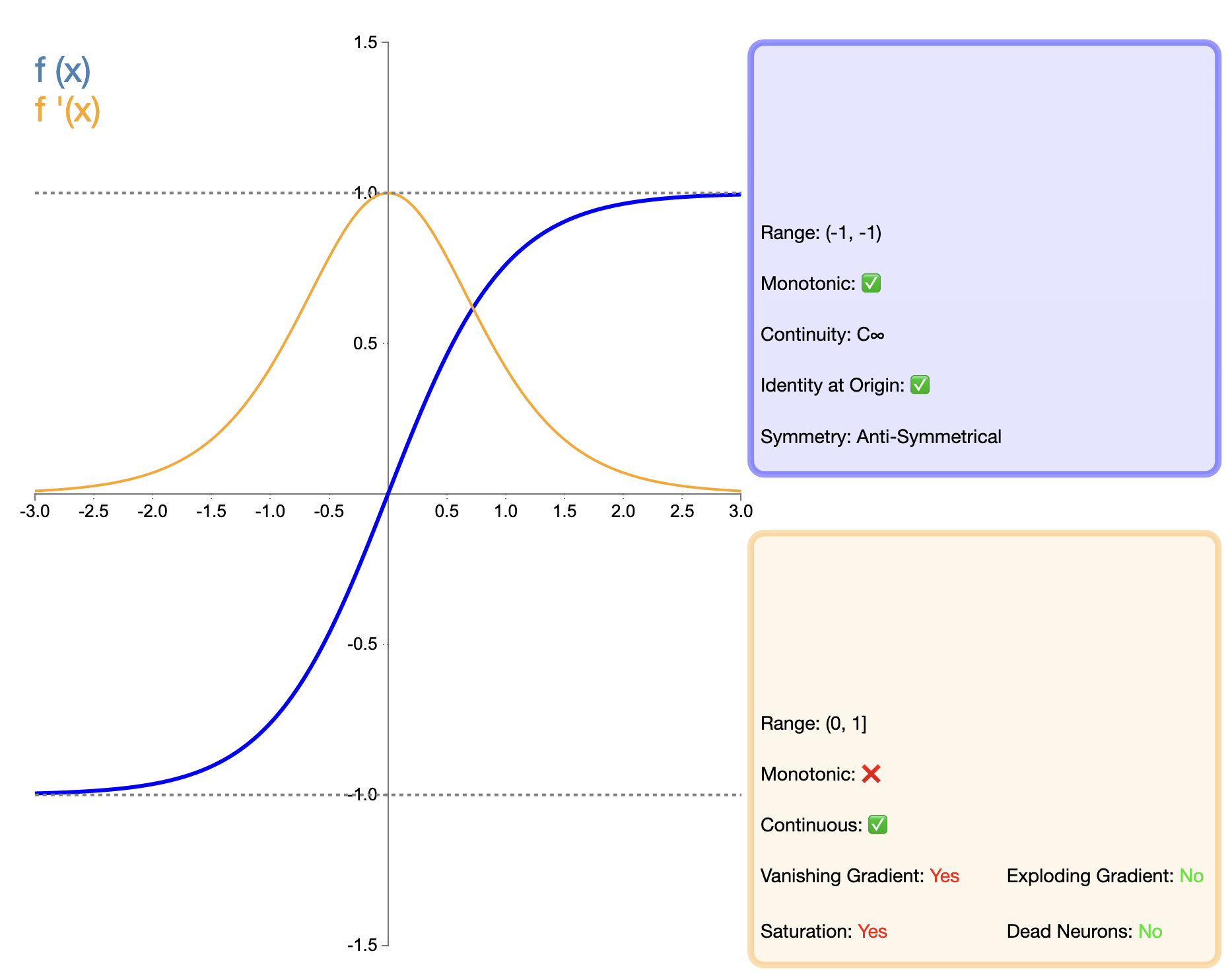
La función Tanh puede considerarse como una versión mejorada de la función Sigmoide. La principal mejora radica en el centrado en cero de la salida. Esta característica hace que Tanh funcione mejor que Sigmoid en muchas situaciones, especialmente en redes profundas. Sin embargo, en comparación con funciones como ReLU que aparecieron más tarde, Tanh todavía tiene el problema de la desaparición del gradiente, lo que puede afectar el rendimiento del modelo en redes muy profundas.
Las dos funciones de activación clásicas, Sigmoide y Tanh, jugaron un papel importante en los primeros días del aprendizaje profundo, y sus características y limitaciones también promovieron el desarrollo de funciones de activación posteriores. Aunque han sido reemplazadas por funciones de activación actualizadas en muchos escenarios, todavía tienen su valor de aplicación único en tareas y estructuras de red específicas.
La propuesta de la función ReLU es un hito importante en el desarrollo de funciones de activación. Su expresión matemática es simple:
ReLU ( x ) = máx ( 0 , x ) texto{ReLU}(x) = máx(0, x)ReLU(X)=máximo(0,X)
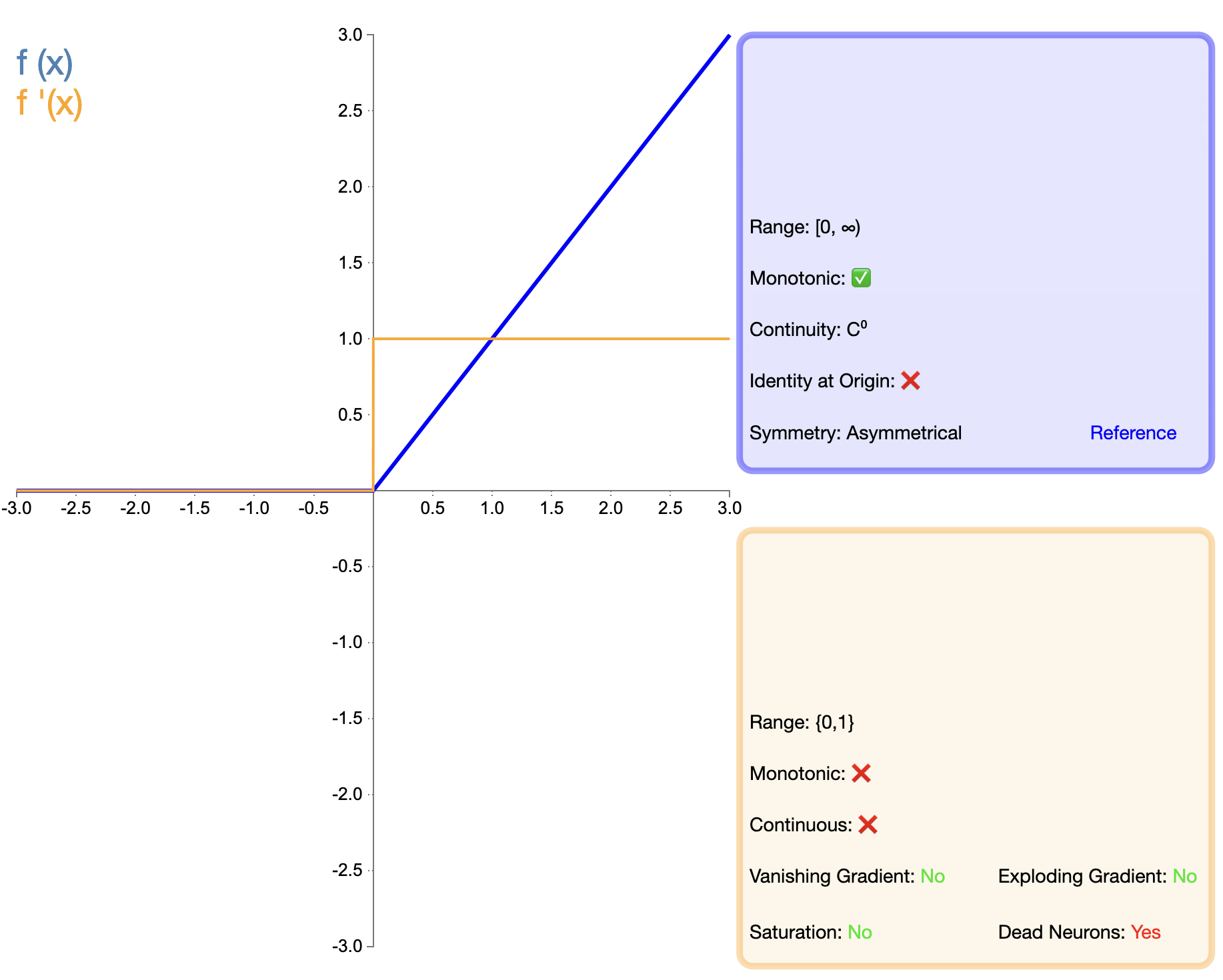
En comparación con Sigmoid y Tanh, ReLU muestra ventajas significativas en redes profundas, principalmente en términos de velocidad de entrenamiento y mitigación de la desaparición de gradientes. Sin embargo, el problema del "ReLU muerto" ha llevado a los investigadores a proponer varias versiones mejoradas.
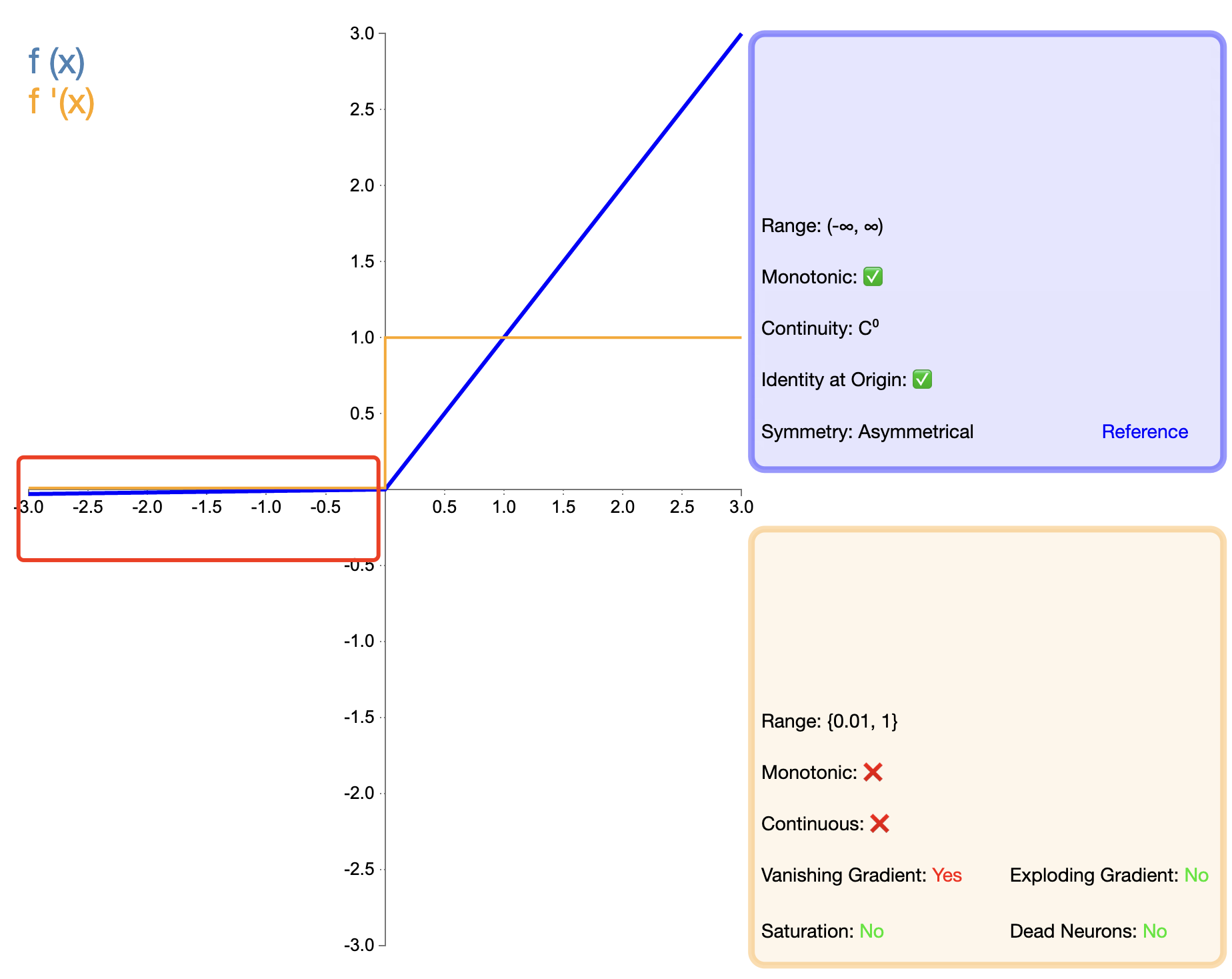
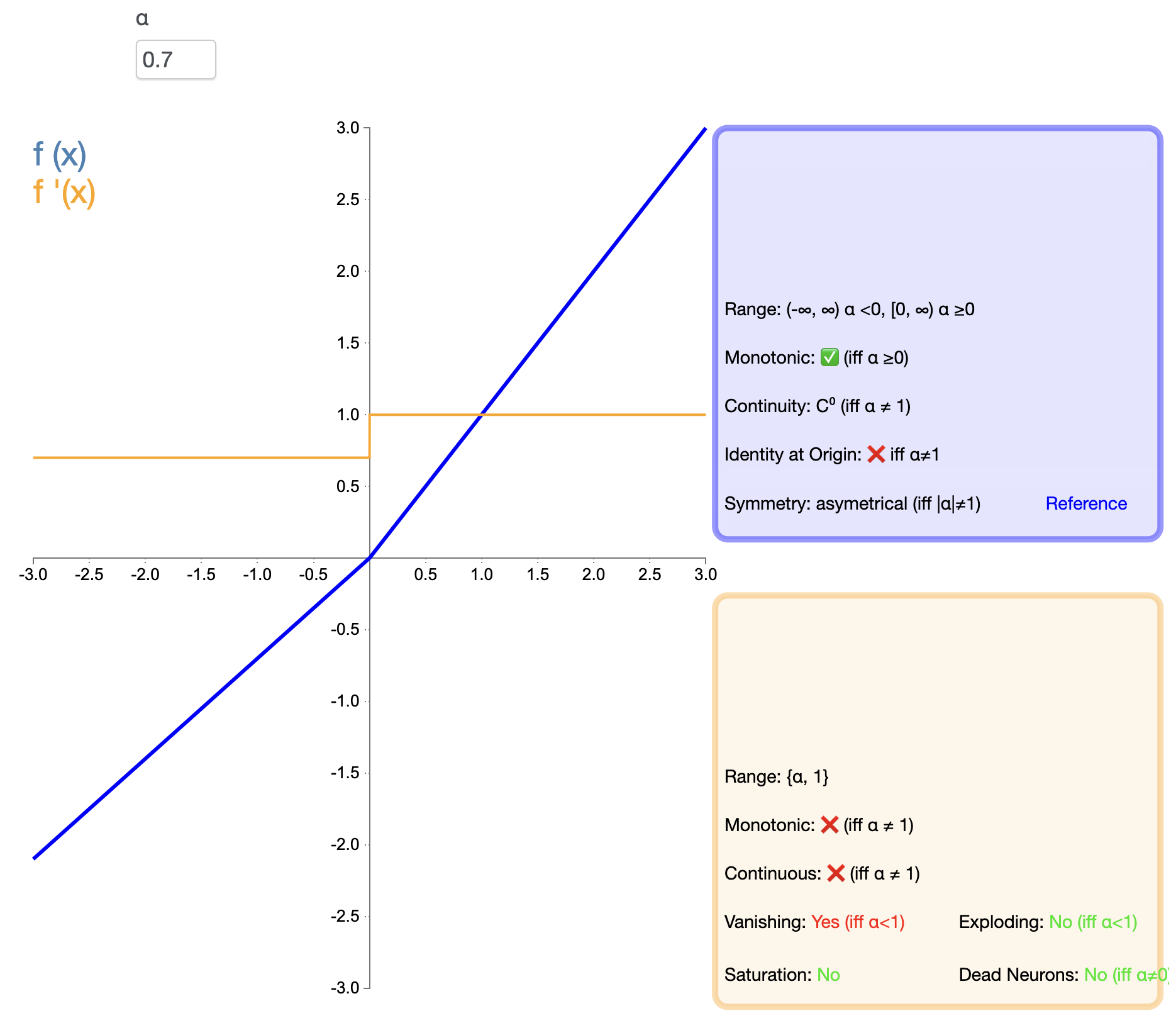
Para resolver el problema de la "muerte" de ReLU, se propuso Leaky ReLU:
Leaky ReLU ( x ) = { x , si x > 0 α x , si x ≤ 0 text{Leaky ReLU}(x) ={X,siX>0αX,siX≤0 ReLU con fugas(X)={
X,αx,siX>0siX≤0
en, alfaα es una pequeña constante positiva, normalmente 0,01.
PReLU es una variante de Leaky ReLU, donde la pendiente del semieje negativo es un parámetro que se puede aprender:
PReLU ( x ) = { x , si x > 0 α x , si x ≤ 0 text{PReLU}(x) ={X,siX>0αX,siX≤0 Preludio(X)={
X,αx,siX>0siX≤0
aquí alfaα son parámetros aprendidos mediante retropropagación.
ELU intenta combinar las ventajas de ReLU y el procesamiento de entradas negativas. Su expresión matemática es:
ELU ( x ) = { x , si x > 0 α ( ex − 1 ) , si x ≤ 0 text{ELU}(x) ={X,siX>0α(miX−1),siX≤0 ELU(X)=

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]