моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
В этой статье подробно рассматривается развитие функций активации в глубоком обучении: от ранних сигмоидных функций и функций Тана до широко используемой серии ReLU и недавно предложенных новых функций активации, таких как Swish, Mish и GeLU. Проведен углубленный анализ математических выражений, характеристик, преимуществ, ограничений и применения различных функций активации в типовых моделях. Посредством систематического сравнительного анализа в этой статье обсуждаются принципы проектирования, стандарты оценки производительности и возможные будущие направления развития функций активации, а также предоставляются теоретические рекомендации по оптимизации и разработке моделей глубокого обучения.
Функция активации является ключевым компонентом нейронных сетей, который вводит нелинейные характеристики на выходе нейронов, позволяя нейронным сетям обучаться и представлять сложные нелинейные отображения. Без функции активации, какой бы глубокой ни была нейронная сеть, она, по сути, может представлять только линейные преобразования, что сильно ограничивает выразительные способности сети.
С быстрым развитием глубокого обучения разработка и выбор функций активации стали важными факторами, влияющими на производительность модели. Различные функции активации имеют разные характеристики, такие как плавность градиента, вычислительная сложность, степень нелинейности и т. д. Эти характеристики напрямую влияют на эффективность обучения, скорость сходимости и конечную производительность нейронной сети.
Целью этой статьи является всесторонний обзор эволюции функций активации, глубокий анализ характеристик различных функций активации и исследование их применения в современных моделях глубокого обучения. Мы обсудим следующие аспекты:
Посредством этого систематического обзора и анализа мы надеемся предоставить исследователям и практикам исчерпывающую справочную информацию, которая поможет им лучше выбирать и использовать функции активации при разработке моделей глубокого обучения.
Сигмовидная функция — одна из самых ранних широко используемых функций активации, ее математическое выражение:
σ ( x ) = 1 1 + e − x сигма(x) = frac{1}{1 + e^{-x}}σ(Икс)=1+е−Икс1
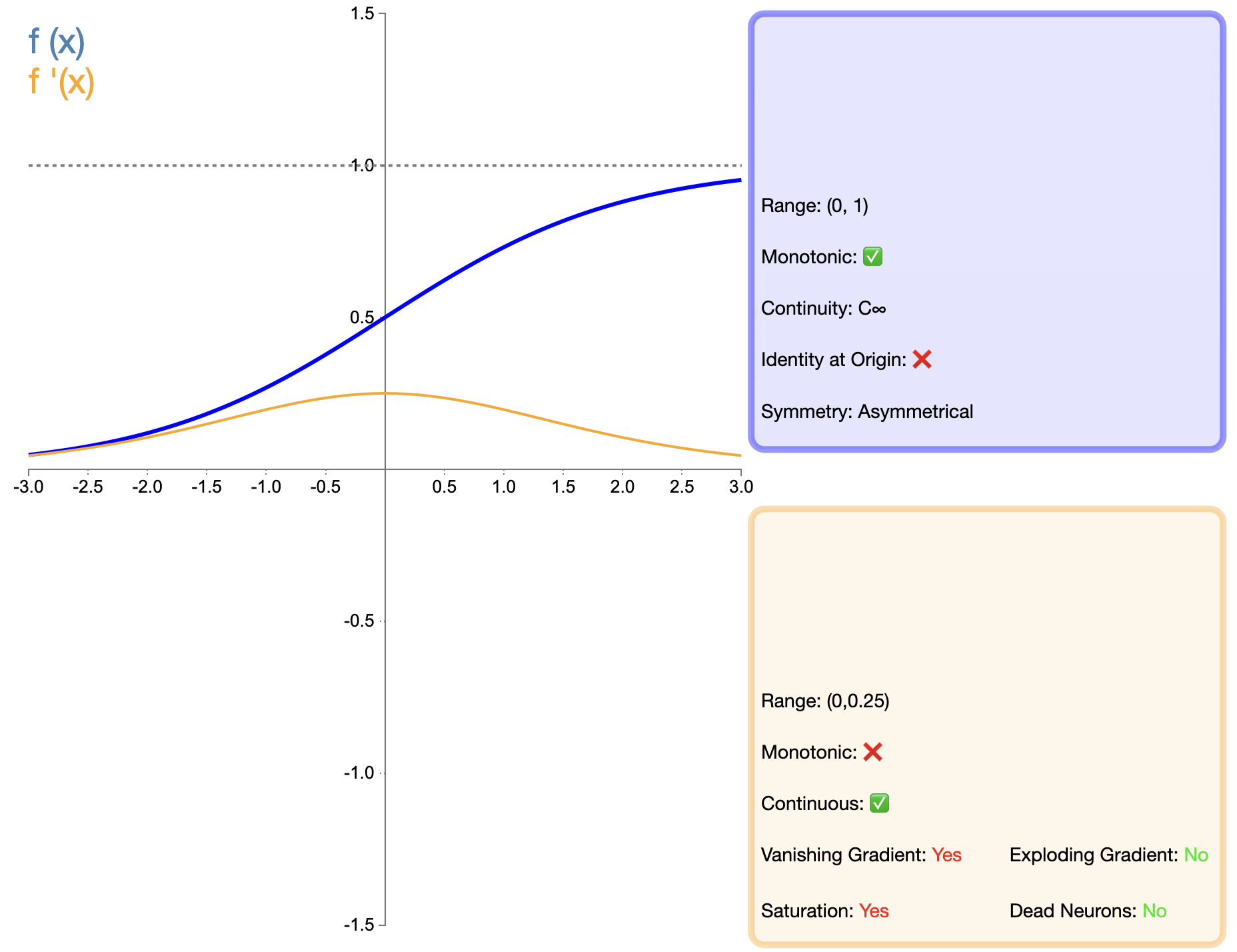
По сравнению с появившимися позже такими функциями, как ReLU, применение Sigmoid в глубоких сетях было сильно ограничено, главным образом из-за проблемы исчезающего градиента. Однако в некоторых конкретных задачах (например, двоичной классификации) сигмовидная диаграмма по-прежнему остается эффективным выбором.
Функцию Таня (гиперболический тангенс) можно рассматривать как улучшенную версию сигмоидальной функции, и ее математическое выражение имеет вид:
tanh ( x ) = ex − e − xex + e − x tanh(x) = frac{e^x - e^{-x}}{e^x + e^{-x}}танх(Икс)=еИкс+е−ИксеИкс−е−Икс
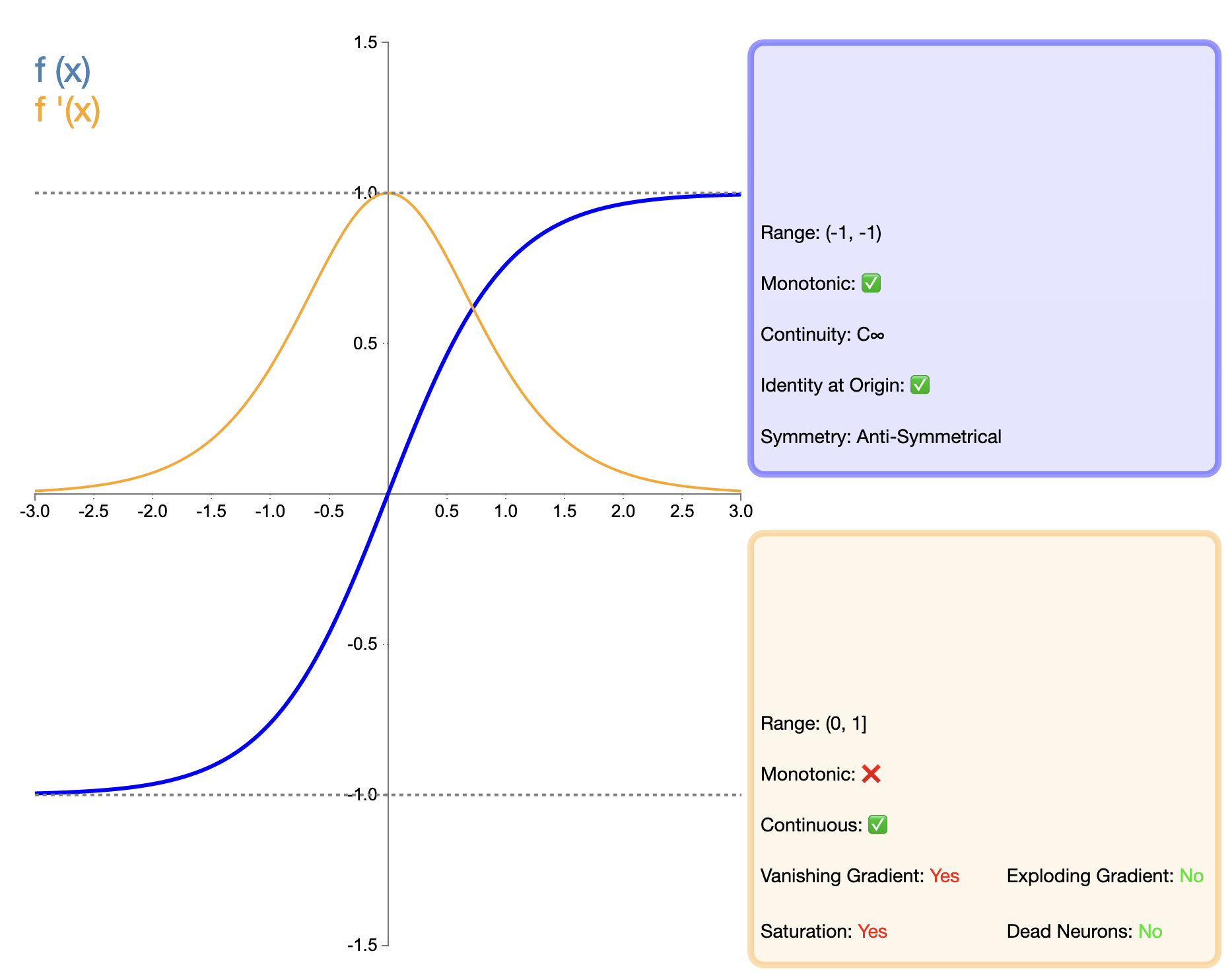
Функцию Таня можно рассматривать как улучшенную версию сигмовидной функции. Основное улучшение заключается в центрировании выходных данных по нулю. Эта функция позволяет Tanh работать лучше, чем Sigmoid во многих ситуациях, особенно в глубоких сетях. Однако по сравнению с появившимися позже такими функциями, как ReLU, у Tanh все еще есть проблема исчезновения градиента, что может повлиять на производительность модели в очень глубоких сетях.
Две классические функции активации, сигмовидная и Тан, сыграли важную роль на заре глубокого обучения, а их характеристики и ограничения также способствовали развитию последующих функций активации. Хотя во многих сценариях они были заменены обновленными функциями активации, они по-прежнему имеют свою уникальную прикладную ценность для конкретных задач и сетевых структур.
Предложение функции ReLU является важной вехой в развитии функций активации. Его математическое выражение просто:
ReLU ( x ) = макс ( 0 , x ) текст {ReLU}(x) = макс (0, x)РеЛУ(Икс)=Макс(0,Икс)
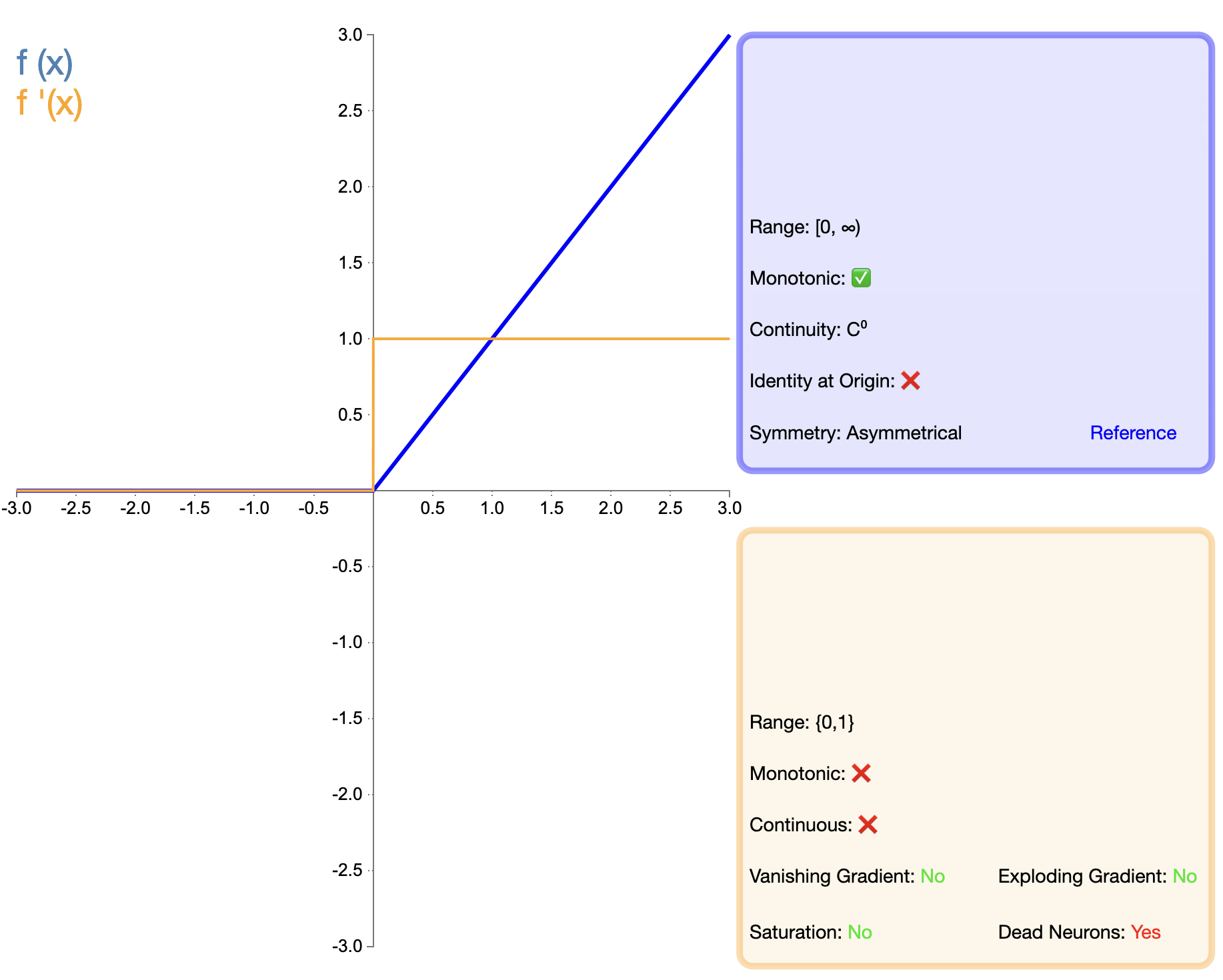
По сравнению с Sigmoid и Tanh, ReLU демонстрирует значительные преимущества в глубоких сетях, главным образом с точки зрения скорости обучения и уменьшения исчезновения градиента. Однако проблема «мертвого ReLU» побудила исследователей предложить различные улучшенные версии.
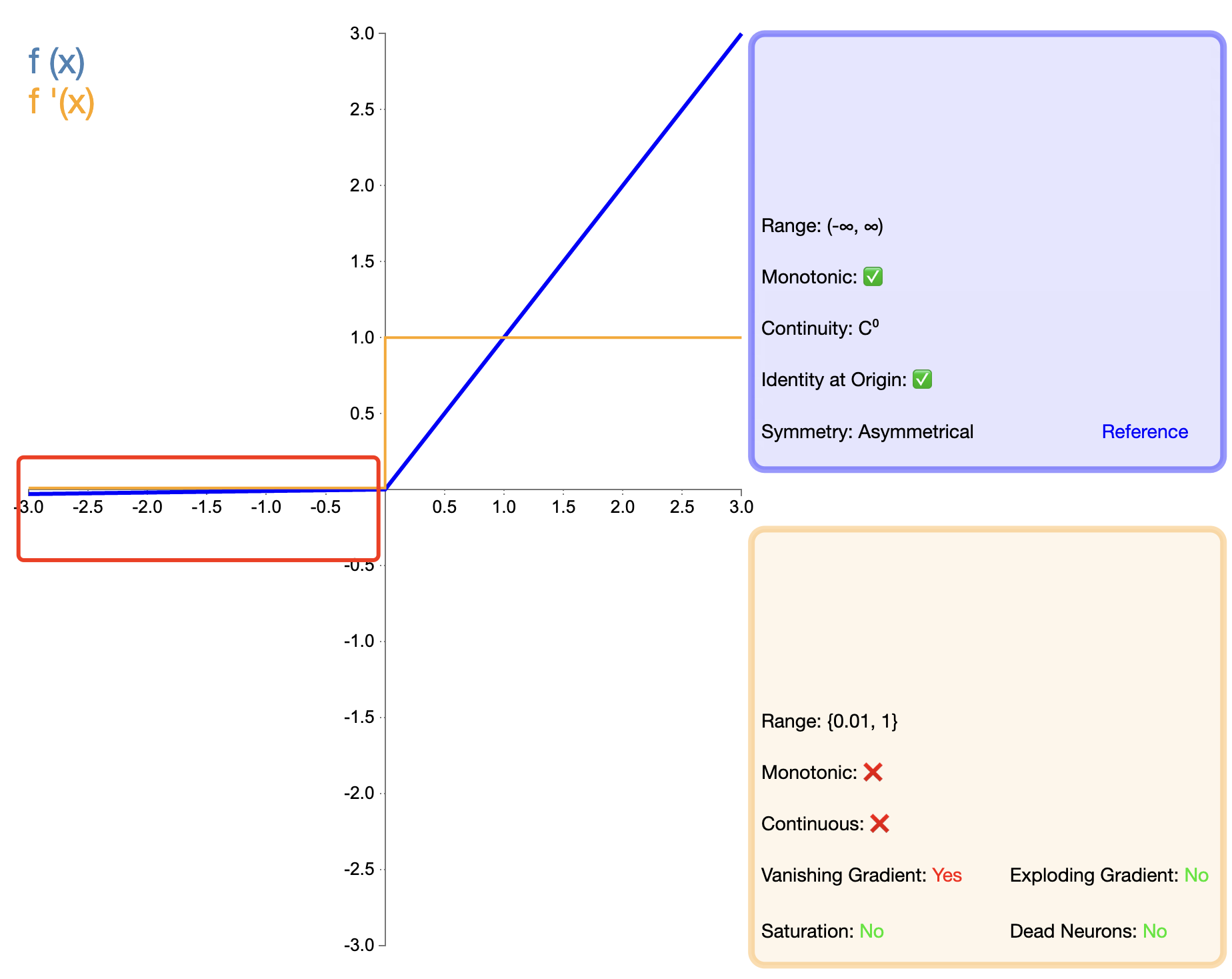
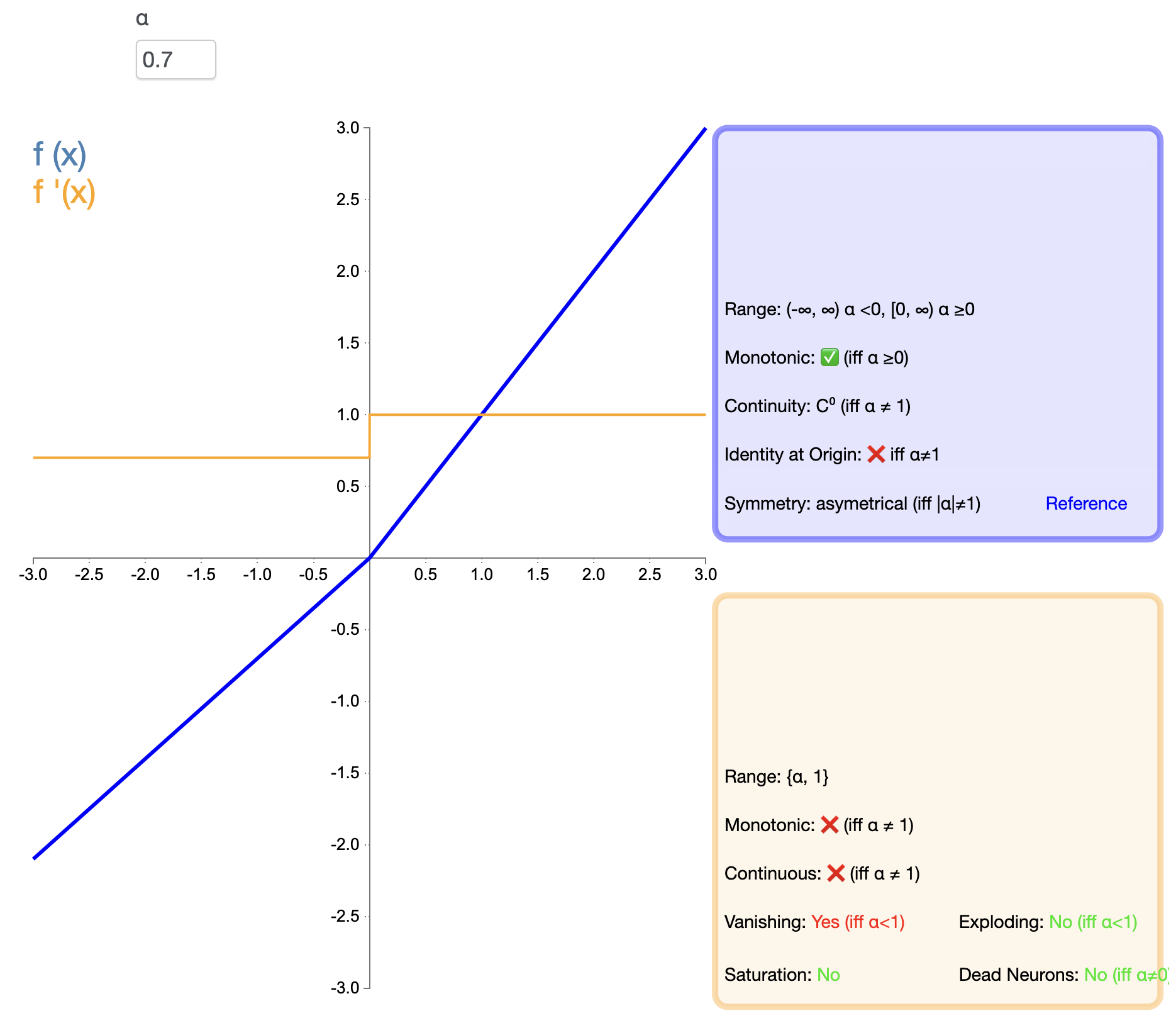
Для решения проблемы «смерти» ReLU был предложен Leaky ReLU:
Дырявый ReLU ( x ) = { x , если x > 0 α x , если x ≤ 0 текст{Дырявый ReLU}(x) ={Икс,еслиИкс>0αИкс,еслиИкс≤0 Дырявый ReLU(Икс)={
Икс,αx,еслиИкс>0еслиИкс≤0
в, α альфаα — небольшая положительная константа, обычно 0,01.
PReLU — это вариант Leaky ReLU, где наклон отрицательной полуоси является обучаемым параметром:
PReLU ( x ) = { x , если x > 0 α x , если x ≤ 0 текст{PReLU}(x) ={Икс,еслиИкс>0αИкс,еслиИкс≤0 ПРЕЛУ(Икс)={
Икс,αx,еслиИкс>0еслиИкс≤0
здесь α альфаα — это параметры, полученные посредством обратного распространения ошибки.
ELU пытается объединить преимущества ReLU и обработки отрицательных входных данных. Его математическое выражение:
ELU ( x ) = { x , если x > 0 α ( ex − 1 ) , если x ≤ 0 текст {ELU}(x) ={Икс,еслиИкс>0α(еИкс−1),еслиИкс≤0 ЭЛУ(Икс)=

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com