minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Este artigo revisa abrangentemente o desenvolvimento de funções de ativação no aprendizado profundo, desde as primeiras funções Sigmoid e Tanh, até a amplamente utilizada série ReLU, até as novas funções de ativação recentemente propostas, como Swish, Mish e GeLU. É realizada uma análise aprofundada das expressões matemáticas, características, vantagens, limitações e aplicações de várias funções de ativação em modelos típicos. Através de análise comparativa sistemática, este artigo discute os princípios de design, padrões de avaliação de desempenho e possíveis direções de desenvolvimento futuro de funções de ativação, fornecendo orientação teórica para a otimização e design de modelos de aprendizagem profunda.
A função de ativação é um componente chave nas redes neurais, que introduz características não lineares na saída dos neurônios, permitindo que as redes neurais aprendam e representem mapeamentos não lineares complexos. Sem uma função de ativação, não importa quão profunda seja uma rede neural, ela só pode representar essencialmente transformações lineares, o que limita bastante a capacidade expressiva da rede.
Com o rápido desenvolvimento da aprendizagem profunda, o design e a seleção de funções de ativação tornaram-se fatores importantes que afetam o desempenho do modelo. Diferentes funções de ativação possuem características diferentes, como fluidez de gradiente, complexidade computacional, grau de não linearidade, etc. Essas características afetam diretamente a eficiência do treinamento, velocidade de convergência e desempenho final da rede neural.
Este artigo tem como objetivo revisar exaustivamente a evolução das funções de ativação, analisar profundamente as características de várias funções de ativação e explorar sua aplicação em modelos modernos de aprendizagem profunda. Discutiremos os seguintes aspectos:
Através desta revisão e análise sistemática, esperamos fornecer uma referência abrangente para pesquisadores e profissionais para ajudá-los a selecionar e usar melhor as funções de ativação no design de modelos de aprendizagem profunda.
A função Sigmóide é uma das primeiras funções de ativação amplamente utilizadas e sua expressão matemática é:
σ ( x ) = 1 1 + e − x sigma(x) = frac{1}{1 + e^{-x}}σ(x)=1+e−x1
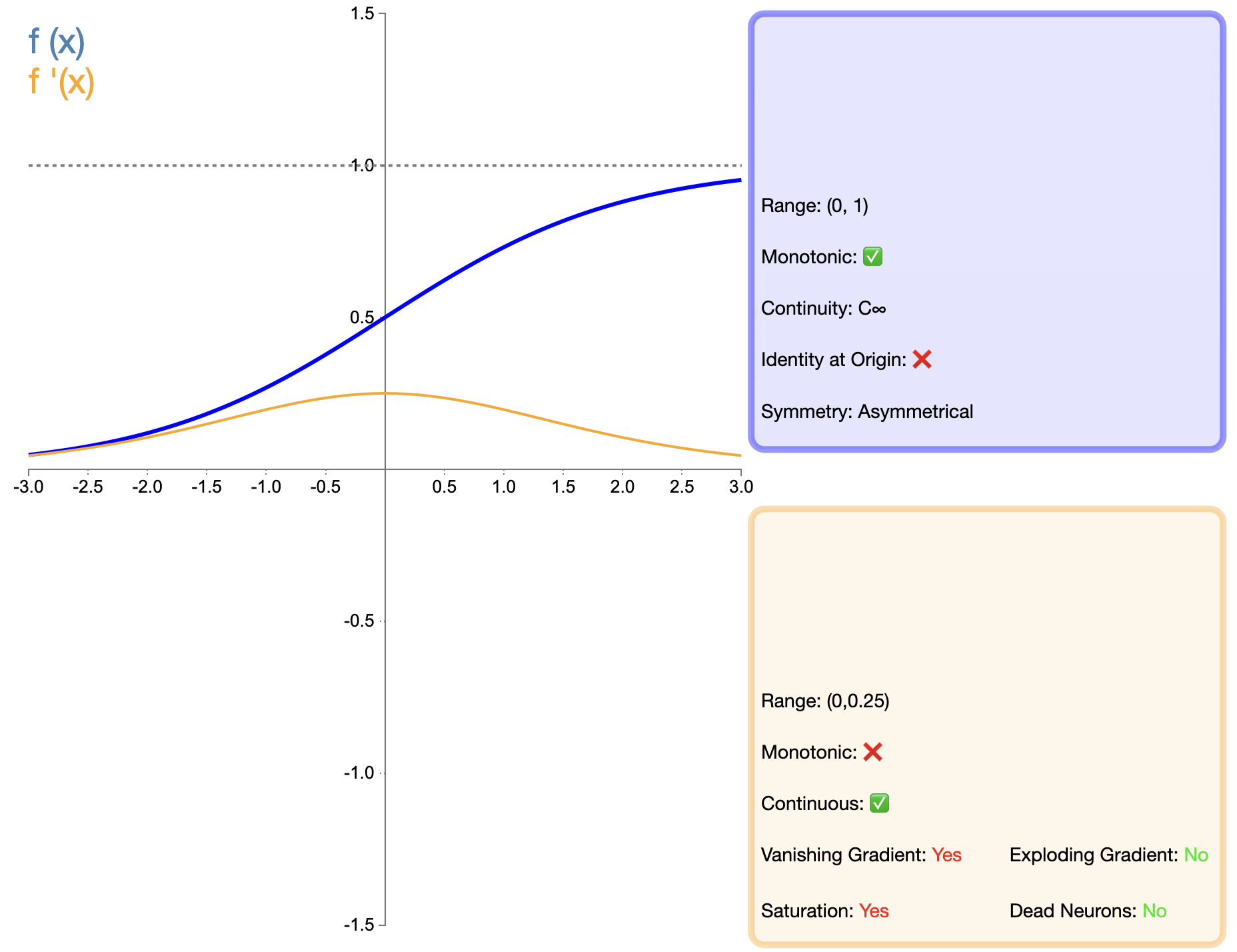
Comparado com funções como ReLU que apareceram mais tarde, a aplicação do Sigmoid em redes profundas tem sido bastante limitada, principalmente devido ao seu problema de gradiente evanescente. No entanto, em algumas tarefas específicas (como a classificação binária), o sigmóide ainda é uma escolha eficaz.
A função Tanh (tangente hiperbólica) pode ser considerada uma versão melhorada da função Sigmóide, e sua expressão matemática é:
tanh ( x ) = ex − e − xex + e − x tanh(x) = frac{e^x - e^{-x}}{e^x + e^{-x}}Tanh-tã ...(x)=ex+e−xex−e−x
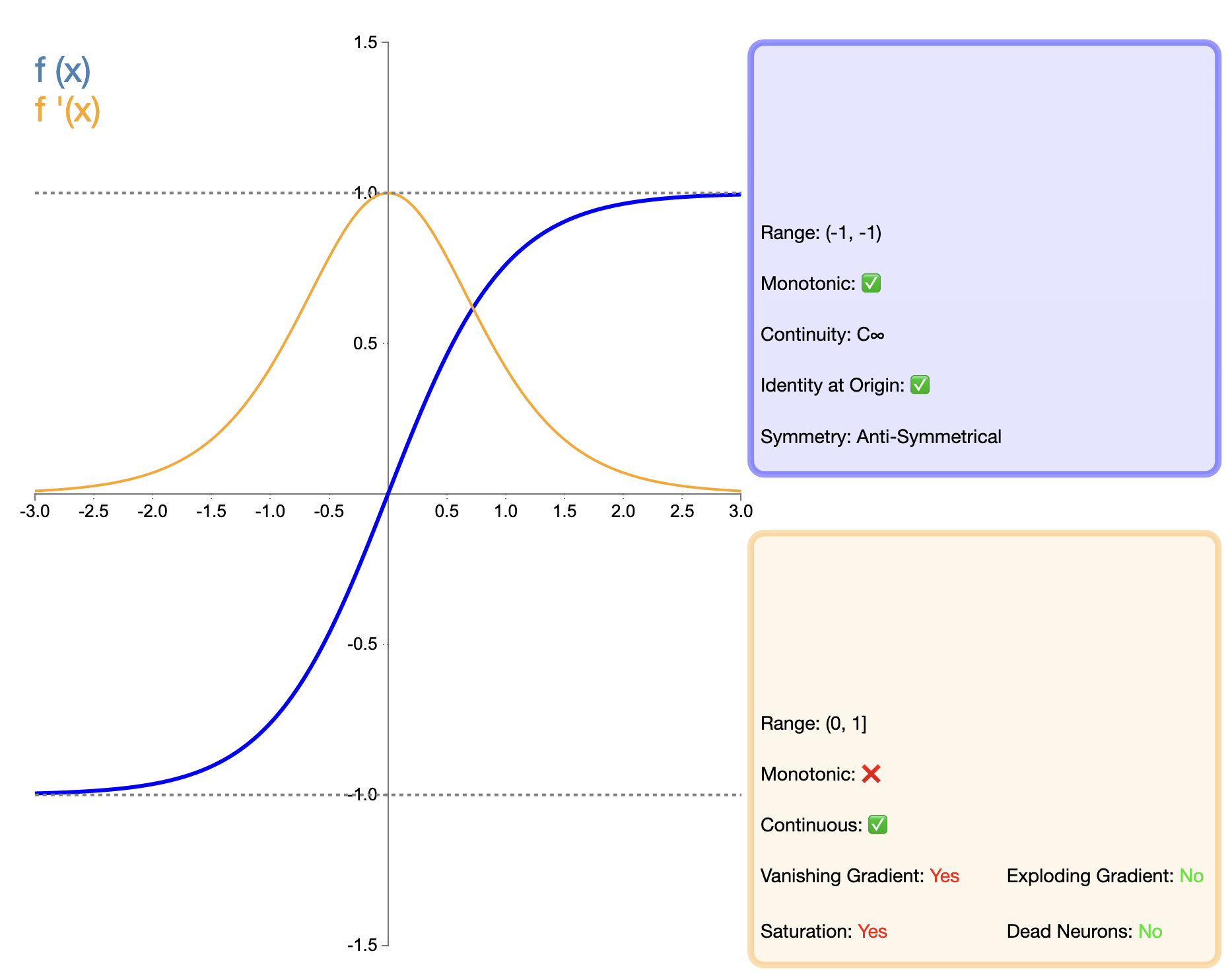
A função Tanh pode ser considerada uma versão melhorada da função Sigmóide. A principal melhoria reside na centralização em zero da saída. Esse recurso faz com que o Tanh tenha um desempenho melhor que o Sigmoid em muitas situações, especialmente em redes profundas. Porém, em comparação com funções como ReLU que apareceram posteriormente, Tanh ainda tem o problema do desaparecimento do gradiente, o que pode afetar o desempenho do modelo em redes muito profundas.
As duas funções de ativação clássicas, Sigmoid e Tanh, desempenharam um papel importante nos primeiros dias do aprendizado profundo, e suas características e limitações também promoveram o desenvolvimento de funções de ativação subsequentes. Embora tenham sido substituídas por funções de ativação atualizadas em muitos cenários, elas ainda têm seu valor de aplicação exclusivo em tarefas e estruturas de rede específicas.
A proposta da função ReLU é um marco importante no desenvolvimento de funções de ativação. Sua expressão matemática é simples:
ReLU ( x ) = máx ( 0 , x ) texto{ReLU}(x) = máx(0, x)ReLU(x)=máx.(0,x)
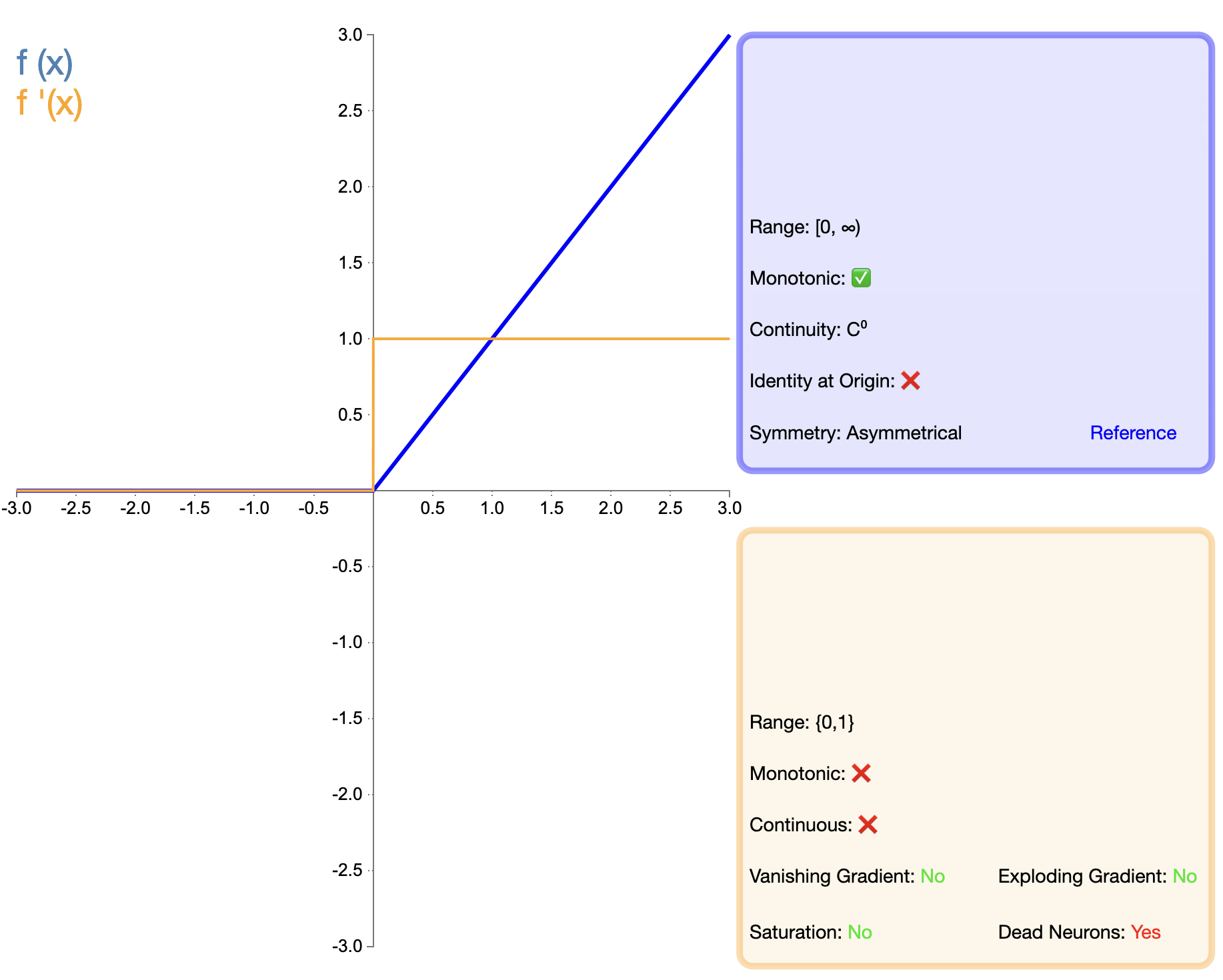
Comparado com Sigmoid e Tanh, ReLU apresenta vantagens significativas em redes profundas, principalmente em termos de velocidade de treinamento e mitigação do desaparecimento de gradiente. No entanto, o problema do “ReLU morto” levou os pesquisadores a propor várias versões melhoradas.
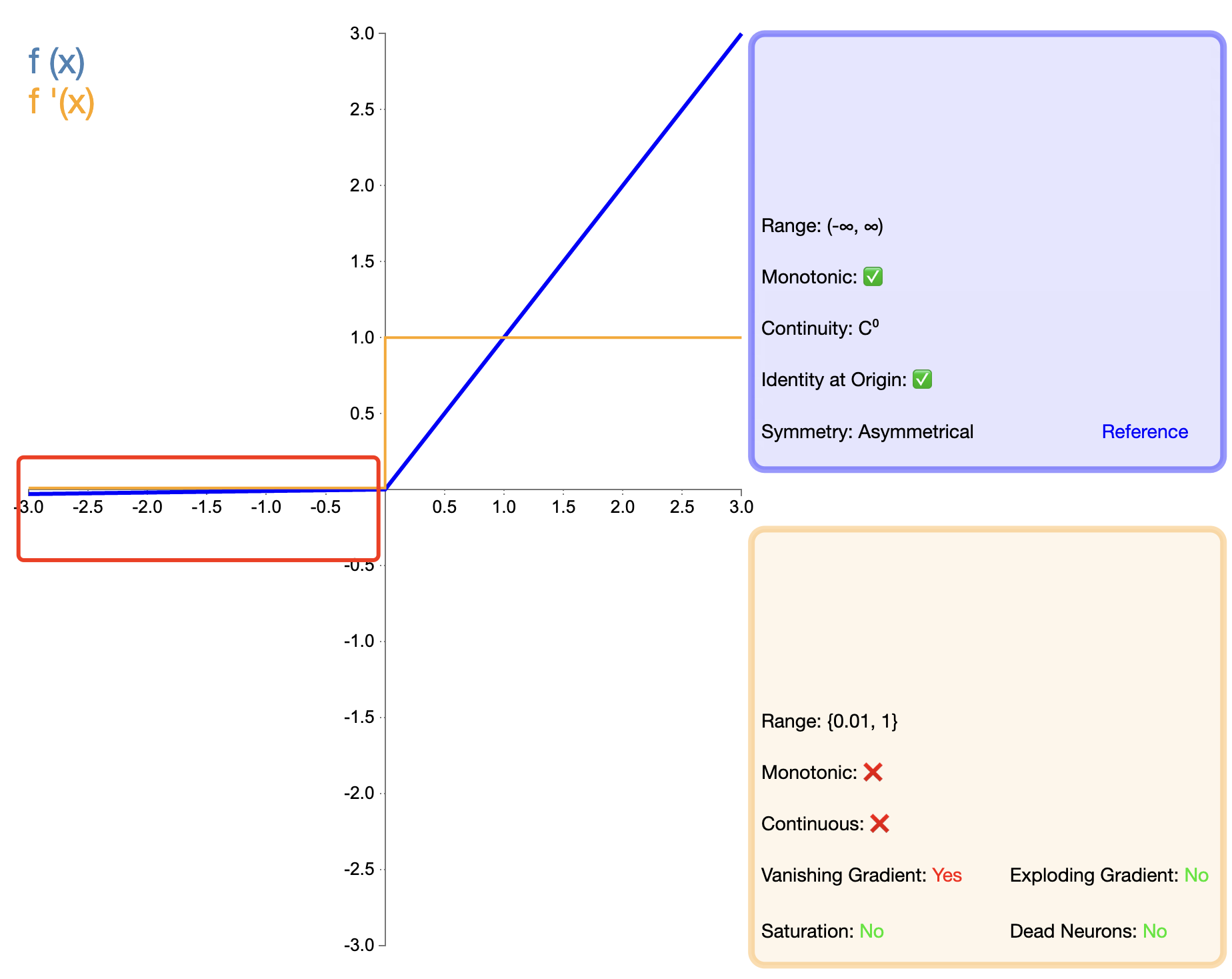
Para resolver o problema da "morte" do ReLU, o Leaky ReLU foi proposto:
ReLU com vazamento ( x ) = { x , se x > 0 α x , se x ≤ 0 texto{ReLU com vazamento}(x) ={x,sex>0αx,sex≤0 ReLU com vazamento(x)={
x,αx,sex>0sex≤0
em, α alfaα é uma pequena constante positiva, geralmente 0,01.
PReLU é uma variante do Leaky ReLU, onde a inclinação do semieixo negativo é um parâmetro que pode ser aprendido:
PReLU ( x ) = { x , se x > 0 α x , se x ≤ 0 texto{PReLU}(x) ={x,sex>0αx,sex≤0 PRELU(x)={
x,αx,sex>0sex≤0
aqui α alfaα são parâmetros aprendidos por meio de retropropagação.
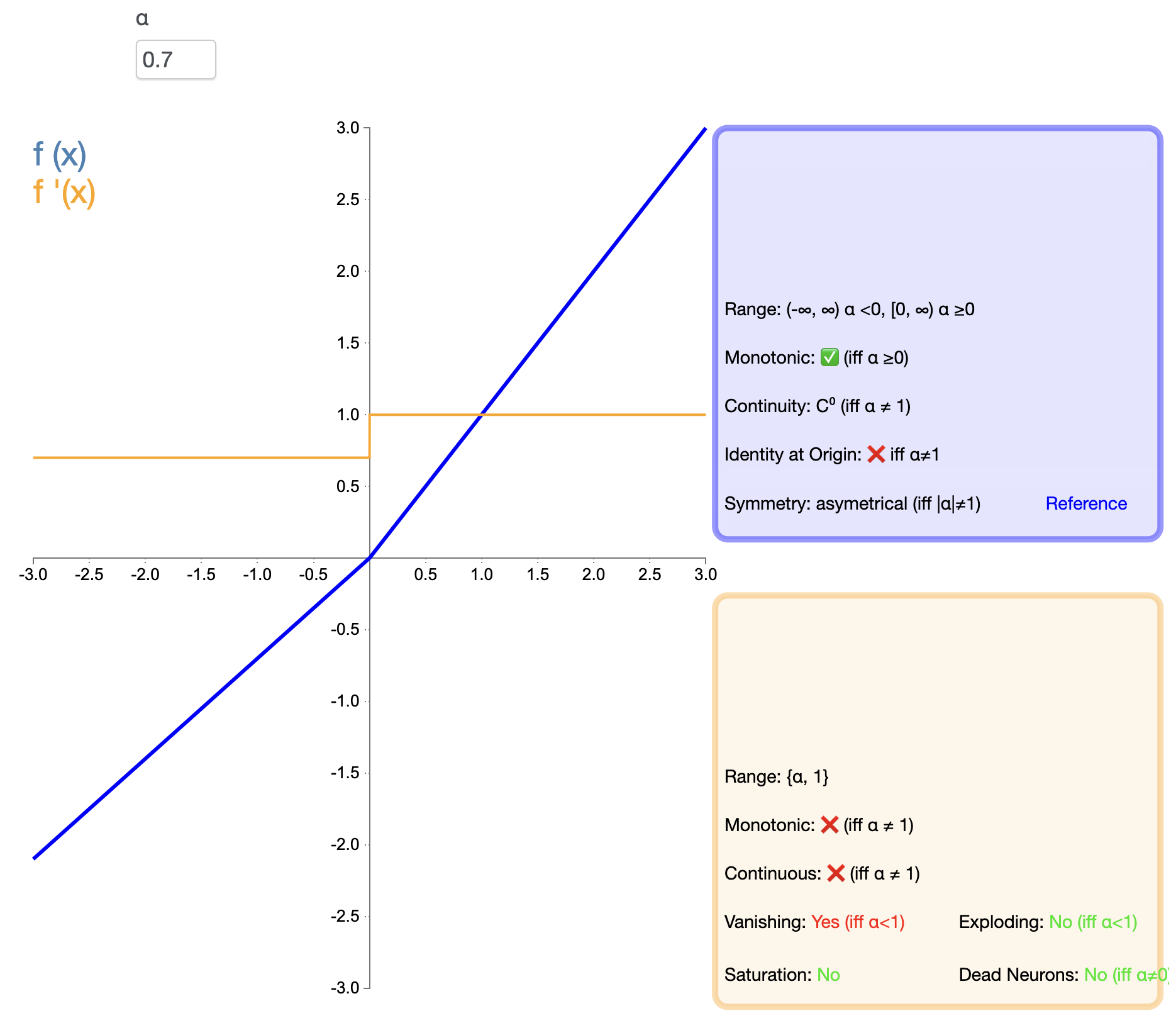
ELU tenta combinar as vantagens do ReLU e do processamento de entradas negativas. Sua expressão matemática é:
ELU ( x ) = { x , se x > 0 α ( ex − 1 ) , se x ≤ 0 texto{ELU}(x) ={x,sex>0α(ex−1),sex≤0 ELU(x)=

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]