2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Cet article passe en revue de manière exhaustive le développement des fonctions d'activation dans l'apprentissage profond, depuis les premières fonctions Sigmoïde et Tanh, jusqu'à la série ReLU largement utilisée, en passant par les nouvelles fonctions d'activation récemment proposées telles que Swish, Mish et GeLU. Une analyse approfondie des expressions mathématiques, des caractéristiques, des avantages, des limites et des applications de diverses fonctions d'activation dans des modèles typiques est menée. Grâce à une analyse comparative systématique, cet article discute des principes de conception, des normes d'évaluation des performances et des orientations de développement futures possibles des fonctions d'activation, fournissant des conseils théoriques pour l'optimisation et la conception de modèles d'apprentissage profond.
La fonction d'activation est un élément clé des réseaux de neurones, qui introduit des caractéristiques non linéaires à la sortie des neurones, permettant aux réseaux de neurones d'apprendre et de représenter des mappages non linéaires complexes. Sans fonction d'activation, quelle que soit la profondeur d'un réseau neuronal, il ne peut essentiellement représenter que des transformations linéaires, ce qui limite considérablement la capacité d'expression du réseau.
Avec le développement rapide de l’apprentissage profond, la conception et la sélection des fonctions d’activation sont devenues des facteurs importants affectant les performances des modèles. Différentes fonctions d'activation ont des caractéristiques différentes, telles que la fluidité du gradient, la complexité de calcul, le degré de non-linéarité, etc. Ces caractéristiques affectent directement l'efficacité de la formation, la vitesse de convergence et les performances finales du réseau neuronal.
Cet article vise à examiner de manière approfondie l'évolution des fonctions d'activation, à analyser en profondeur les caractéristiques de diverses fonctions d'activation et à explorer leur application dans les modèles modernes d'apprentissage profond. Nous aborderons les aspects suivants :
Grâce à cette revue et analyse systématiques, nous espérons fournir une référence complète aux chercheurs et aux praticiens pour les aider à mieux sélectionner et utiliser les fonctions d'activation dans la conception de modèles d'apprentissage profond.
La fonction sigmoïde est l'une des premières fonctions d'activation largement utilisées, et son expression mathématique est la suivante :
σ ( x ) = 1 1 + e − x sigma(x) = frac{1}{1 + e^{-x}}σ(X)=1+etttttt−X1
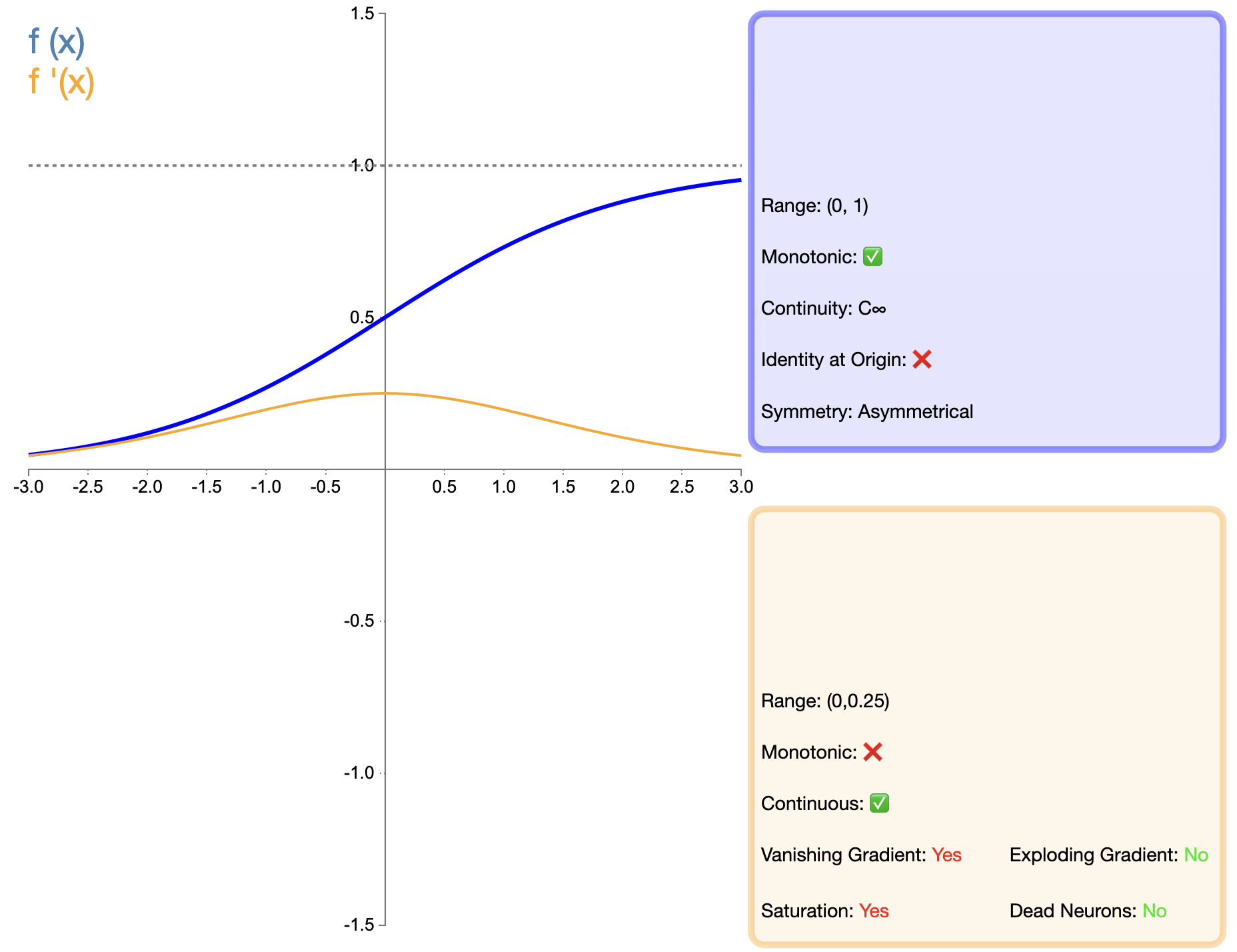
Par rapport aux fonctions telles que ReLU apparues plus tard, l’application de Sigmoid dans les réseaux profonds a été considérablement limitée, principalement en raison de son problème de gradient de disparition. Cependant, dans certaines tâches spécifiques (telles que la classification binaire), le sigmoïde reste un choix efficace.
La fonction Tanh (tangente hyperbolique) peut être considérée comme une version améliorée de la fonction Sigmoïde, et son expression mathématique est :
tanh ( x ) = ex − e − x ex + e − x tanh(x) = frac{e^x - e^{-x}}{e^x + e^{-x}}tanh(X)=ettttttX+etttttt−XettttttX−etttttt−X
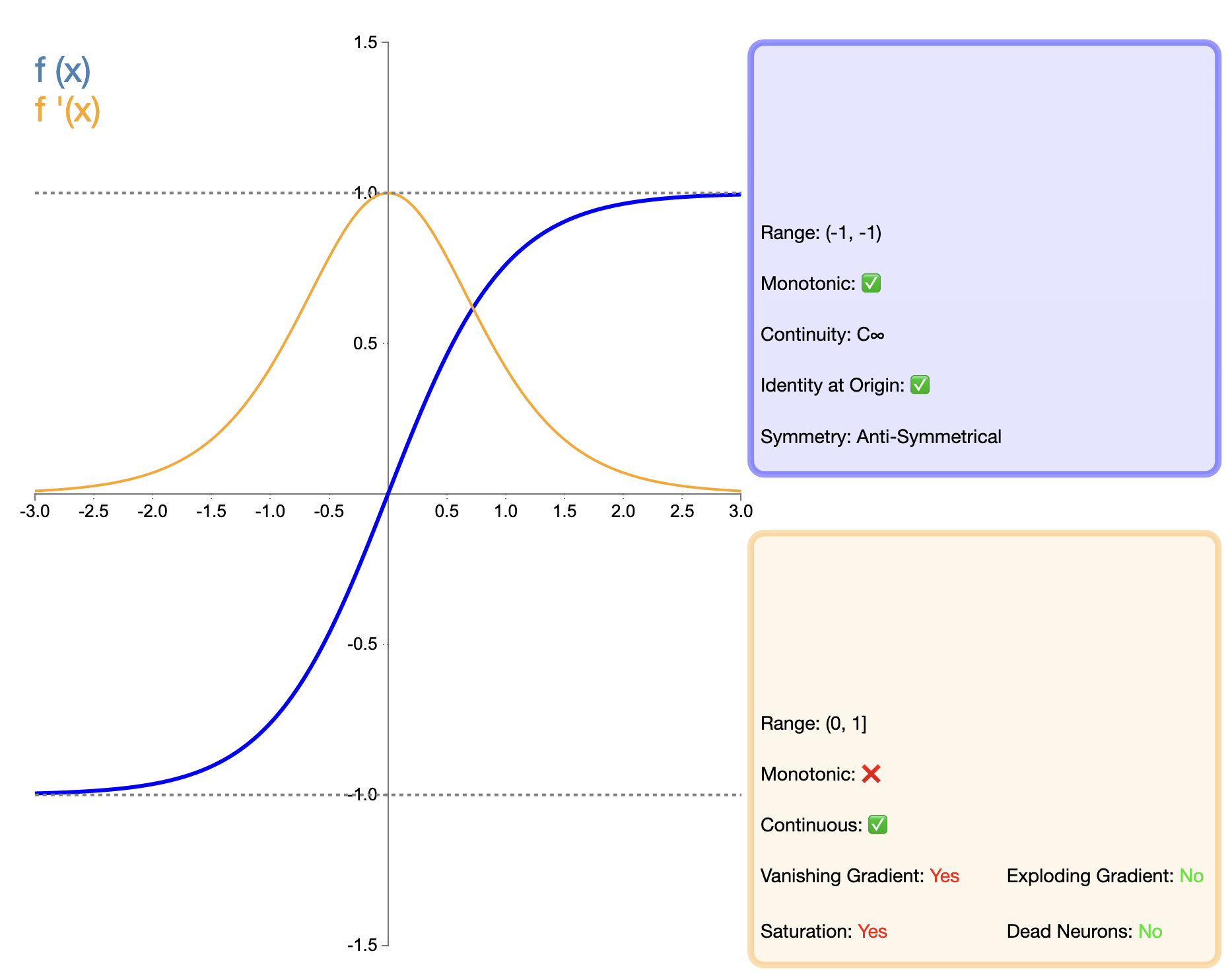
La fonction Tanh peut être considérée comme une version améliorée de la fonction Sigmoïde. La principale amélioration réside dans le centrage zéro de la sortie. Cette fonctionnalité permet à Tanh de mieux fonctionner que Sigmoid dans de nombreuses situations, en particulier dans les réseaux profonds. Cependant, par rapport aux fonctions telles que ReLU apparues plus tard, Tanh a toujours le problème de la disparition du gradient, ce qui peut affecter les performances du modèle dans les réseaux très profonds.
Les deux fonctions d’activation classiques, Sigmoïde et Tanh, ont joué un rôle important dans les premiers jours de l’apprentissage profond, et leurs caractéristiques et limites ont également favorisé le développement de fonctions d’activation ultérieures. Bien qu'elles aient été remplacées par des fonctions d'activation mises à jour dans de nombreux scénarios, elles ont toujours leur valeur d'application unique dans des tâches et des structures de réseau spécifiques.
La proposition de la fonction ReLU constitue une étape importante dans le développement des fonctions d'activation. Son expression mathématique est simple :
ReLU ( x ) = max ( 0 , x ) texte{ReLU}(x) = max(0, x)ReLU(X)=max(0,X)
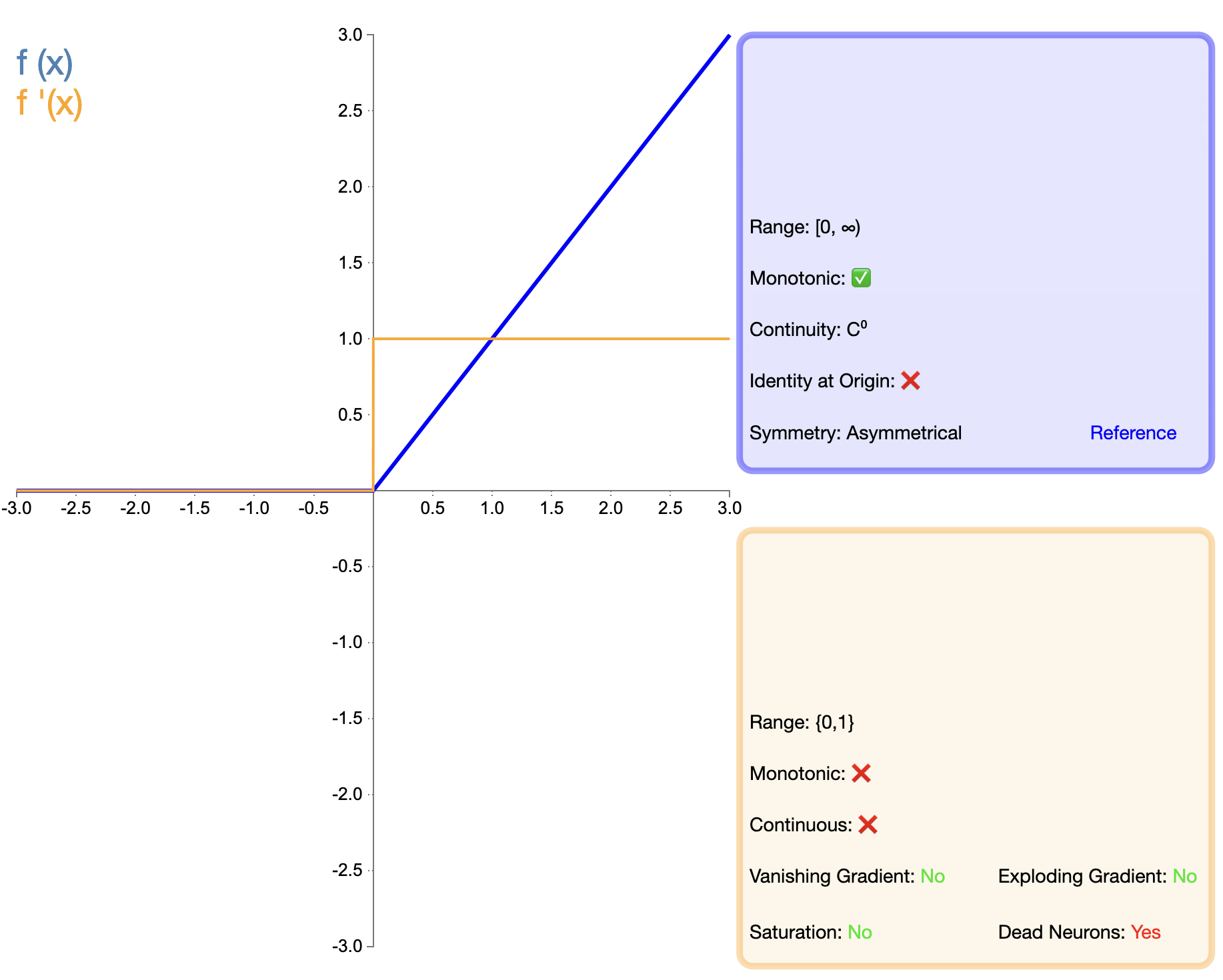
Par rapport à Sigmoid et Tanh, ReLU présente des avantages significatifs dans les réseaux profonds, principalement en termes de vitesse d'entraînement et d'atténuation de la disparition du gradient. Cependant, le problème du « ReLU mort » a incité les chercheurs à proposer diverses versions améliorées.
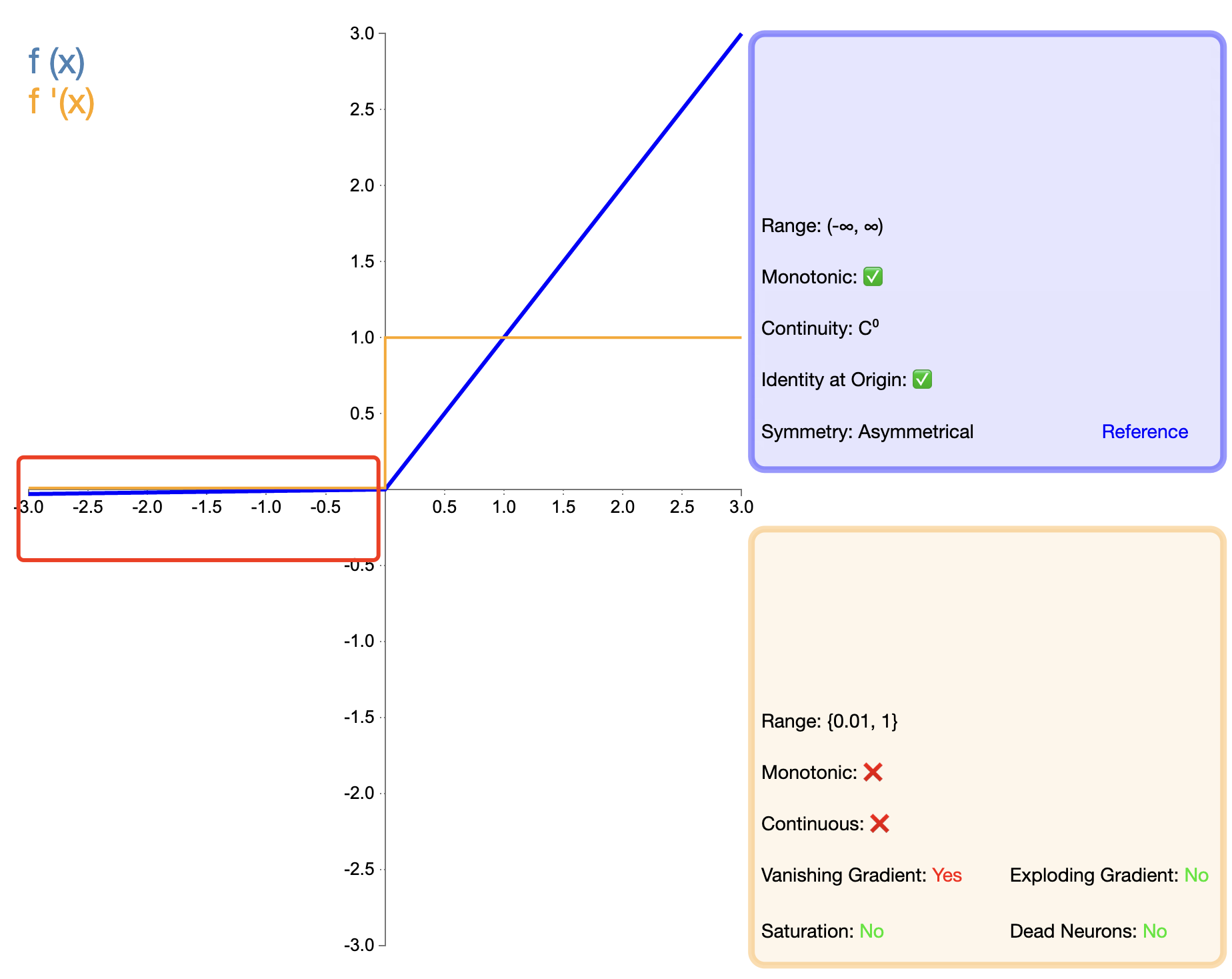
Afin de résoudre le problème de « mort » de ReLU, Leaky ReLU a été proposé :
Fuite ReLU ( x ) = { x , si x > 0 α x , si x ≤ 0 texte{Fuite ReLU}(x) ={X,siX>0αX,siX≤0 Fuite de ReLU(X)={
X,αx,siX>0siX≤0
dans, alpha-alphaα est une petite constante positive, généralement 0,01.
PReLU est une variante de Leaky ReLU, où la pente du demi-axe négatif est un paramètre apprenable :
PReLU ( x ) = { x , si x > 0 α x , si x ≤ 0 texte{PReLU}(x) ={X,siX>0αX,siX≤0 PRéLU(X)={
X,αx,siX>0siX≤0
ici alpha-alphaα sont des paramètres appris par rétropropagation.
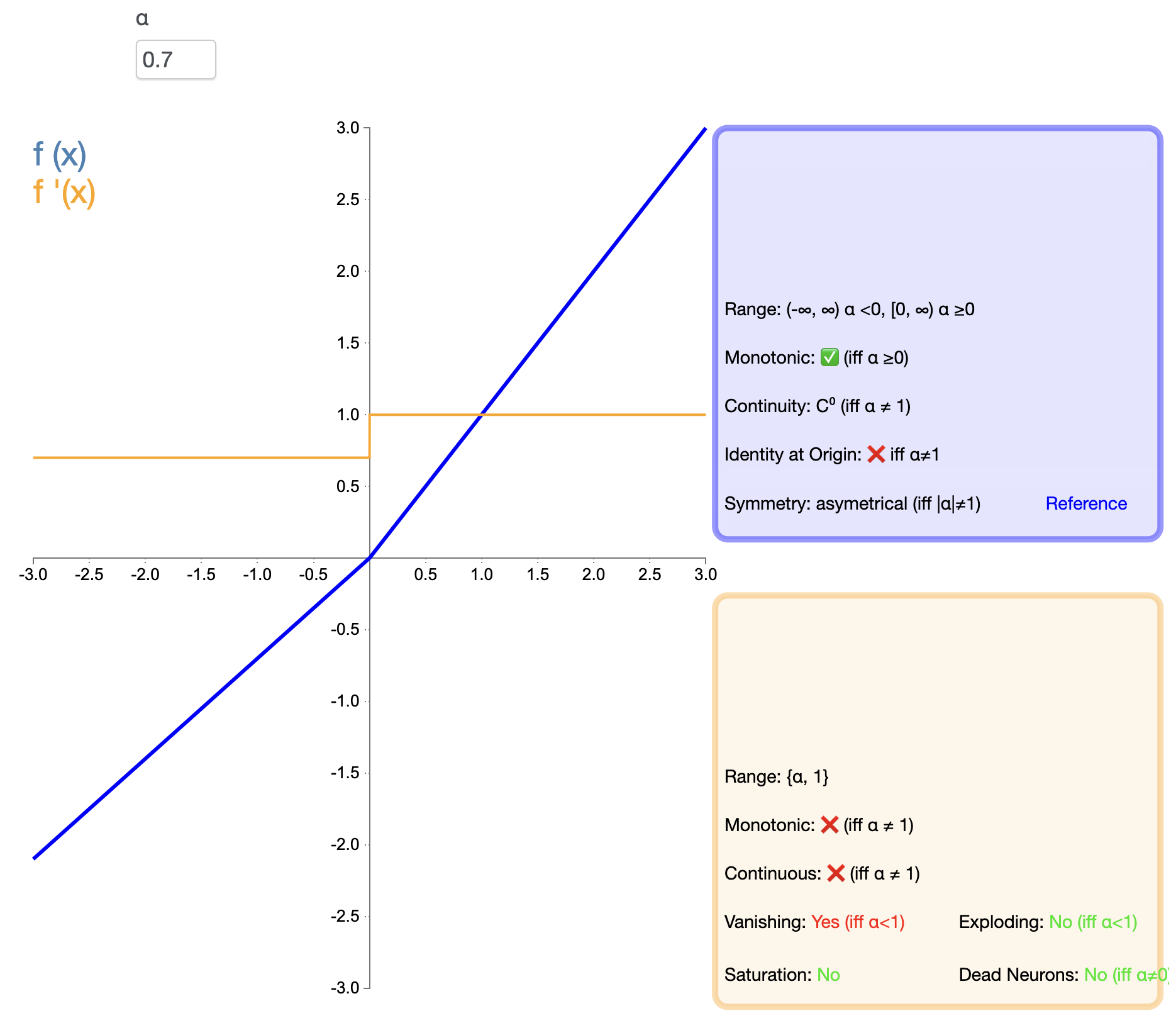
ELU tente de combiner les avantages de ReLU et le traitement des entrées négatives. Son expression mathématique est :
ELU ( x ) = { x , si x > 0 α ( ex − 1 ) , si x ≤ 0 texte{ELU}(x) ={X,siX>0α(ettttttX−1),siX≤0 ÉLU(X)=

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.
