2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
This article comprehensively reviews the development of activation functions in deep learning, from the early Sigmoid and Tanh functions to the widely used ReLU series, and then to the recently proposed new activation functions such as Swish, Mish and GeLU. The mathematical expressions, characteristics, advantages, limitations and applications of various activation functions in typical models are deeply analyzed. Through systematic comparative analysis, this article explores the design principles, performance evaluation criteria and possible future development directions of activation functions, providing theoretical guidance for the optimization and design of deep learning models.
The activation function is a key component in the neural network. It introduces nonlinear characteristics at the output of the neuron, enabling the neural network to learn and represent complex nonlinear mappings. Without the activation function, no matter how deep the neural network is, it can only represent linear transformations in essence, which greatly limits the network's expressive power.
With the rapid development of deep learning, the design and selection of activation functions have become an important factor affecting model performance. Different activation functions have different characteristics, such as gradient fluidity, computational complexity, degree of nonlinearity, etc. These characteristics directly affect the training efficiency, convergence speed and final performance of the neural network.
This article aims to comprehensively review the evolution of activation functions, deeply analyze the characteristics of various activation functions, and explore their applications in modern deep learning models. We will discuss the following aspects:
Through this systematic review and analysis, we hope to provide a comprehensive reference for researchers and practitioners to help them better choose and use activation functions in deep learning model design.
The Sigmoid function is one of the earliest widely used activation functions, and its mathematical expression is:
σ ( x ) = 1 1 + e − x sigma(x) = frac{1}{1 + e^{-x}} σ(x)=1+e−x1
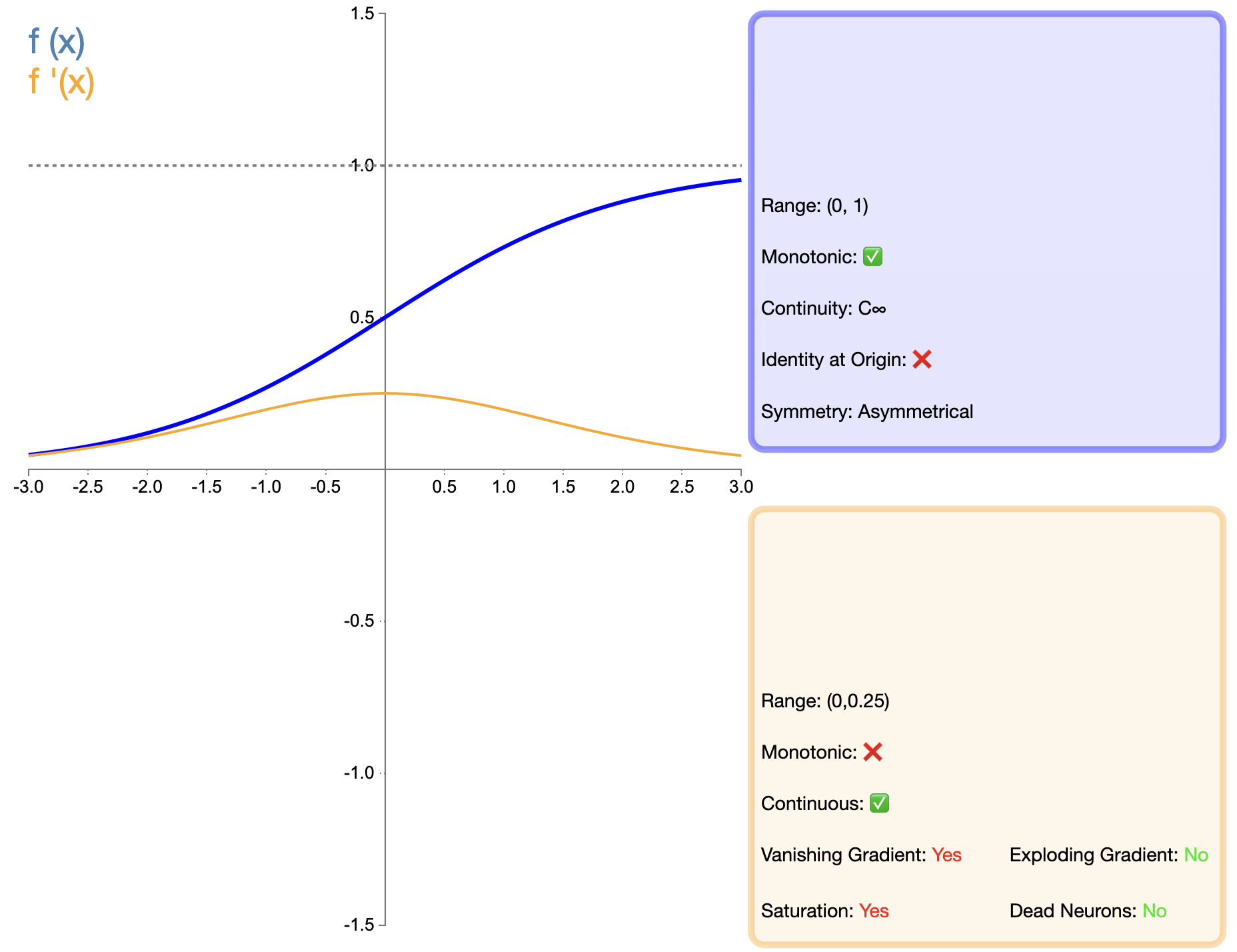
Compared with the later functions such as ReLU, the application of Sigmoid in deep networks is greatly limited, mainly because of its gradient vanishing problem. However, in some specific tasks (such as binary classification), Sigmoid is still an effective choice.
The Tanh (hyperbolic tangent) function can be regarded as an improved version of the Sigmoid function, and its mathematical expression is:
tanh ( x ) = e x − e − x e x + e − x tanh(x) = frac{e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=ex+e−xex−e−x
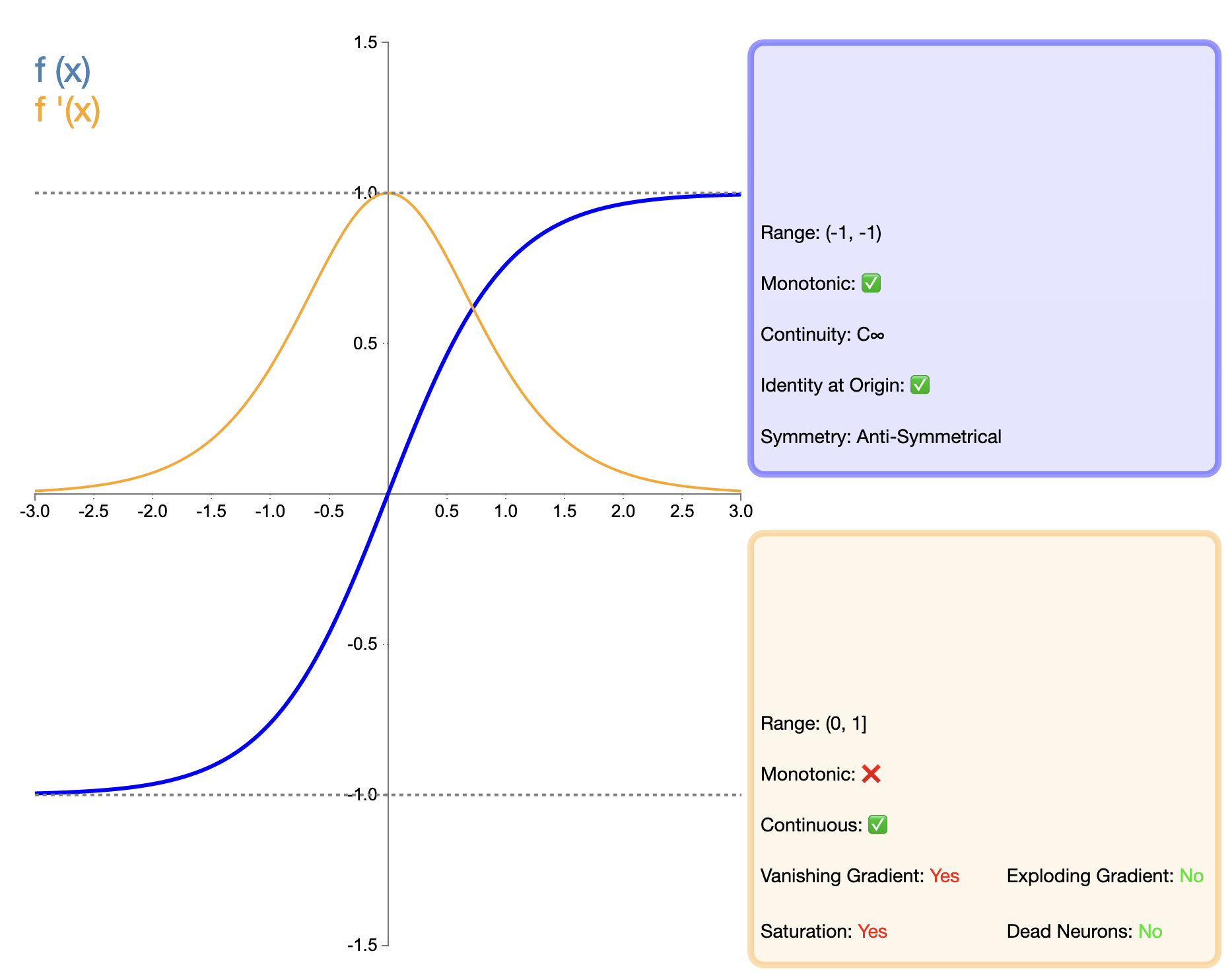
The Tanh function can be seen as an improved version of the Sigmoid function, with the main improvement being the zero-centering of the output. This feature makes Tanh perform better than Sigmoid in many cases, especially in deep networks. However, compared to later functions such as ReLU, Tanh still has the problem of gradient vanishing, which may affect the performance of the model in very deep networks.
Sigmoid and Tanh, two classic activation functions, played an important role in the early days of deep learning. Their characteristics and limitations also promoted the development of subsequent activation functions. Although they have been replaced by newer activation functions in many scenarios, they still have their unique application value in specific tasks and network structures.
The introduction of the ReLU function is an important milestone in the development of activation functions. Its mathematical expression is simple:
ReLU ( x ) = max ( 0 , x ) text{ReLU}(x) = max(0, x) ReLU(x)=max(0,x)
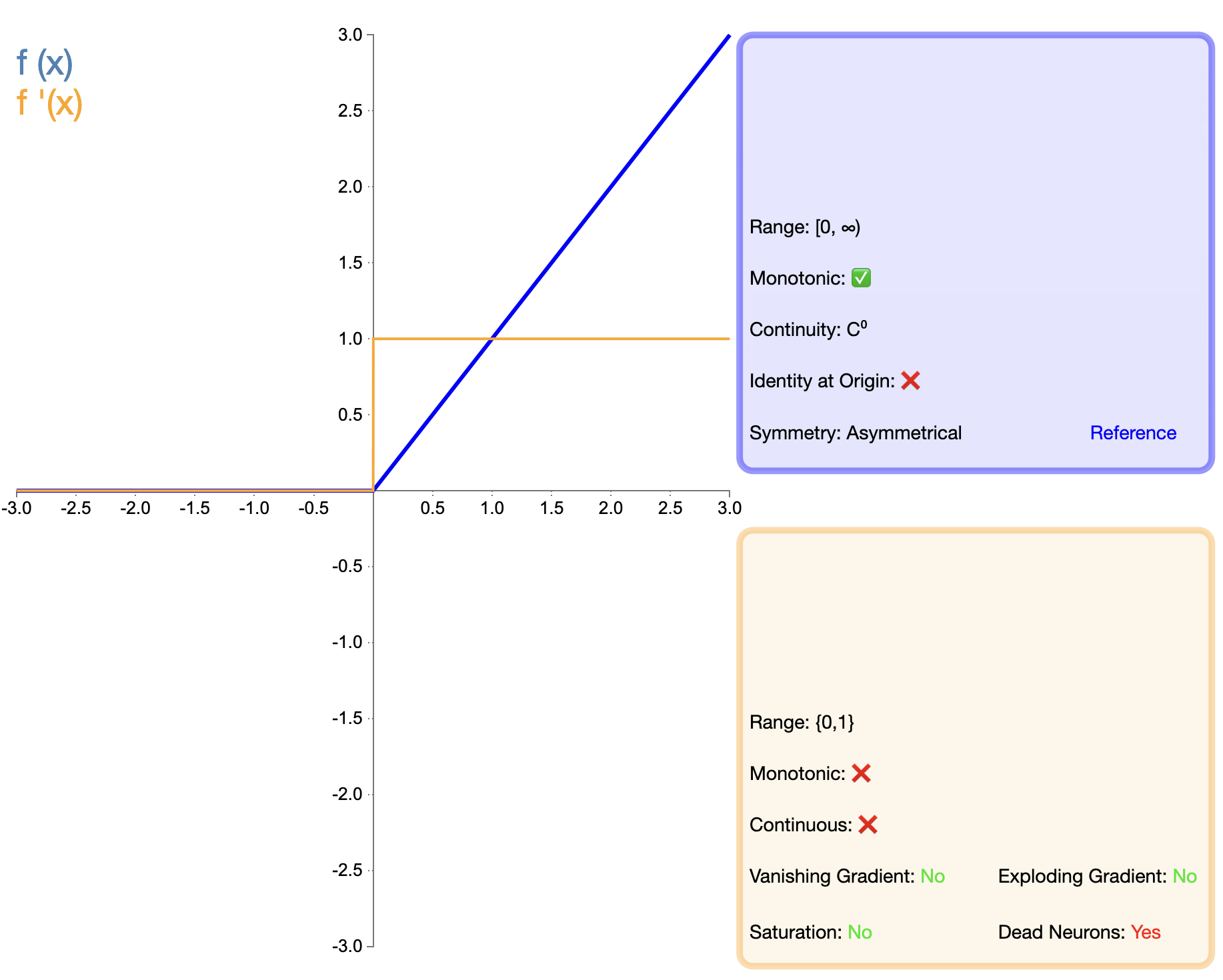
Compared with Sigmoid and Tanh, ReLU has shown significant advantages in deep networks, mainly in terms of training speed and alleviating gradient disappearance. However, the "dead ReLU" problem has prompted researchers to propose a variety of improved versions.
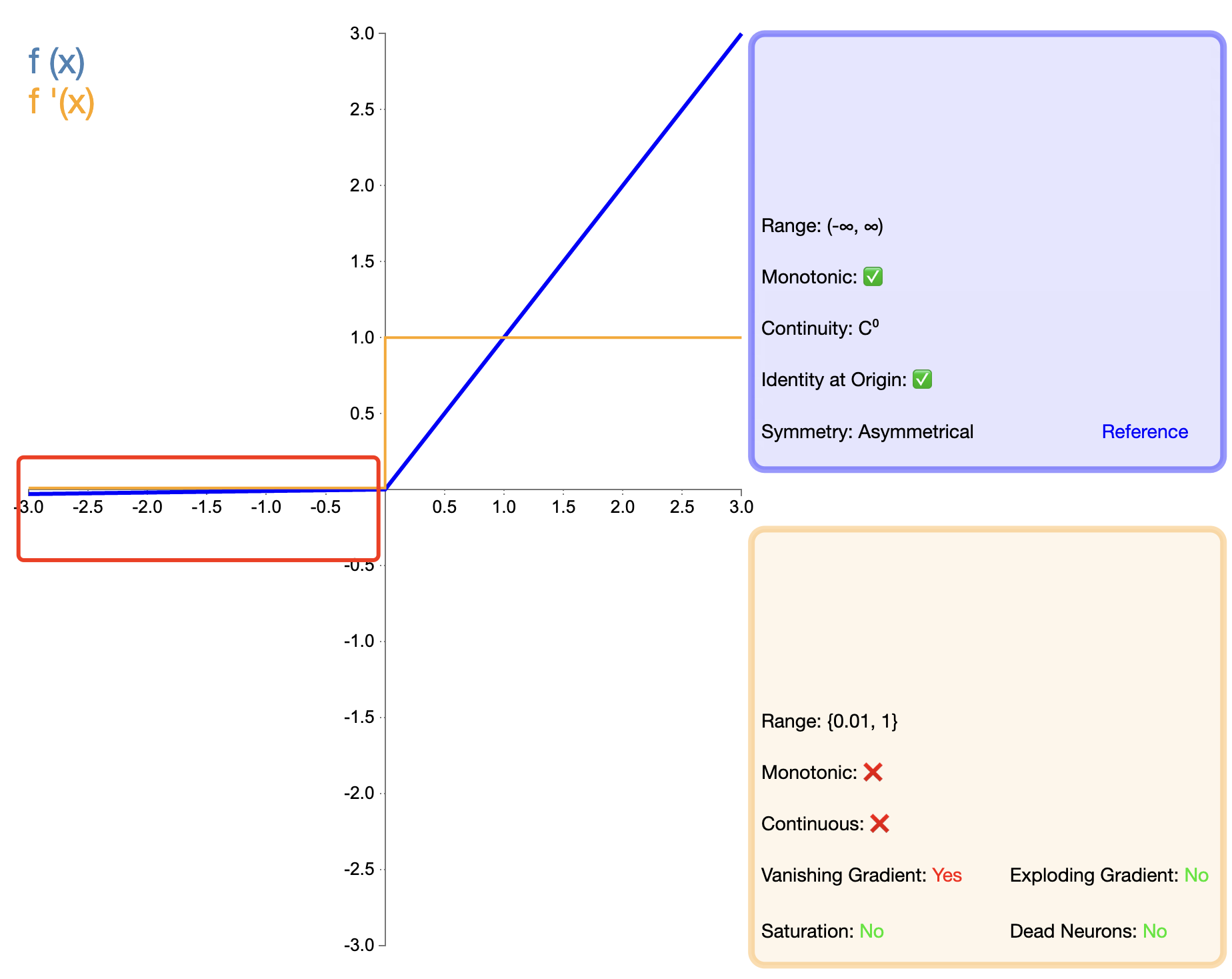
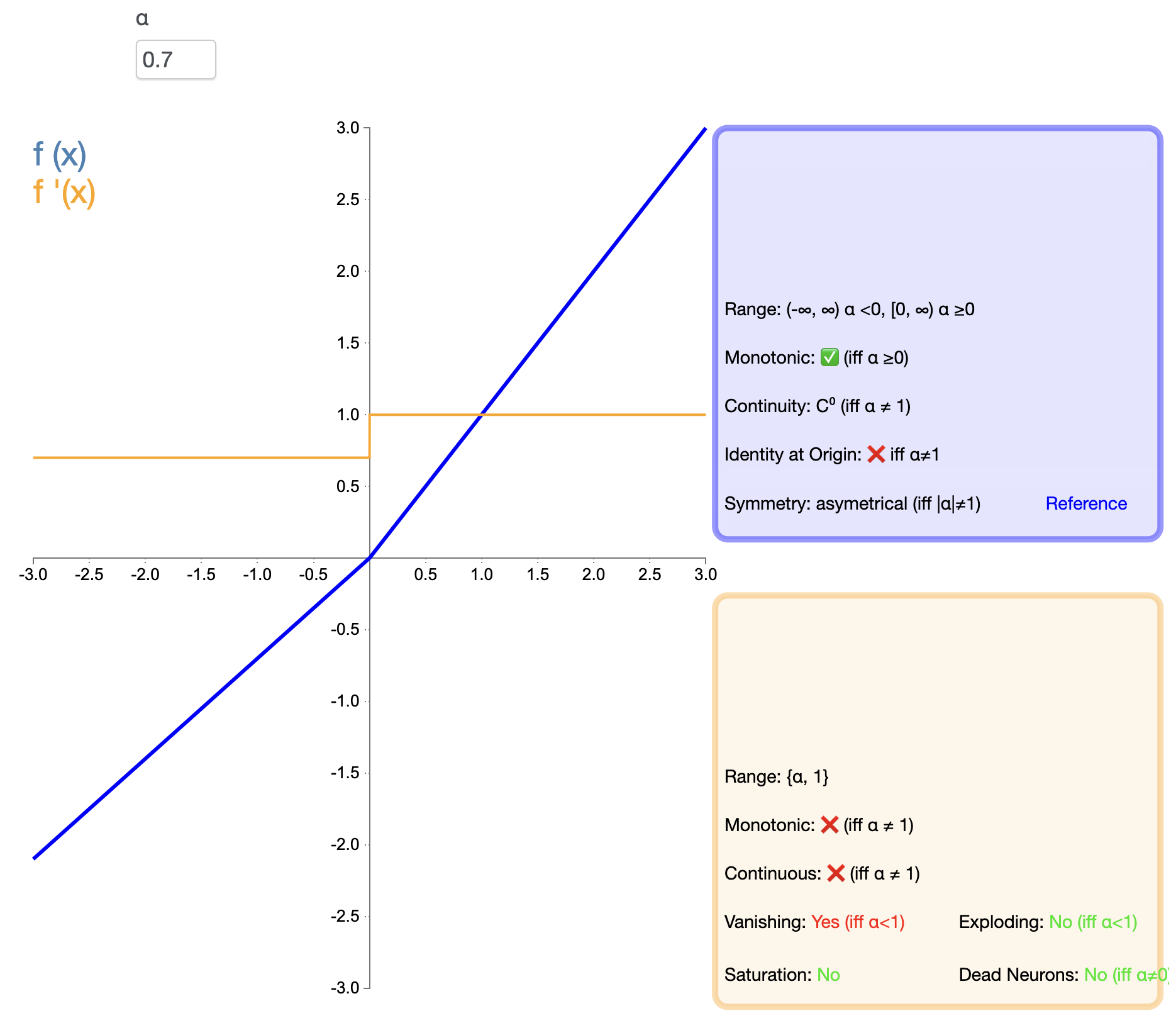
In order to solve the "death" problem of ReLU, Leaky ReLU was proposed:
Leaky ReLU ( x ) = { x , if x > 0 α x , if x ≤ 0 text{Leaky ReLU}(x) = {x,if x>0αx,if x≤0 Leaky ReLU(x)={
x,αx,if x>0if x≤0
in, α alpha α is a small positive constant, usually 0.01.
PReLU is a variant of Leaky ReLU, where the slope of the negative axis is a learnable parameter:
PReLU ( x ) = { x , if x > 0 α x , if x ≤ 0 text{PReLU}(x) = {x,if x>0αx,if x≤0 PReLU(x)={
x,αx,if x>0if x≤0
here α alpha α are the parameters learned through back-propagation.
ELU attempts to combine the advantages of ReLU and the processing of negative inputs. Its mathematical expression is:
ELU ( x ) = { x , if x > 0 α ( e x − 1 ) , if x ≤ 0 text{ELU}(x) = {x,if x>0α(ex−1),if x≤0 ELU(x)=

I have devoted myself to the research of technology for more than 30 years. I am proficient in various languages such as Java, Linux, JavaScript, PHP, CSS, etc. I have made many contributions in the field of open source. I have established a developer documentation site to share some problems in technology development for everyone to read.
