le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Questo articolo esamina in modo completo lo sviluppo delle funzioni di attivazione nel deep learning, dalle prime funzioni Sigmoid e Tanh, alle serie ReLU ampiamente utilizzate, alle nuove funzioni di attivazione recentemente proposte come Swish, Mish e GeLU. Viene condotta un'analisi approfondita delle espressioni matematiche, caratteristiche, vantaggi, limitazioni e applicazioni di varie funzioni di attivazione in modelli tipici. Attraverso un'analisi comparativa sistematica, questo articolo discute i principi di progettazione, gli standard di valutazione delle prestazioni e le possibili direzioni di sviluppo futuro delle funzioni di attivazione, fornendo una guida teorica per l'ottimizzazione e la progettazione di modelli di deep learning.
La funzione di attivazione è una componente chiave nelle reti neurali, che introduce caratteristiche non lineari all'uscita dei neuroni, consentendo alle reti neurali di apprendere e rappresentare complesse mappature non lineari. Senza una funzione di attivazione, per quanto profonda sia una rete neurale, essa può essenzialmente rappresentare solo trasformazioni lineari, il che limita notevolmente la capacità espressiva della rete.
Con il rapido sviluppo del deep learning, la progettazione e la selezione delle funzioni di attivazione sono diventati fattori importanti che influenzano le prestazioni del modello. Diverse funzioni di attivazione hanno caratteristiche diverse, come fluidità del gradiente, complessità computazionale, grado di non linearità, ecc. Queste caratteristiche influenzano direttamente l'efficienza dell'addestramento, la velocità di convergenza e le prestazioni finali della rete neurale.
Questo articolo mira a rivedere in modo completo l'evoluzione delle funzioni di attivazione, analizzare in modo approfondito le caratteristiche di varie funzioni di attivazione ed esplorare la loro applicazione nei moderni modelli di deep learning. Tratteremo i seguenti aspetti:
Attraverso questa revisione e analisi sistematica, speriamo di fornire un riferimento completo a ricercatori e professionisti per aiutarli a selezionare e utilizzare meglio le funzioni di attivazione nella progettazione di modelli di deep learning.
La funzione Sigmoide è una delle prime funzioni di attivazione ampiamente utilizzate e la sua espressione matematica è:
σ ( x ) = 1 1 + e − x sigma(x) = frac{1}{1 + e^{-x}}σ(X)=1+e−X1
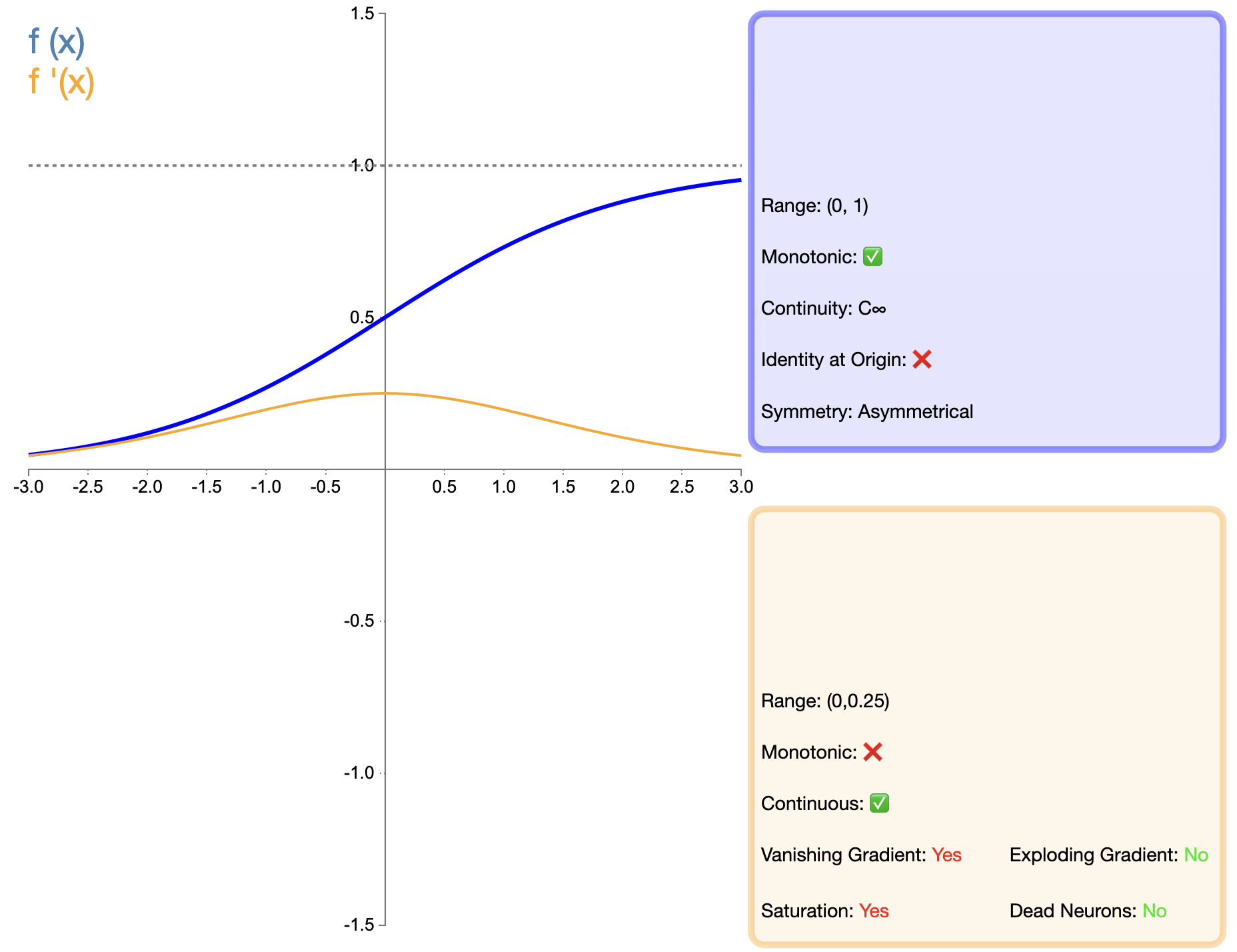
Rispetto a funzioni come ReLU apparse successivamente, l'applicazione di Sigmoid nelle reti profonde è stata notevolmente limitata, principalmente a causa del problema del gradiente evanescente. Tuttavia, in alcuni compiti specifici (come la classificazione binaria), il sigma è ancora una scelta efficace.
La funzione Tanh (tangente iperbolica) può essere considerata una versione migliorata della funzione Sigmoide e la sua espressione matematica è:
tanh ( x ) = ex − e − xex + e − x tanh(x) = frac{e^x - e^{-x}}{e^x + e^{-x}}Tanh-tanga(X)=eX+e−XeX−e−X
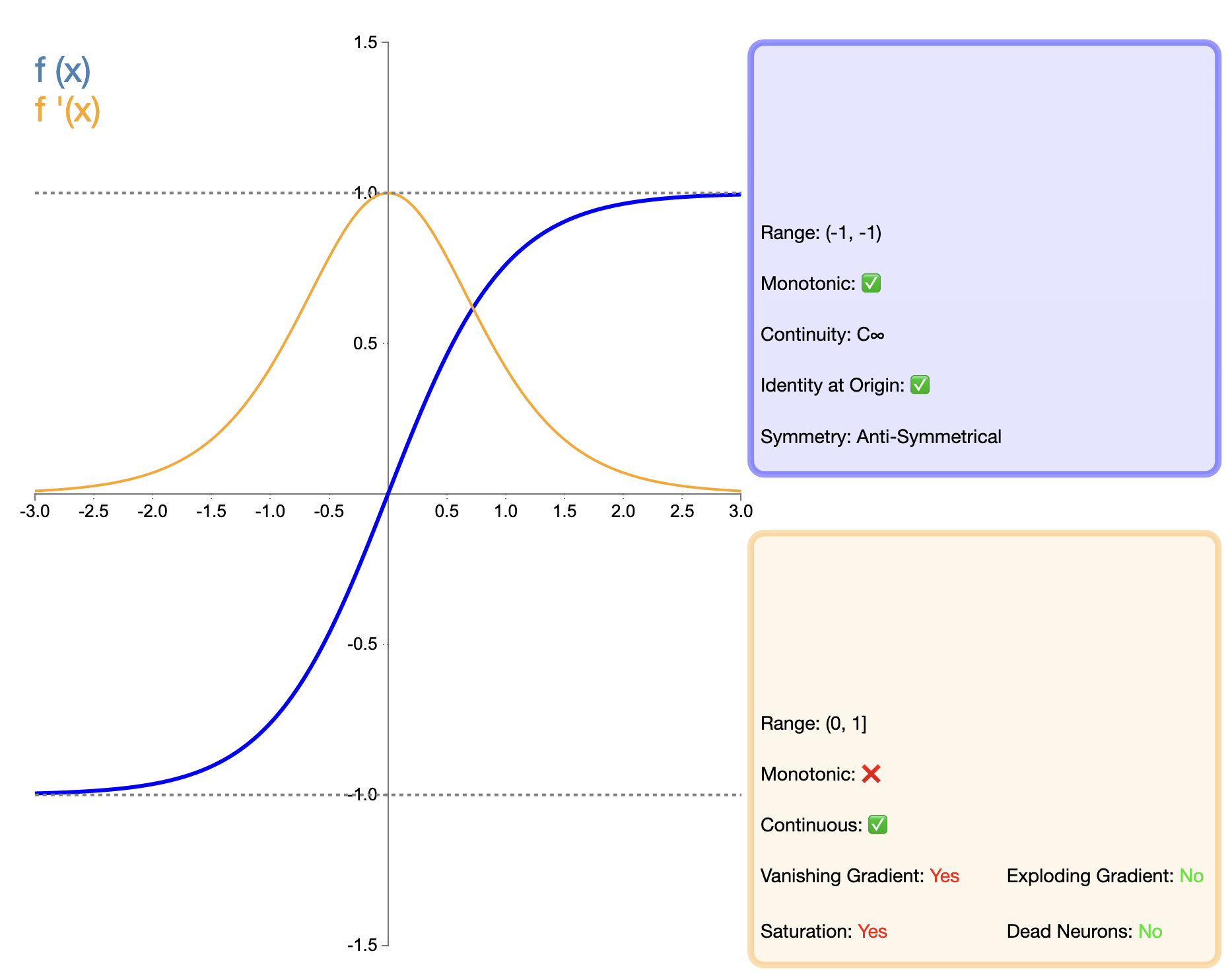
La funzione Tanh può essere considerata una versione migliorata della funzione Sigmoid. Il miglioramento principale risiede nel centraggio dello zero dell'output. Questa caratteristica fa sì che Tanh funzioni meglio di Sigmoid in molte situazioni, specialmente nelle reti profonde. Tuttavia, rispetto a funzioni come ReLU apparse successivamente, Tanh presenta ancora il problema della scomparsa del gradiente, che può influire sulle prestazioni del modello in reti molto profonde.
Le due classiche funzioni di attivazione, Sigmoid e Tanh, hanno svolto un ruolo importante agli albori del deep learning, e le loro caratteristiche e limitazioni hanno promosso anche lo sviluppo di successive funzioni di attivazione. Sebbene in molti scenari siano stati sostituiti da funzioni di attivazione aggiornate, mantengono ancora il loro valore applicativo unico in compiti e strutture di rete specifici.
La proposta della funzione ReLU rappresenta una tappa importante nello sviluppo delle funzioni di attivazione. La sua espressione matematica è semplice:
ReLU ( x ) = max ( 0 , x ) testo{ReLU}(x) = max(0, x)Ri-LU(X)=massimo(0,X)
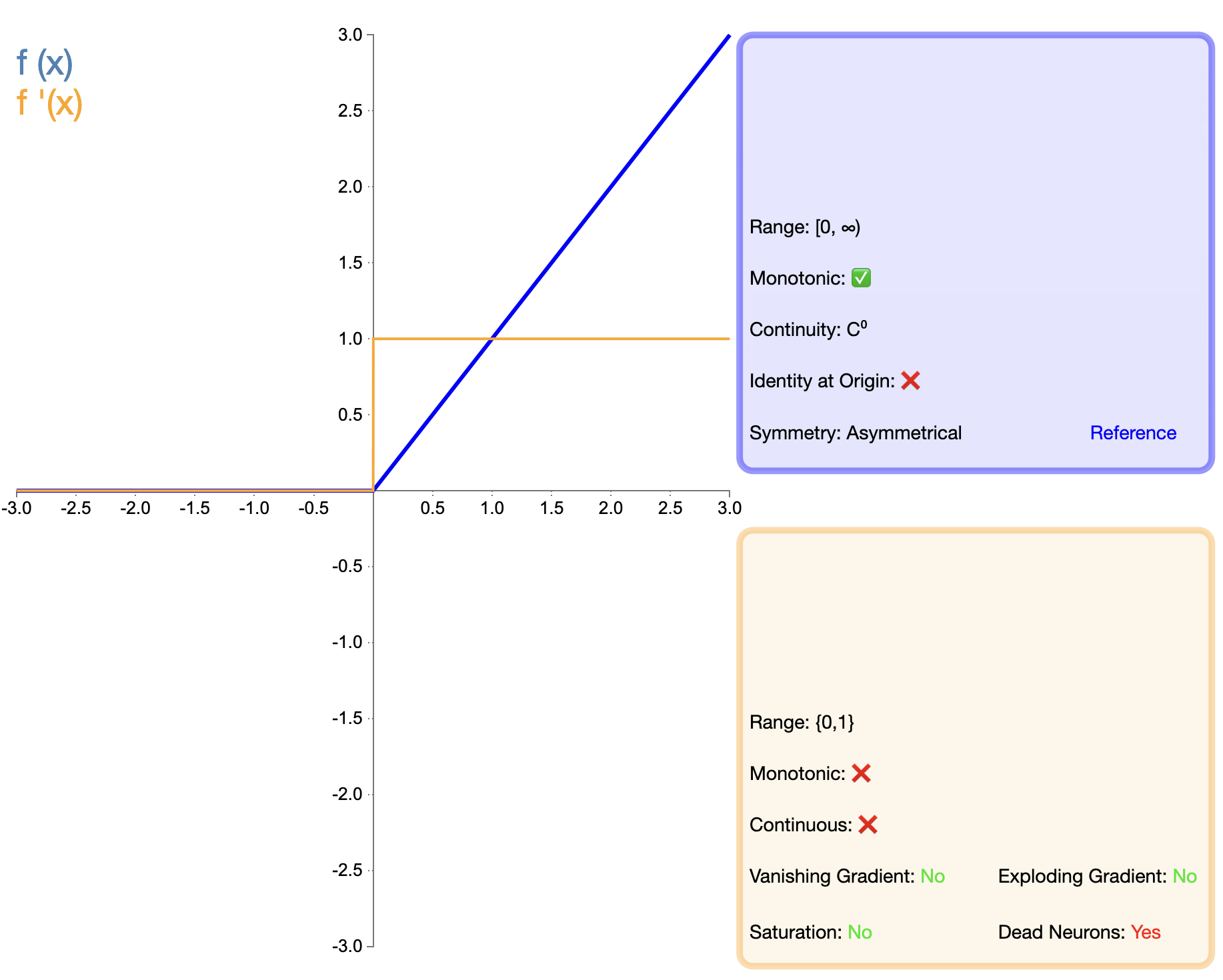
Rispetto a Sigmoid e Tanh, ReLU mostra vantaggi significativi nelle reti profonde, principalmente in termini di velocità di allenamento e mitigazione della scomparsa del gradiente. Tuttavia, il problema della "ReLU morta" ha spinto i ricercatori a proporre varie versioni migliorate.
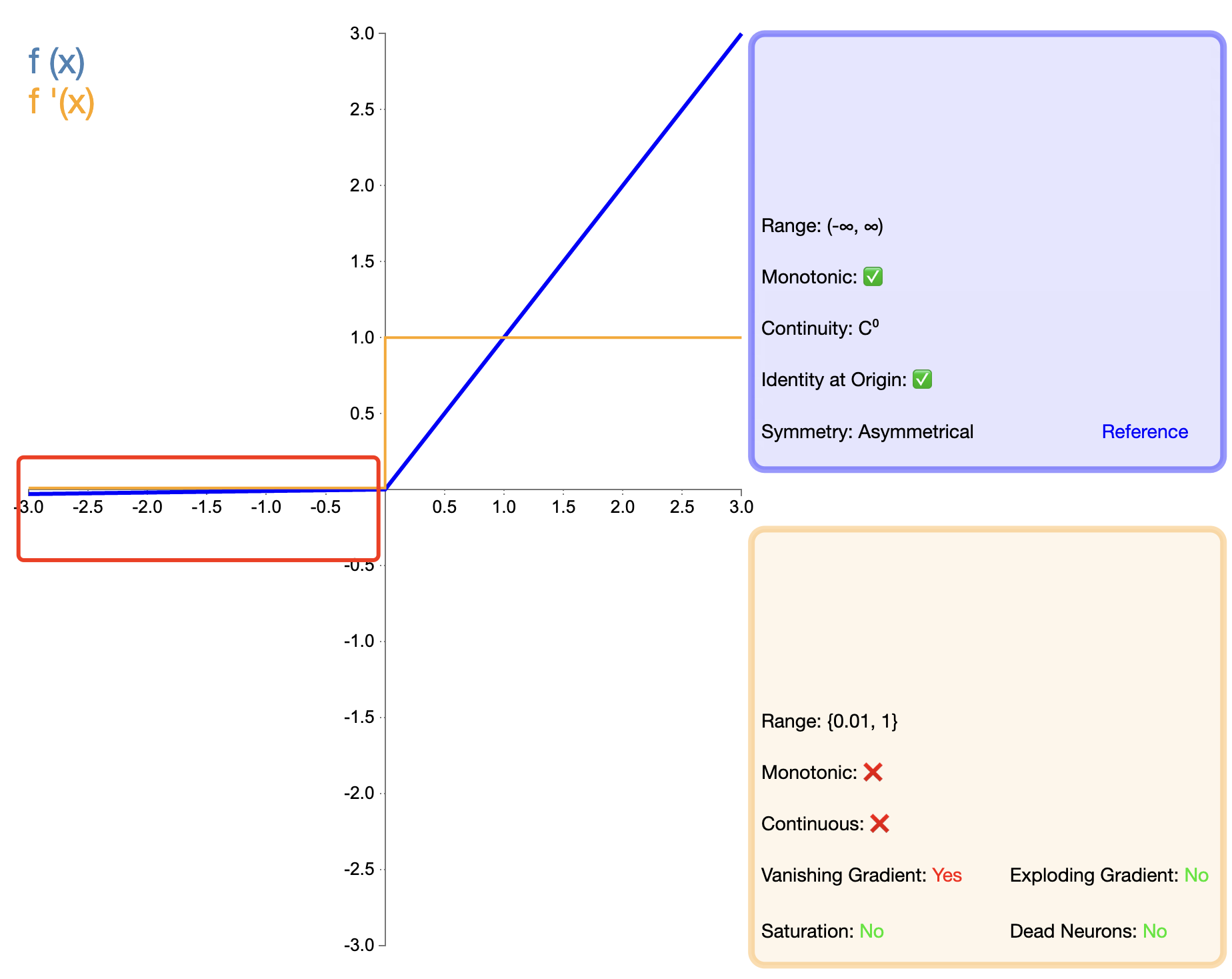
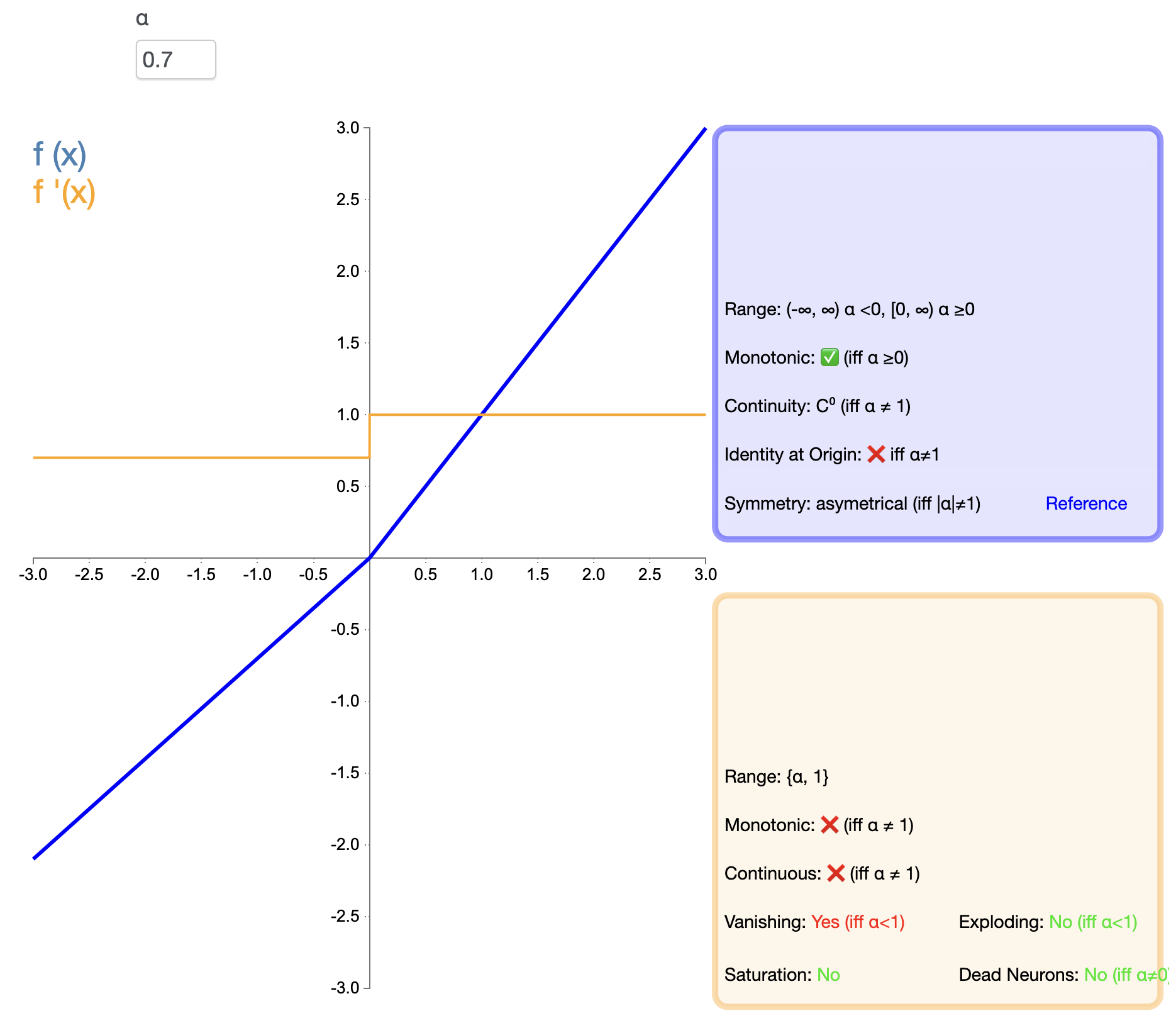
Per risolvere il problema della "morte" di ReLU, è stato proposto Leaky ReLU:
Leaky ReLU ( x ) = { x , se x > 0 α x , se x ≤ 0 testo{Leaky ReLU}(x) ={X,SeX>0αX,SeX≤0 ReLU che perde(X)={
X,l'asse alfa,SeX>0SeX≤0
In, alfa alfaα è una piccola costante positiva, solitamente 0,01.
PReLU è una variante di Leaky ReLU, dove la pendenza del semiasse negativo è un parametro apprendibile:
PReLU ( x ) = { x , se x > 0 α x , se x ≤ 0 testo{PReLU}(x) ={X,SeX>0αX,SeX≤0 Preludio(X)={
X,l'asse alfa,SeX>0SeX≤0
Qui alfa alfaα sono parametri appresi tramite backpropagation.
ELU tenta di combinare i vantaggi di ReLU e l'elaborazione degli input negativi. La sua espressione matematica è:
ELU ( x ) = { x , se x > 0 α ( ex − 1 ) , se x ≤ 0 testo{ELU}(x) ={X,SeX>0α(eX−1),SeX≤0 ELU(X)=

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]