informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Artikel ini mengulas secara komprehensif pengembangan fungsi aktivasi dalam pembelajaran mendalam, mulai dari fungsi awal Sigmoid dan Tanh, hingga seri ReLU yang banyak digunakan, hingga fungsi aktivasi baru yang baru-baru ini diusulkan seperti Swish, Mish, dan GeLU. Analisis mendalam terhadap ekspresi matematika, karakteristik, kelebihan, keterbatasan dan penerapan berbagai fungsi aktivasi dalam model tipikal dilakukan. Melalui analisis komparatif sistematis, artikel ini membahas prinsip desain, standar evaluasi kinerja, dan kemungkinan arah pengembangan fungsi aktivasi di masa depan, memberikan panduan teoretis untuk optimalisasi dan desain model pembelajaran mendalam.
Fungsi aktivasi adalah komponen kunci dalam jaringan saraf, yang memperkenalkan karakteristik nonlinier pada keluaran neuron, memungkinkan jaringan saraf mempelajari dan merepresentasikan pemetaan nonlinier yang kompleks. Tanpa fungsi aktivasi, tidak peduli seberapa dalam jaringan saraf, pada dasarnya fungsi tersebut hanya dapat mewakili transformasi linier, yang sangat membatasi kemampuan ekspresif jaringan.
Dengan pesatnya perkembangan pembelajaran mendalam, desain dan pemilihan fungsi aktivasi telah menjadi faktor penting yang mempengaruhi performa model. Fungsi aktivasi yang berbeda memiliki karakteristik yang berbeda, seperti fluiditas gradien, kompleksitas komputasi, derajat nonlinier, dll. Karakteristik ini secara langsung memengaruhi efisiensi pelatihan, kecepatan konvergensi, dan kinerja akhir jaringan saraf.
Artikel ini bertujuan untuk meninjau secara komprehensif evolusi fungsi aktivasi, menganalisis secara mendalam karakteristik berbagai fungsi aktivasi, dan mengeksplorasi penerapannya dalam model pembelajaran mendalam modern. Kami akan membahas aspek-aspek berikut:
Melalui tinjauan dan analisis sistematis ini, kami berharap dapat memberikan referensi komprehensif bagi para peneliti dan praktisi untuk membantu mereka memilih dan menggunakan fungsi aktivasi dengan lebih baik dalam desain model pembelajaran mendalam.
Fungsi Sigmoid adalah salah satu fungsi aktivasi paling awal yang banyak digunakan, dan ekspresi matematisnya adalah:
σ ( x ) = 1 1 + e − x sigma(x) = pecahan{1}{1 + e^{-x}}σ(X)=1+Bahasa Inggris:−X1
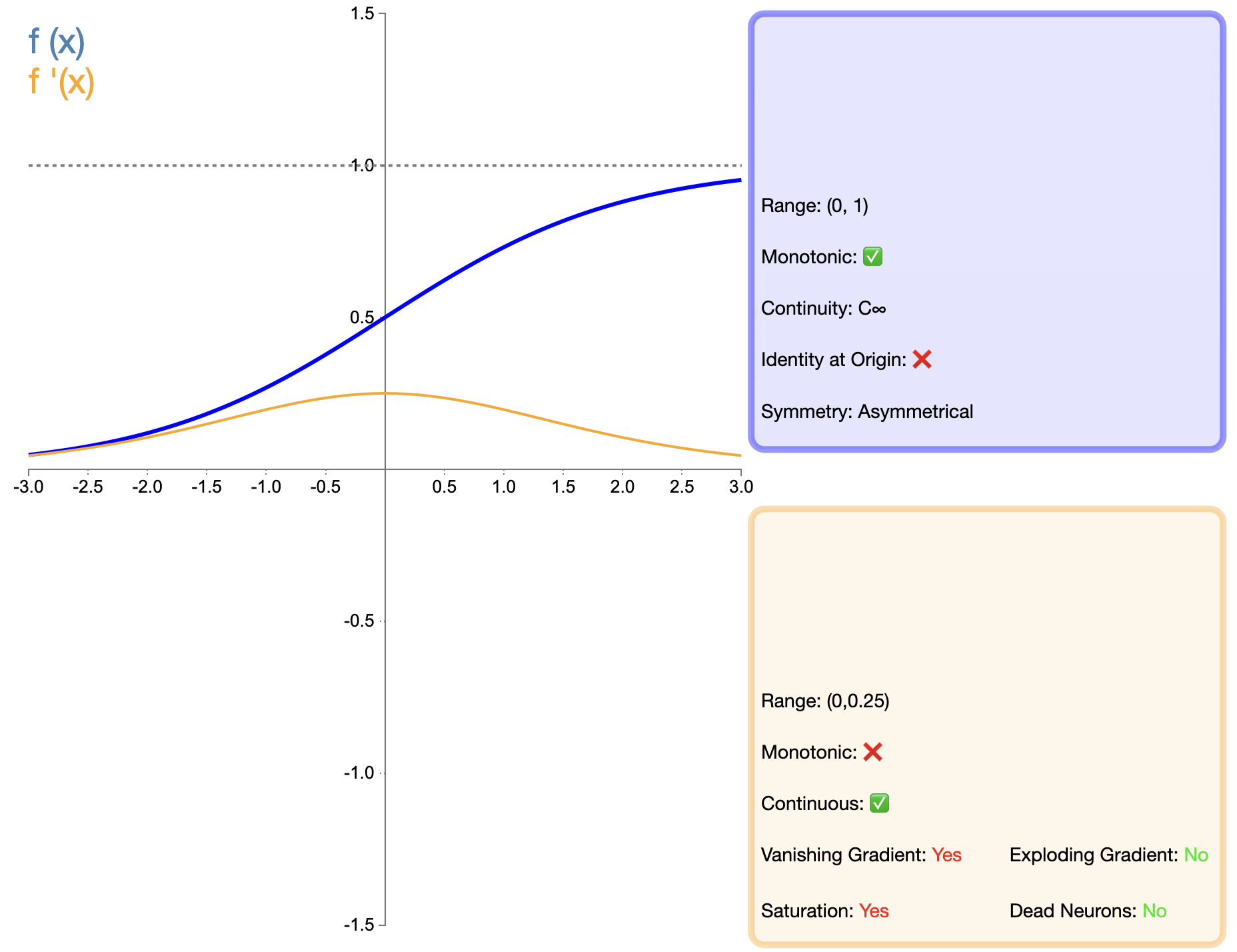
Dibandingkan dengan fungsi seperti ReLU yang muncul kemudian, penerapan Sigmoid di jaringan dalam sangat terbatas, terutama karena masalah hilangnya gradien. Namun, dalam beberapa tugas tertentu (seperti klasifikasi biner), sigmoid masih merupakan pilihan yang efektif.
Fungsi Tanh (tangen hiperbolik) dapat dianggap sebagai versi perbaikan dari fungsi Sigmoid, dan ekspresi matematisnya adalah:
tanh ( x ) = ex − e − xex + e − x tanh(x) = pecahan{e^x - e^{-x}}{e^x + e^{-x}}tanh(X)=Bahasa Inggris:X+Bahasa Inggris:−XBahasa Inggris:X−Bahasa Inggris:−X
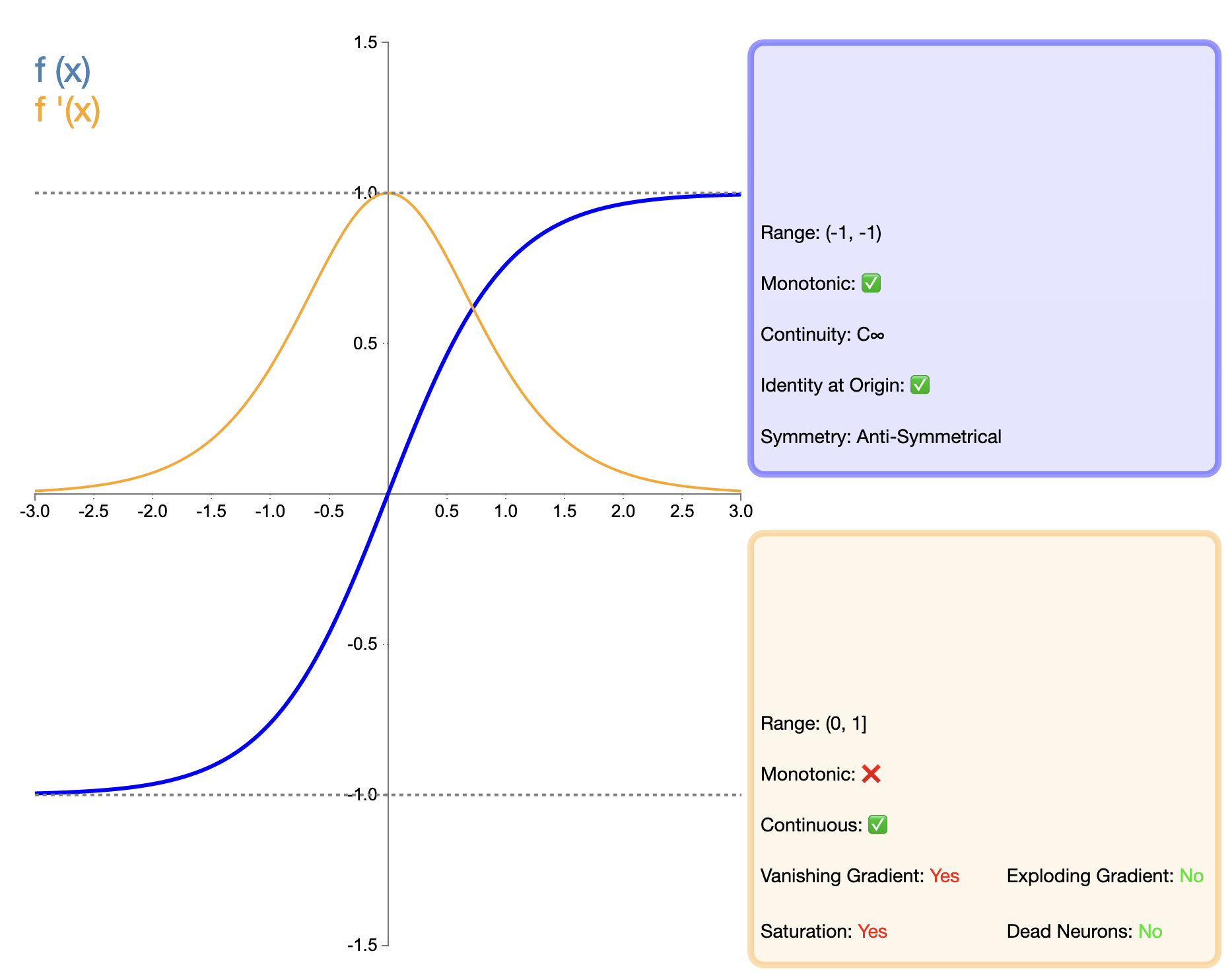
Fungsi Tanh dapat dianggap sebagai versi perbaikan dari fungsi Sigmoid. Peningkatan utama terletak pada keluaran yang terpusat pada nol. Fitur ini membuat kinerja Tanh lebih baik daripada Sigmoid dalam banyak situasi, terutama di jaringan dalam. Namun, dibandingkan dengan fungsi seperti ReLU yang muncul kemudian, Tanh masih memiliki masalah hilangnya gradien, yang dapat mempengaruhi performa model di jaringan yang sangat dalam.
Dua fungsi aktivasi klasik, Sigmoid dan Tanh, memainkan peran penting pada masa-masa awal pembelajaran mendalam, dan karakteristik serta keterbatasannya juga mendorong pengembangan fungsi aktivasi selanjutnya. Meskipun fungsi tersebut telah digantikan oleh fungsi aktivasi yang diperbarui dalam banyak skenario, fungsi tersebut masih memiliki nilai penerapan unik dalam tugas dan struktur jaringan tertentu.
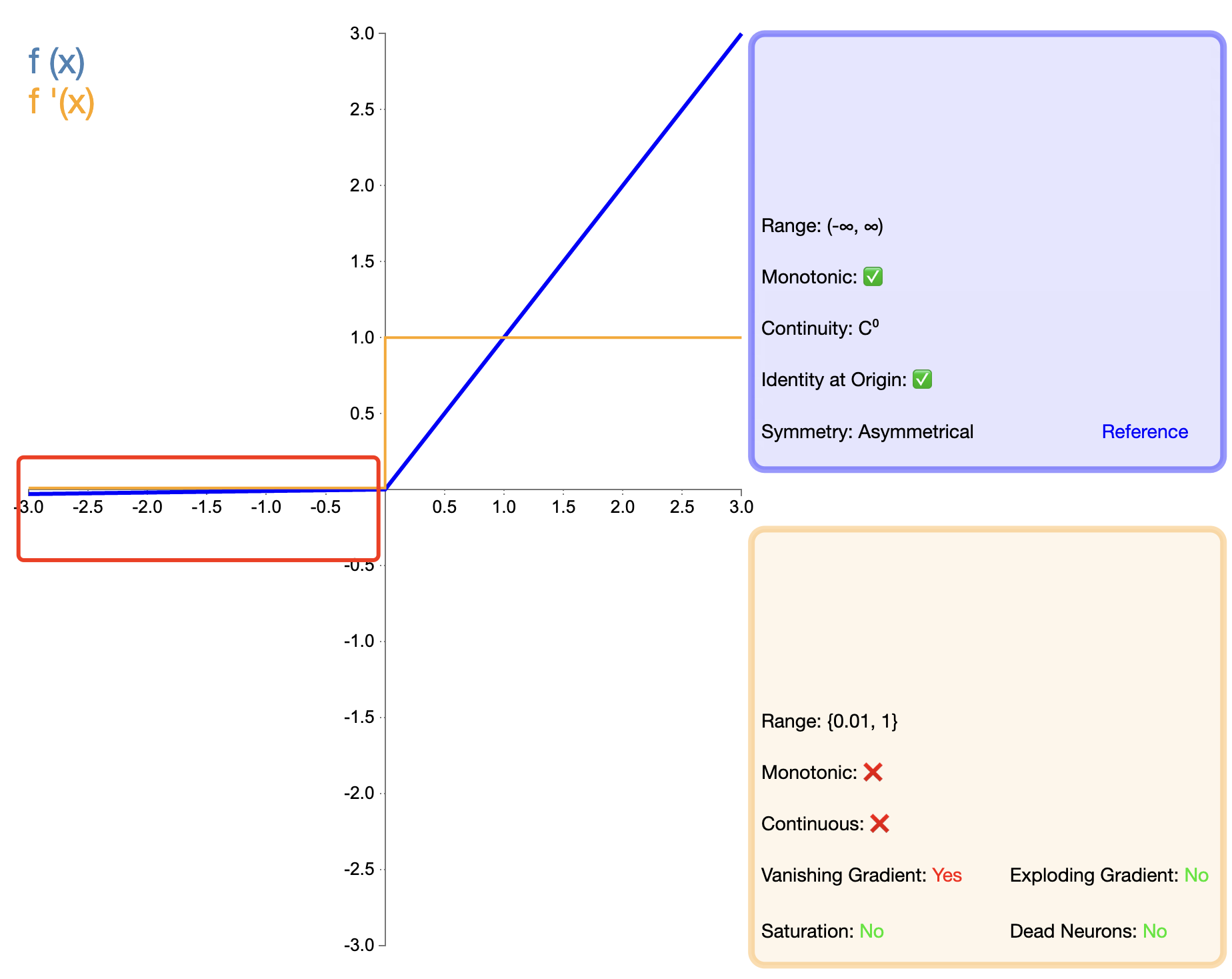
Usulan fungsi ULT merupakan tonggak penting dalam pengembangan fungsi aktivasi. Ekspresi matematikanya sederhana:
ReLU ( x ) = maks ( 0 , x ) teks{ReLU}(x) = maks(0, x)Ulang LU(X)=maks(0,X)
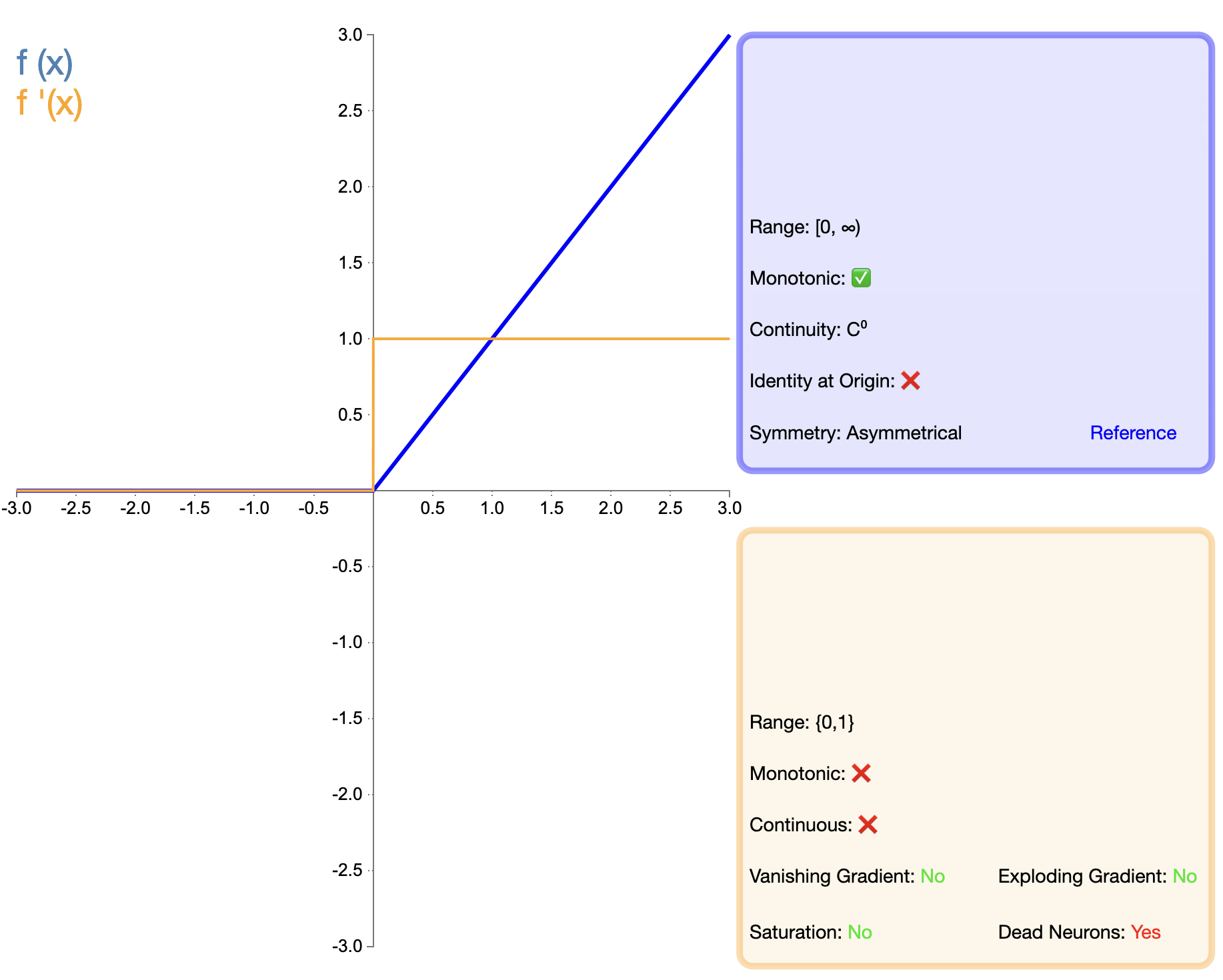
Dibandingkan dengan Sigmoid dan Tanh, ReLU menunjukkan keunggulan signifikan dalam jaringan dalam, terutama dalam hal kecepatan pelatihan dan mitigasi hilangnya gradien. Namun, masalah “ReLU yang mati” telah mendorong para peneliti untuk mengusulkan berbagai versi perbaikan.
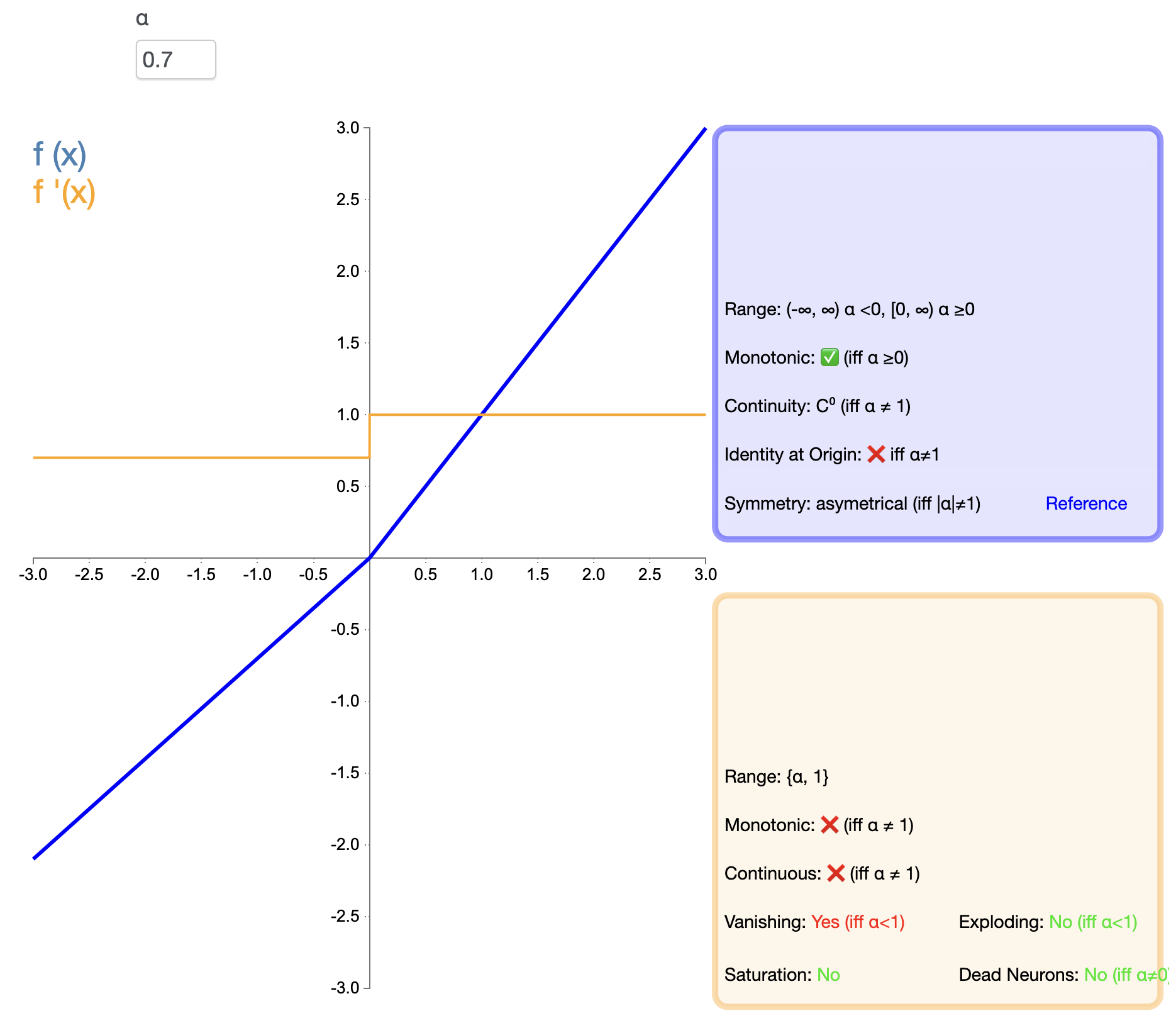
Untuk mengatasi masalah "kematian" ReLU, Leaky ReLU diusulkan:
Leaky ReLU ( x ) = { x , jika x > 0 α x , jika x ≤ 0 text{Leaky ReLU}(x) ={X,jikaX>0αX,jikaX≤0 ReLU yang bocor(X)={
X,sebuah kapak,jikaX>0jikaX≤0
di dalam, α alfaα adalah konstanta positif kecil, biasanya 0,01.
PReLU adalah varian dari Leaky ReLU, yang kemiringan sumbu semi negatifnya merupakan parameter yang dapat dipelajari:
PReLU ( x ) = { x , jika x > 0 α x , jika x ≤ 0 text{PReLU}(x) ={X,jikaX>0αX,jikaX≤0 Pra-Lu(X)={
X,sebuah kapak,jikaX>0jikaX≤0
Di Sini α alfaα adalah parameter yang dipelajari melalui propagasi mundur.
ELU mencoba menggabungkan keunggulan ReLU dan pemrosesan masukan negatif.
ELU ( x ) = { x , jika x > 0 α ( ex − 1 ) , jika x ≤ 0 text{ELU}(x) ={X,jikaX>0α(Bahasa Inggris:X−1),jikaX≤0 ELU(X)=

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]